


Amazon Athena is the default choice for running S3 data with SQL queries. No infrastructure to manage, and you only pay for the data scanned. Sounds great, right? Until it isn’t.
Athena has its limits. It can get expensive fast if you’re not optimizing files. Query latency isn’t ideal for interactive workloads. And if you’re working with large-scale analytics or complex pipelines, the cracks start to show.
That’s where alternatives come in. Whether you’re chasing better performance, lower costs, real-time results, or more control over your query engine, there’s no shortage of serious options built to run SQL over S3 or decouple compute and storage more efficiently than Athena.
Let’s break down the best Amazon Athena alternatives for querying S3: how they work, how they scale, how they hit your budget, and where they shine. No fluff. Just practical insight on picking the right engine for your S3-based workloads.
Key Takeaways
• Athena is easy to start with but costly and slow at scale.
• Some alternatives can serve different workloads better.
• Performance improvements often require more setup or cost control.
• Direct S3 querying and open format support are essential.
• Fit depends on your team, tools, and real-world usage. No tool is universally best.
Why Look Beyond Amazon Athena?
Athena is serverless, easy to set up, and plugs straight into S3. But that simplicity comes with trade-offs, and they add up fast at scale.
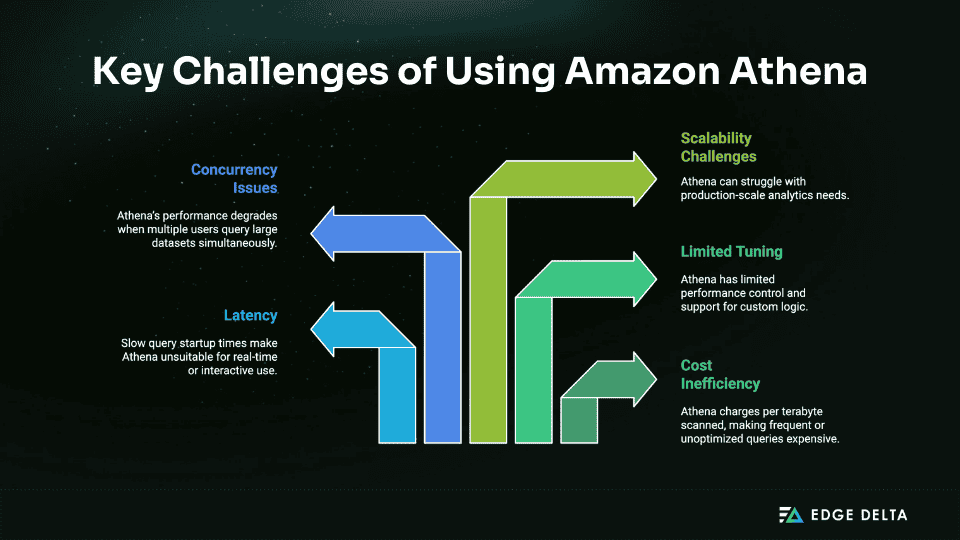
Cost inefficiency tops the list. Athena charges per terabyte scanned. If you’re querying raw JSON or poorly partitioned data, costs spike fast.
The pricing model favors sporadic queries over exploratory or high-frequency analysis, even with Parquet or ORC optimization. AWS pricing documents indicate that 1TB of scanning will cost $5. When dealing with big datasets or ad hoc exploration, that quickly mounts up.
Latency is another bottleneck. Athena isn’t built for low-latency use cases. Queries can take several seconds just to spin up, so it may be unsuitable for dashboards or real-time apps. Performance testing from various teams, including engineering blogs like Airbnb, consistently shows Presto-based engines outperforming Athena under concurrent loads.
Limited tuning and extensibility. Athena’s serverless nature is a double-edged sword—you can’t fine-tune memory, parallelism, or caching. If you need custom UDFs, complex joins, or advanced orchestration, you’ll hit its boundaries fast.
Concurrency constraints exist, too. While AWS increased limits over time, Athena still isn’t ideal for high-concurrency use cases. If multiple analysts query large datasets simultaneously, expect noticeable slowdowns.
Athena is frequently a starting point rather than the final solution for companies looking to scale their data lake usage or create production-grade analytics pipelines.
