


At Edge Delta, our backend processes millions of logs, metrics, and traces every minute, continuously transforming raw data into actionable insights for our customers. Naturally, handling this at such a massive scale while ensuring data accuracy and supporting additional processing requirements is no easy feat.
A key piece of our backend architecture is our ingestion layer, which is responsible for initiating and ensuring the completion of the various processing requirements that arise. There were a number of different challenges we needed to overcome to create a robust, efficient ingestion layer that’s able to compete with anything else on the market. In this blog post, we’ll discuss the difficulties we faced when building our ingestion layer — handling 250,000 entries per second on average (with spikes), meeting exactly-once processing requirements, performing real-time and batch processing simultaneously, and supporting metering — and how we overcame them with a carefully designed, stateless architecture.
The Problem: Scaling Ingestion with Complex Requirements
When we set out to build our ingestion layer, we encountered multiple interconnected challenges:
- High and Fluctuating Data Volumes
Normal loads reach 250,000 log and metric entries per second, but surges during peak periods push this number significantly higher. The system needed to scale seamlessly to handle these fluctuations without introducing delays.
- Exactly-Once Processing
Logs and metrics are critical for customer observability, so ensuring zero data loss via exactly-once processing was a non-negotiable requirement. The ingestion layer had to handle retries gracefully without duplicating or losing data.
- Real-Time and Batch Processing
Some data needed to be pushed to Kafka in real time for immediate analysis, while the rest had to be batched and stored in a database. Achieving this dual-mode processing without sacrificing performance or consistency was a significant challenge.
- Metering for Customer Insights
As part of our ingestion layer, we needed to calculate the ingested data size per customer for usage metering. This introduced additional processing complexity while maintaining throughput and accuracy.
- Cost Efficiency with Spot Instances
