


Amazon Kinesis and Apache Kafka are the most popular systems for handling real-time data streams. While both provide reliable real-time data intake and processing solutions, they have distinct differences. Kafka offers excellent performance and flexibility for large-scale deployments, while Kinesis delivers a fully managed solution with a close AWS integration.
Kinesis appeals to AWS-centric firms looking for ease of use and smooth scalability, while Kafka is well-suited for large enterprises requiring high performance and comprehensive integration capabilities. Businesses can choose the streaming platform that most closely matches their strategic objectives and operational needs by evaluating cost, convenience of use, scalability, and interaction with current systems.
Continue reading and learn the distinctions between Kafka and Kinesis to determine which is ideal for your real-time data streaming needs.
Key Takeaways:
Kinesis and Kafka both manage real-time data streams.
Kinesis offers a fully managed solution with AWS connectivity.
Kafka offers performance and flexibility for large-scale installations.
When deciding between Kafka and Kinesis, consider scalability, cost, usability, and integration variables.
Proactive planning and monitoring are recommended to tackle many difficulties, such as effective cluster management.
Apache Kafka vs. Kinesis: A Comparative Analysis
To determine whether Kafka or Kinesis is appropriate, it is crucial to consider their strengths, weaknesses, and suitable use cases. Organizations can maximize the value of their real-time data processing infrastructure by making an informed decision, weighing these considerations against their operational requirements and strategic goals.
Below is a comparison table that shows the main distinctions between Amazon Kinesis and Apache Kafka:
| Criteria | Apache Kafka | Amazon Kinesis |
|---|---|---|
| Provider | Apache Software Foundation | Amazon Web Services |
| Scalability | Kafka’s scalability can be determined by brokers and partitions. | Kinesis’ scalability can be determined by shards. |
| Integration | Works effectively with various systems. | Tight integration with the AWS ecosystem. |
| Cost | Kafka needs more engineering hours, which raises the total cost of ownership (TCO). | Kinesis offers a pay-as-you-go mode, leading to lower costs. |
| Community Supports | Strong community for open-source. | A fully managed solution supported by AWS. |
Here’s a brief discussion of each key feature:
- Scalability
- Kafka uses divisions among its brokers to scale. The throughput increases with the number of partitions—as a general rule, the throughput is 30k messages per second. Users can customize Kafka clusters by choosing the number of brokers and instance kinds, frequently requiring last-minute changes for best results.
- Kinesis scales via shards, each of which can write 1 MB or 1,000 records per second and read 2 MB or 5 transactions per second. This method, known as shard-based scaling, supports up to 1,000 PUT records per second. Additionally, it is easy to scale by adjusting the throughput by adding or removing shards.
- Integration
- Kafka is well known for its adaptability and smooth interaction with various platforms and systems. It provides APIs and connectors enabling seamless integration with processing systems, storage options, and data sources.
- Kinesis excels in its tight integration with the AWS ecosystem, providing seamless connectivity with other AWS services like Lambda, S3, Redshift, and CloudWatch. Those who have already invested in AWS may benefit from this close integration, making it easier for them to design, deploy, and manage their data streaming applications by using the entire range of AWS tools and services.
- Cost
- Although Kafka doesn’t require any software costs, developers must spend days setting up, configuring, deploying, and optimizing a Kafka infrastructure. Additionally, provisioning for on-premise or cloud infrastructure is required, increasing overall expenses.
- Kinesis has a pay-per-use pricing model and requires minimal initial setup. The cost of ingestion, or data-in, is $0.08 per gigabyte of data processed in an hour. The monthly storage cost is $0.10 per GB for up to seven days and $0.023 per GB after seven days. Enhanced fan-out retrievals are billed at $0.05 per GB per hour, whereas data retrieval (data-out) is paid at $0.04 per GB per hour.
- Community Supports
- Kafka has a robust open-source community that provides extensive resources, forums, and community-driven support. To solve problems, exchange best practices, and support the platform’s further development, users have access to many tutorials, documentation, and discussion boards.
- Since Kinesis is a fully managed service, AWS provides specialized support. Users can access various training materials, comprehensive documentation, and expert support services AWS provides. Although it does not have the same broad open-source community as Kafka, AWS support guarantees dependable help and direction for administering and maximizing Kinesis deployments.
The next section will explain Kinesis and Kafka in more detail, as well as their primary features, challenges, and tried-and-tested best practices.
Did You Know?
Over 80% of Fortune 100 businesses use and rely on Kafka.
What is Kafka? Understanding Real-Time Data Processing
Apache Kafka is an open-source distributed streaming platform designed for event-driven applications that require rapid data transmission. It functions as an append-only log, making it flexible for a wide range of use cases by enabling data to be written from numerous sources and read by multiple consumers.
