Demos
Standardize Cisco ASA Logs on OCSF with Edge Delta Security Data Pipelines
•2:54

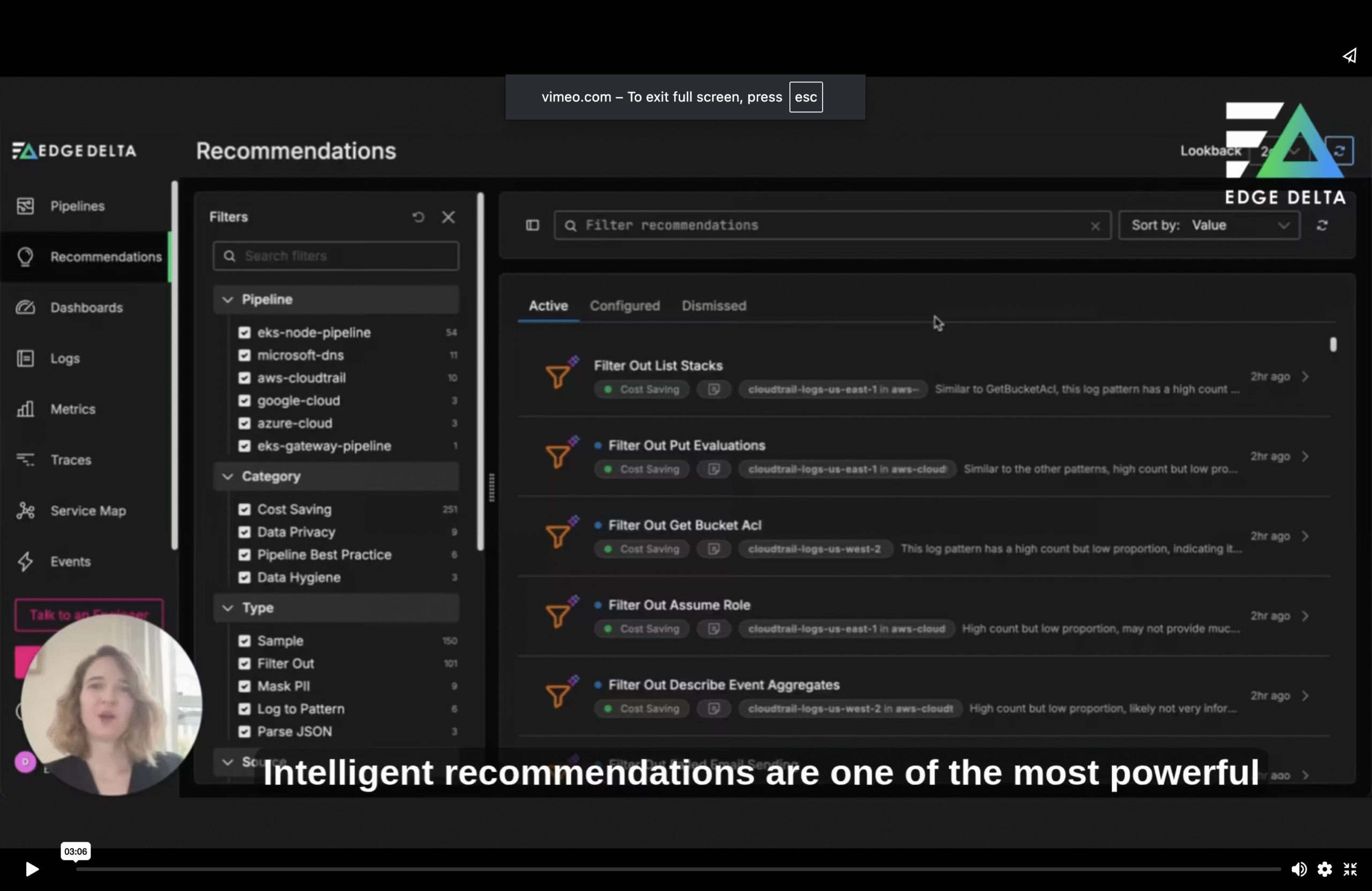
Extract metrics from your log data, group together similar events, and more. Edge Delta’s processors automatically analyze your log data as it’s collected. This feature gives you team real-time insights to streamline monitoring and troubleshooting processes.