Keeping operational costs low was critical, and leveraging AWS spot instances offered a cost-effective solution. However, since spot instances can be terminated by AWS at any time, we needed to utilize them carefully to tolerate interruptions without data loss.
The Solution: A Robust and Stateless Ingestion Layer
To address these challenges, we designed a stateless ingestion layer that leverages AWS S3, SQS, and other tools to achieve scalability, accuracy, and efficiency.
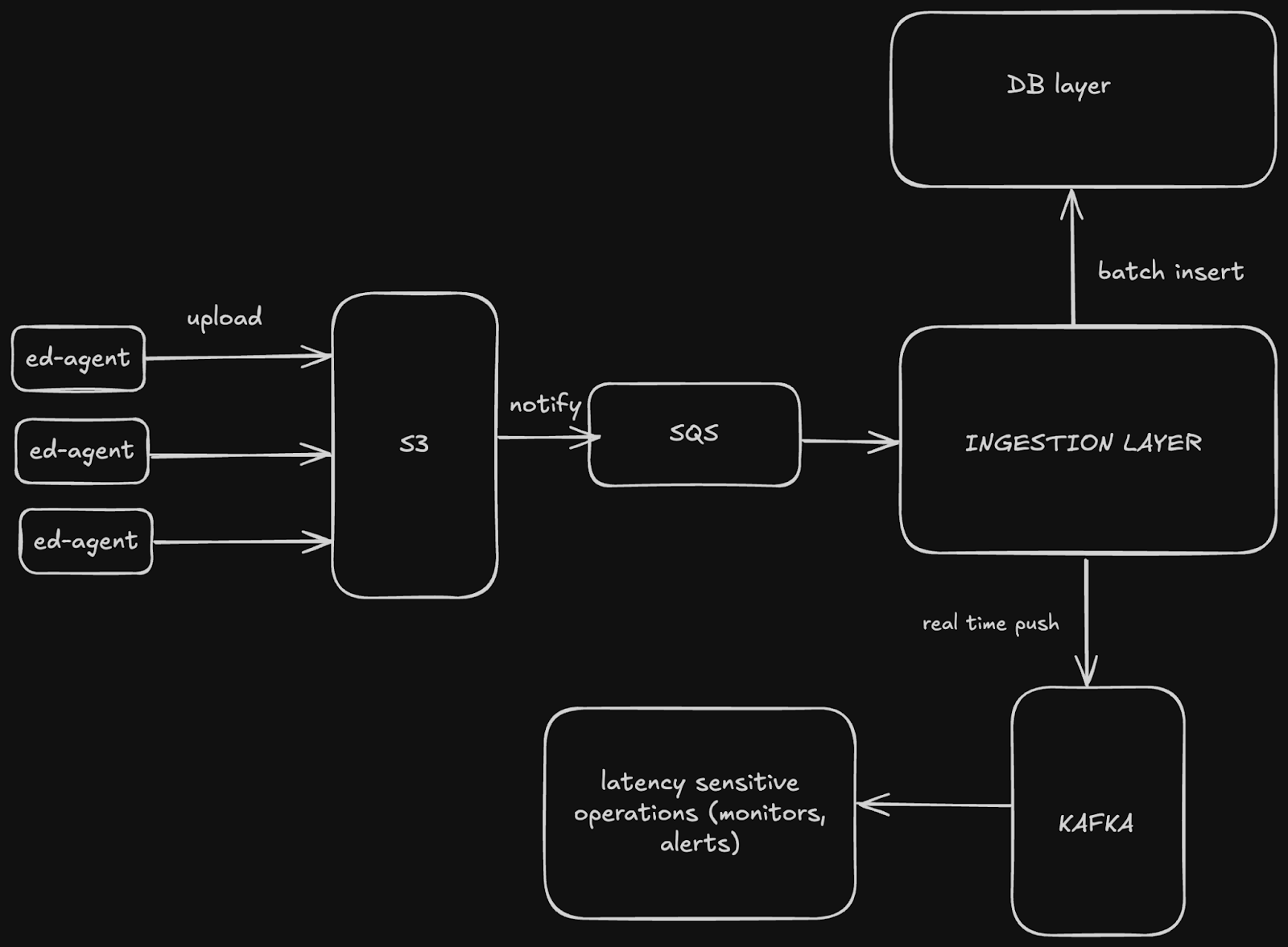
Architectural diagram of Edge Delta’s backend, with our new stateless ingestion layer
Here’s how we tackled each problem:
- Stateless, In-Memory Processing for Cost Efficiency
A core design decision was to make the ingestion layer stateless. Each instance processes files entirely in memory, handling each S3 file independently based on metadata from SQS. This stateless design provides several key advantages:
- Resilience to Failures: If a spot instance is terminated by AWS, there’s no loss of critical state. A new spot instance can pick up where the old one left off by reprocessing the SQS message.
- Seamless Scaling: Stateless instances can be added or removed dynamically, making it easy to scale the system up or down.
- Cost Efficiency with Spot Instances: Since processing happens entirely in memory and does not rely on shared state, AWS spot instances—which are significantly cheaper than on-demand instances—can be used confidently. Spot instances can be preempted, but statelessness ensures that processing is not disrupted.
This design dramatically reduces costs while maintaining reliability, as interrupted spot instances can be replaced without losing data.
- Scaling for High and Fluctuating Volumes
The ingestion layer is built as a stateless and horizontally scalable service. Incoming data flows through Amazon SQS, which serves as a decoupling mechanism between S3 uploads and our ingestion service. Here’s how it works:
- SQS as a Buffer: Incoming data is written to S3, and SQS notifications trigger processing. SQS gracefully handles surges in workload, ensuring no data is dropped even during times of peak traffic.
- Auto-Scaling: Statelessness allows us to dynamically scale the ingestion layer by spinning up additional instances when workloads increase.
By combining these elements, our ingestion layer can handle fluctuating data volumes seamlessly.