Kafka’s architecture’s distributed, partitioned, and replicated features offer a solid basis for high-throughput, fault-tolerant, and low-latency data streaming. This makes Kafka ideal for real-time data input, processing, and delivery, supporting diverse use cases including log aggregation, event sourcing, and real-time analytics.
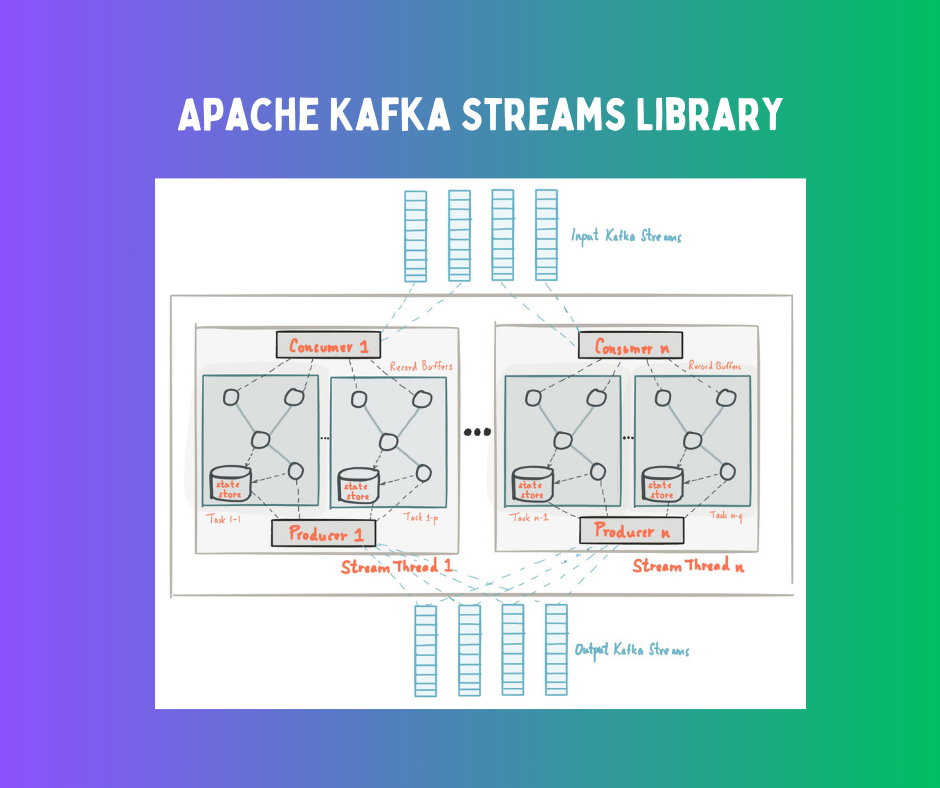
Kafka Key Features for Stream Processing
The key to Kafka’s capacity to deliver resilient and scalable data streaming is its publish-subscribe messaging architecture. Using topics, partitions, producers, consumers, and consumer groups, Kafka ensures fault tolerance and high availability while handling massive volumes of data in real time.
This architecture supports a wide range of use cases including, log aggregation and real-time analytics, making Kafka an effective platform for modern data-driven applications. Here are Kafka’s key features:
- Scalability: Kafka’s unmatched scalability makes it possible to expand without interruption by adding nodes. Choosing the right instance type and number of brokers is essential for Kafka cluster configuration to maximize performance. Although Amazon’s size guide provides recommendations, fine-tuning may be required depending on how throughput requirements change.
- Topics and Partitions: Partitions divide topics into ordered, immutable sequences of records, while topics serve as channels for data. This topology distributes data among several servers in a cluster, enabling fault tolerance and horizontal scalability, high throughput, and effective data processing.
- Message Retention: Messages can be retained in Kafka for a certain amount of time or until a log segment exceeds a size restriction. While size-based retention discards older messages when storage limitations are reached, preventing disk space overflow, time-based retention deletes messages after a predetermined amount of time.
- Replication: Kafka supports data replication for durability and fault tolerance. When creating a topic, you may specify a replication factor, which controls the number of copies of each partition kept across brokers. Replicating each writes to multiple brokers before acknowledgment ensures robust consistency and data accessibility even when a broker fails.
- Distributed Processing: Kafka’s distributed architecture efficiently handles large-scale data processing. Consumers scale horizontally to analyze data in parallel, while brokers manage and distribute data across partitions. Due to its high throughput, low latency, and fault tolerance, Kafka is an excellent choice for real-time analytics and data streaming.
- Real-Time Processing: Kafka is ideal for developing real-time data pipelines because its distributed messaging architecture allows data to be published and consumed instantly. These pipelines assist numerous real-time applications by facilitating seamless processing, analytics, and data storage.
