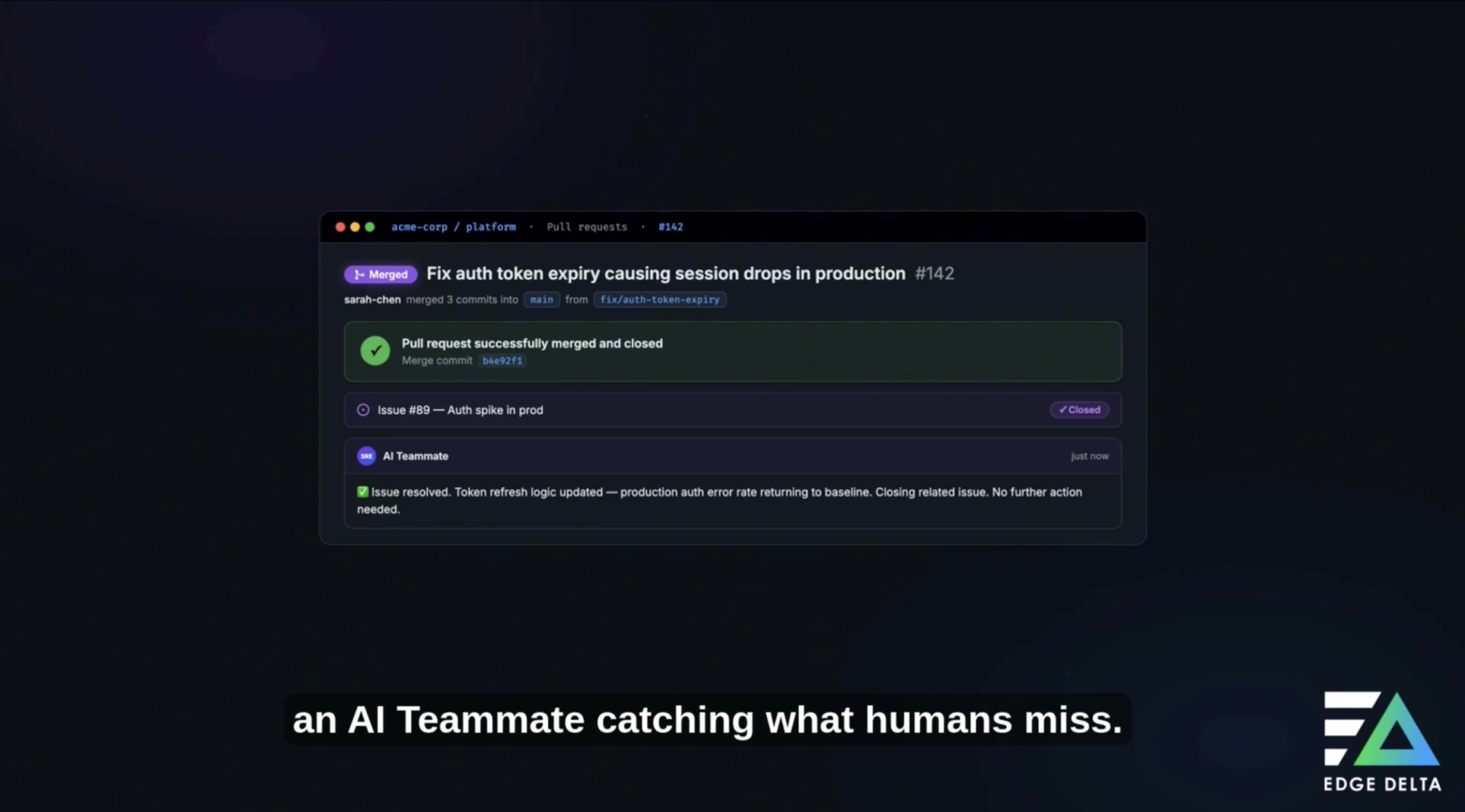
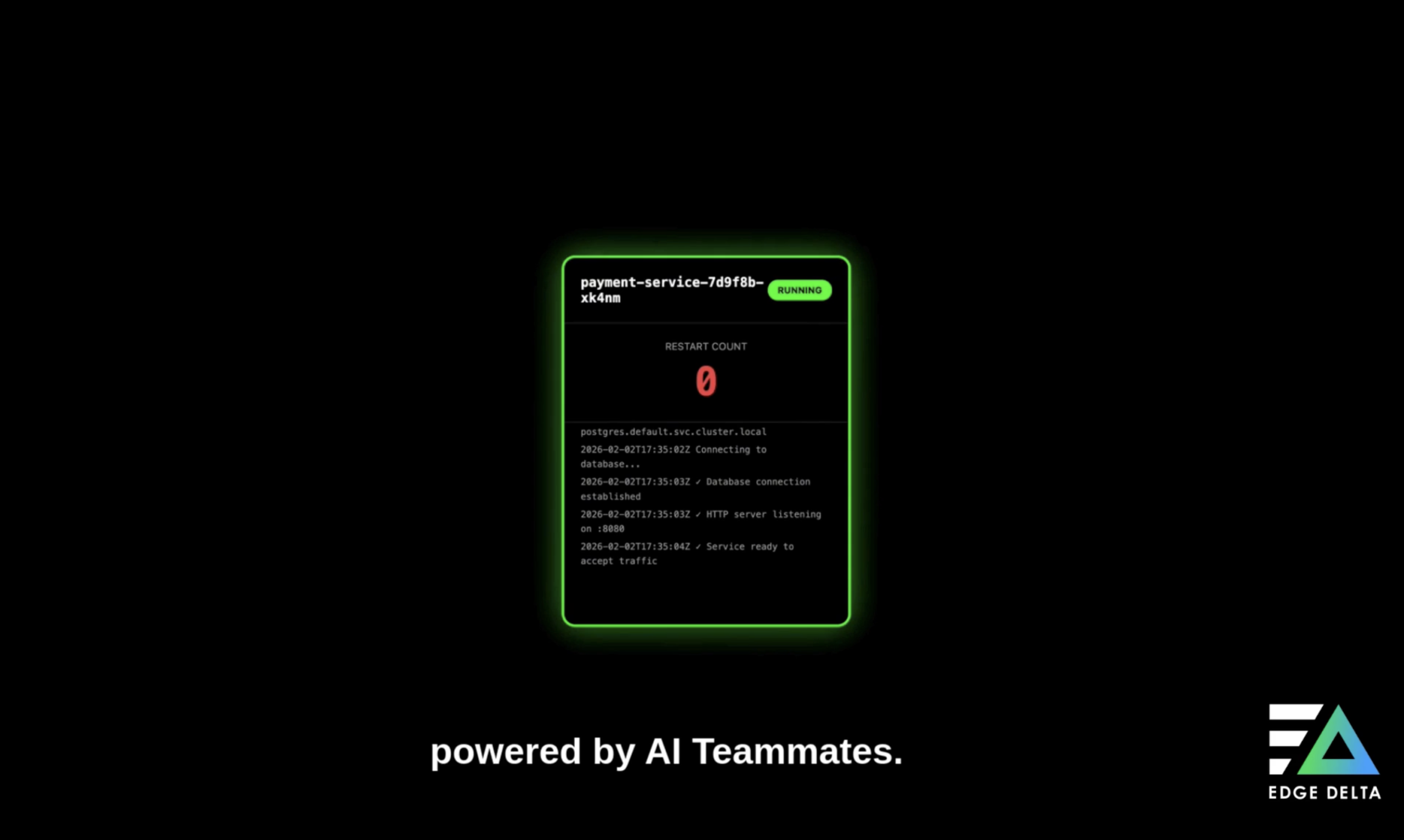
Events

Recently, we launched Visual Pipelines – a single, point-and-click interface to manage your observability pipelines.<br /> <br /> – Different use cases for Visual Pipelines, including building, testing, and monitoring pipelines<br /> – How the feature will drive developer self-service and autonomy<br /> – What’s next for the Edge Delta Observability Pipelines product