- Ensuring Exactly-Once Processing
Our ingestion layer ensures that exactly-once processing is achieved by carefully tracking the state of each SQS message and its corresponding S3 file. Here’s how:
- Idempotent Processing: Each SQS message is tied to a unique S3 file key. This ensures that even if a message is retried (due to network issues or instance failure), duplicate processing is avoided.
- Atomic Batching: Data is transformed, batched, and uploaded to the database in atomic transactions. If an error occurs during this step, no partial data is committed, ensuring consistency.
By designing for idempotency and atomic operations, we meet the critical need for exactly-once processing.
- Real-Time and Batch Processing
To handle the dual requirements of real-time and batch processing, the ingestion layer splits incoming data into two pathways:
- Real-Time Path: A subset of data is immediately pushed to Kafka for real-time analysis. This supports features like live dashboards and alerts.
- Batch Path: The same data is transformed and batched for efficient storage in the database.
This architecture ensures that real-time insights are delivered without compromising the efficiency of database storage.
- Metering for Customer Insights
Calculating ingested data size per customer is critical for metering and billing purposes. This is achieved by:
- Tagging Data by Customer: Metadata for each log or metric entry includes the customer identifier.
- Real-Time Size Calculation: During processing, the size of each ingested entry is aggregated in memory, and periodic updates are sent to a central metering service.
This feature is integrated into the ingestion pipeline without impacting throughput, ensuring customers receive accurate usage insights.
Results: A High-Performance Ingestion Layer
Here are the results we achieved after deploying this system into production:
Key Highlights (Performance and Benchmark Metrics) of Edge Delta’s Ingestion Layer
When we set out to build our ingestion layer, there were a few key metrics we aimed to optimize – scalability, error rate, cost savings, real-time processing latency, batch throughput, fault tolerance, and recovery time – each of which play a crucial role in ensuring data is efficiently and correctly processed. Here’s a breakdown of each metric and how our ingestion layer design accounts for it:
Scalability refers to handling thousands of entries every second — or millions per minute at peak — thanks to stateless, horizontally scalable services. Our ingestion layer handles fluctuating workloads seamlessly, maintaining steady throughput of 250,000 entries per second during normal operations and scaling dynamically for spikes.
Error Rate refers to the proportion of workloads which the ingestion layer fails to properly process. Error rate is minimized with automatic retries and exactly-once processing guarantees. Any transient failures are self-corrected without duplicating data. In terms of reliability, our ingestion layer ensures exactly-once processing, even under failure scenarios, with no duplicated or lost data.
Real-Time Processing Latency refers to the processing duration for data required for real-time operations (monitoring, alerting, etc). Our ingestion layer ensures all latency-sensitive operations receive the necessary data via real-time pushing into Kafka.
Batch Throughput refers to the amount of data shipped into our backend database per unit time. Ensuring atomicity and optimizing workloads via AWS spot instances results in tens of GB sent into our database per hour with vanishingly few errors.
Fault Tolerance / Recovery Time refers to the time between when an operation experienced a failure and when the operation continues running as expected. With our stateless design, we experience a near zero impact whenever an error occurs, as we can easily scale up the ingestion layer to replace the failed workload in an instant.
Cost Savings refers to the amount of money we saved after migrating to our new ingestion layer architecture. Leveraging AWS spot instances reduced compute costs by up to 70% without sacrificing reliability. This result stems from using AWS spot instances, where stateless processing allows for seamless replacement of preempted instances.