- Fault Tolerance: Kafka is designed with built-in fault tolerance, it can withstand the loss of a node or system in a cluster. When a device fails, Kafka streams automatically restart the process to ensure data integrity and uninterrupted functioning.
- Data Durability: Using message replication, Kafka guarantees data durability, averting data loss even if the broker fails. Due to multiple copies of the data spread across brokers, data recovery is automatic and transparent, improving overall system resilience.
- Low Latency: Kafka excels at processing data streams with low latency—typically milliseconds or less. By utilizing data batching, compression, and segmentation methods, Kafka produces records with very low latency, allowing users to retrieve them quickly.
- Integration: Kafka Connect offers over 120 pre-built connectors that help provide wide integration capabilities. These connectors allow Kafka to be easily integrated with a wide range of third-party applications and data sources, increasing its adaptability and compatibility in various settings.
Kafka: Overcoming Challenges Through Effective Practices
Managing Apache Kafka comes with various challenges that require proactive planning and monitoring. Sustaining a healthy Kafka implementation involves strong performance monitoring, efficient cluster management, and data consistency. By addressing these obstacles, organizations can fully realize the promise of Kafka’s powerful real-time data processing capabilities.
Managing Cluster Nodes
The challenge in Kafka cluster management is maintaining good performance and availability by configuring, observing, and managing numerous nodes. As data volumes increase, additional cluster nodes might need to be added. Cluster nodes must be balanced to accommodate data loads effectively.
Best Practice: To monitor and dynamically rebalance clusters when additional nodes are added or data quantities increase, plan rebalancing jobs regularly or use automated tools.
Ensuring Data Consistency
It can be challenging to keep data consistent throughout a distributed system. To avoid data loss and guarantee fault tolerance, Kafka must ensure that data is reliably duplicated across nodes. Replication factors must be carefully managed, and the replication process must be closely watched.
Best Practice: Set alerts for replication problems and use tools to monitor replication slowness. Check replication settings frequently and adjust according to desired fault tolerance levels and data criticality.
Monitoring Performance
Kafka’s performance monitoring is essential for locating obstructions and guaranteeing efficient operation. Metrics including throughput, latency, and resource usage are monitored. If effective monitoring isn’t in place, problems may go unreported until they affect performance or fail.
Best Practice: Configure alerts and dashboards to regularly monitor essential indicators. Put in place automatic scripts to gather and examine logs, allowing for the early detection and correction of performance problems. Review performance statistics often to optimize setups and avoid bottlenecks.
Failure Recovery
While standby replicas and state stores increase redundancy and high availability, there is no effective way to restore the state if a complete system failure happens swiftly. Although it can take a while, replaying recordings from changelog topics is necessary for restoration.
Best Practice: Boost Kafka’s failure recovery with incremental snapshots to shorten state restoration times, standby replicas for rapid node failure recovery, and optimized changelog configurations. To guarantee quicker healing and increased resistance, keep an eye on and maintain these components regularly.
What is Kinesis? Delving into Real-time Data Streaming
Amazon Kinesis was created to manage real-time data streaming. Its architecture facilitates real-time data processing through continuous ingestion, storage, and analysis of data streams. One notable feature of Kinesis is its capacity to scale independently in response to workload demands.
Kinesis can automatically adapt the number of shards to match the increased throughput as data volume grows, guaranteeing consistent performance without intervention. Its tight integration with other AWS services, like Amazon S3 and AWS Lambda, allows users to create complex real-time data processing and analytics pipelines using the broader AWS ecosystem.
Learn more about Amazon Kinesis’ key features, challenges, and best practices in the following section.