Here’s how our finished ingestion layer architecture performed in each metric:
| Metric | Value/Impact | Notes |
|---|---|---|
| Scalability | Hundreds of entries/second on average (with ability to handle spikes) | Stateless design + auto-scaling for burst handling |
| Error Rate | < 0.01% | Self-corrected automatically via retries (exactly-once model) |
| Cost Savings | Up to 70% cost reduction | Uses AWS spot instances for cost efficiency |
| Real-Time Processing Latency | Sub-second for critical data | Driven by immediate ingest to Kafka |
| Batch Throughput | Tens of GB/hour into DB | Optimized with atomic batching operations |
| Fault Tolerance/Recovery Time | Near-zero impact | Statelessness allows quick instance replacement |
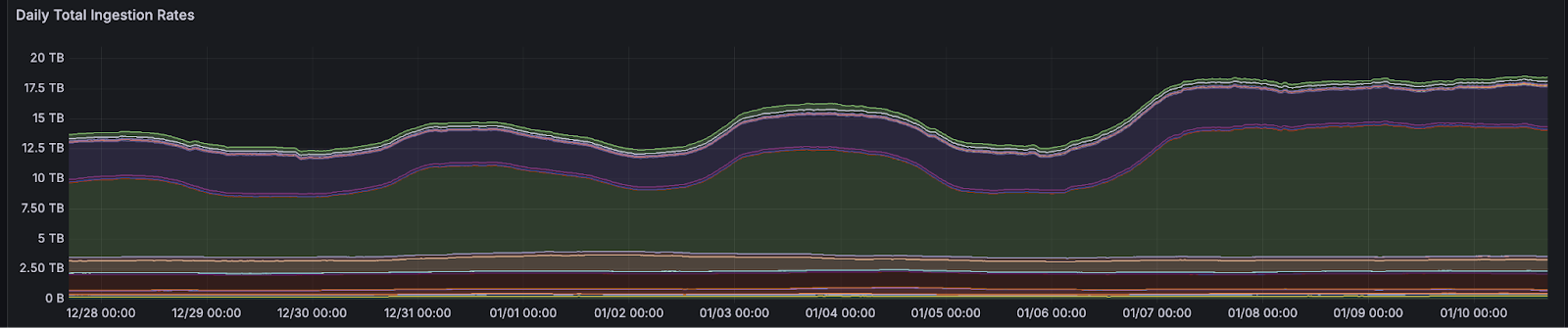
Daily ingestion rate fluctuations
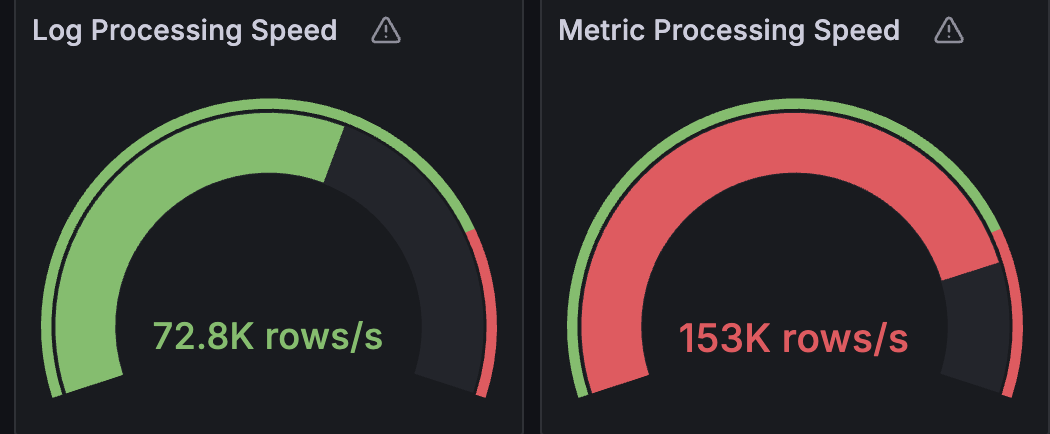
Real-time ingestion speed
Conclusion
Building a robust ingestion layer for large-scale data processing was no small task, and while this solution meets our current needs, it opens the door to even more possibilities. How could this architecture evolve further to support additional workloads or optimizations? Stay tuned for a deeper dive into what’s next in Part 2.
In the meantime, if you want to play around with our dashboarding features, be sure to check it out in our free-to-use playground. And if you’re interested in learning more about Edge Delta, start a free trial!