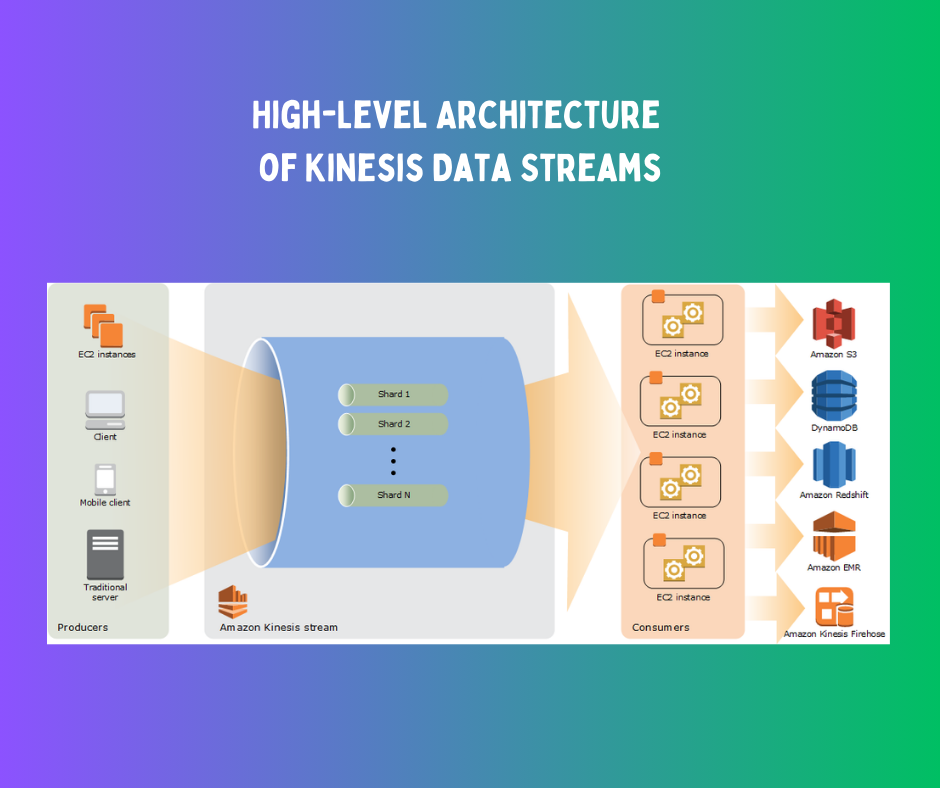
Kinesis’ Key Features for Seamless Real-Time Data Handling
Kinesis has several vital features that allow for real-time data processing, transformation, and enrichment:
Superior Availability and Durability: Provide complete data loss prevention by synchronously replicating streaming data across three Availability Zones (AZs) in an AWS Region and keeping it for up to 365 days.
Low Latency: Reduce latency by sending streaming data in as little as 70 milliseconds from collection to numerous real-time analytics apps, Amazon Managed Service for Apache Flink, or AWS Lambda.
Data Streams: Kinesis Data Streams allow for real-time data ingestion and storage. Users can establish data streams to collect, process continually, and store data records.
Data Firehose: Data Firehose is a tool for transforming and delivering data in real time. It can capture streaming data, transform it using AWS Lambda functions, and load it into destinations like Amazon S3, Amazon Redshift, and Amazon Elasticsearch Service, ensuring its seamless connection with other AWS services.
Data analytics: Kinesis Data Analytics uses SQL queries to provide real-time analytics on streaming data. As data is consumed, users can process and analyze it to produce instantaneous insights and useful information.
Mastering Kinesis: Overcoming Typical Challenges with Tried-and-Tested Best Practices
Even with its extensive capabilities, Kinesis also has several drawbacks:
Handling Data Shards
Setting up and maintaining data shards may be challenging. To match the velocity of data ingestion, users must balance the number of shards while avoiding under- or over-provisioning, which can affect costs and performance.
- Best Practice: To maximize performance and minimize costs, periodically check the rate of data intake and modify the number of shards. You may use AWS Auto Scaling to modify shard capacity according to traffic patterns dynamically.
Configuring Data Retention
Establishing suitable timeframes for data retention is critical. Extended retention periods raise the storage expense, even if they can yield more historical data for analysis.
- Best Practice: Use Amazon CloudWatch to monitor important data points, including read/write throughput, shard iterator age, and incoming data volume. This facilitates the identification of performance bottlenecks and the making of well-informed scaling and configuration modification decisions.
Cost Optimization
Keeping track of Kinesis expenses can be challenging. To ensure their use is economical, users need to consider the costs of data processing, storage, and ingestion.
- Best Practice: Implement cost optimization ideas into practice by reducing storage requirements through data transformation, compressing data before ingestion, and establishing suitable retention durations. Examine and evaluate usage trends regularly to save costs.
Conclusion
When choosing between Kafka and Kinesis, users must carefully consider their particular use cases, requirements, and preferences. Each platform has unique features and advantages that could match different business requirements.
Making an informed choice requires exhaustive assessments, testing, and benchmarking. Users can select the platform that best meets their unique requirements by carefully weighing variables like cost, ease of use, scalability, and interface with current systems. This ensures optimal performance and efficiency in their data processing and streaming workflows.
FAQs on Kafka vs. Kinesis
Which is better, Kafka or Kinesis?
Choosing the ideal data streaming system may depend on available funds, engineering culture, and organizational resources.
Does Netflix use Kafka or Kinesis?
Since 2013, Netflix has relied on Kinesis Data Streams as a crucial component of its big data architecture for processing real-time streaming.
Does AWS use Kafka?
AWS’ Amazon MSK provides the most readily available, safe, and compatible fully managed service for Apache Kafka.