How to Evaluate Athena Alternatives
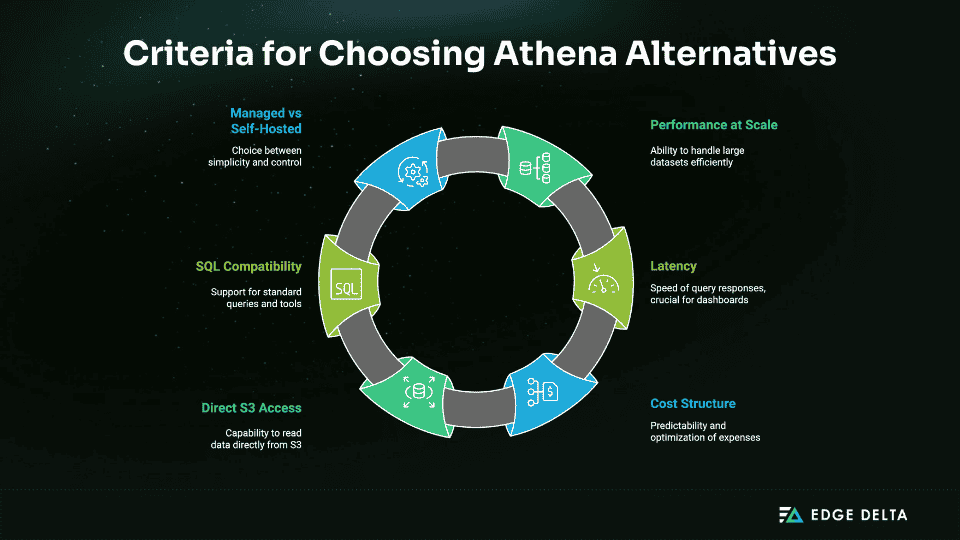
Not all Athena alternatives are created equal. Choosing the right engine depends on how and how often you query data in S3. Here’s what actually matters:
1. Performance at scale
Large datasets must be handled effortlessly by the system you’re using. Engines like Trino are designed to operate at an enormous scale, effortlessly executing interactive queries over petabytes. Usually, the data isn’t the reason your queries are delayed today. It is the engine.
Helpful Article
If your workloads include parsing large volumes of AWS VPC logs, make sure your engine handles structured semi-structured formats efficiently. This can be a hidden bottleneck in scaling performance. Check out our guide on how you can enhance your AWS VPC log processing efficiency for query performance and threat detection.
2. Latency
Athena may be sluggish, particularly when starting cold. If you need quick responses or are powering dashboards, search for engines that favor low-latency execution. This is where ClickHouse and Dremio shine because of their aggressive caching and columnar optimization.
3. Cost structure
Athena’s pay-per-scan model sounds simple until your monthly bill spikes. Alternatives like Databricks or Starburst let you control clusters and caching, which often means more predictable and optimized costs over time.
4. Direct S3 access
There is no negotiating this one. No ETL or copy tasks should be necessary; the engine should read straight from S3. An added bonus is that it supports open formats like JSON, ORC, and Parquet natively.
Pro-Tip
Look for engines that offer built-in observability and adaptable telemetry pipelines, especially if you’re streaming or querying logs directly from S3. These features can improve cost efficiency and give you visibility across your stack.
5. SQL compatibility
SQL is not one-size-fits-all. Ensure the engine supports standard queries and connects well with your existing tools, whether PrestoSQL, Spark SQL, or ANSI.
6. Managed vs self-hosted
Choose managed if you require simplicity and speed. Want authority and personalization? Self-hosting could be worthwhile. Simply consider the trade-offs between growing flexibility and operations expense.
Top Alternatives to Amazon Athena
Athena is excellent for getting started, but it’s time to look into other options if you’re reaching limits with regard to cost, speed, or flexibility. All of these engines allow you to query data straight from S3, but they each have unique features.
1. Trino (formerly PrestoSQL)
Best for*: Teams unifying analytics or building custom data stacks*
Trino is a fast, distributed SQL query engine built for running interactive queries over large datasets. It can federate data across multiple sources: S3, MySQL, Kafka, Hive, and more. It is ideal for modern data lake environments.
It separates compute from storage and executes queries in parallel across distributed worker nodes. This architecture reduces latency and handles complex joins efficiently.
By reading directly through the Hive connector, Trino provides robust S3 support, effortlessly managing formats such as Parquet, ORC, and JSON. It excels in BI tool integration, full ANSI SQL compliance, high concurrency, and a thriving open-source community.
The tradeoff? You’ll need to self-host and manage some operational overhead. Also, out-of-the-box query acceleration is not included (unless you layer in extras like caching).
2. Starburst Galaxy (Managed Trino)
***Best for: ***Teams that want Trino flexibility, zero ops, fast queries
Starburst Galaxy offers everything Trino does, plus the convenience of a fully managed platform. It brings enterprise-grade features like role-based access control, autoscaling, caching, and query optimization, all pre-configured.
This platform makes use of result caching, cost-based optimization, and advanced filtering to optimize the speed of Trino’s already powerful core engine. It offers full support for open-format queries on S3 data, including partition pruning and schema discovery.
Starburst Galaxy is made for contemporary data teams and has built-in security, no infrastructure to maintain, and smooth integration with cloud-native tools like Apache Superset and dbt.
Its primary disadvantage is that it’s a paid platform with usage-based pricing, which means that if you have more questions, your costs may increase significantly.
3. Apache Spark (via EMR, Glue, or Databricks)
Best for*: Data crunchers, pipeline pros, ML wizards, and batch bosses*
Apache Spark is a versatile processing engine that supports batch, streaming, and machine-learning workloads. Through services like AWS EMR or Databricks, it can be configured to query S3 data directly and efficiently.
Databricks brings native S3 support with s3a:// paths, effortlessly handling all major file formats, including Delta Lake and Iceberg. It’s built for serious data work: complex ETL, heavy transformations, and massive-scale pipelines, all supercharged by the Photon engine and Delta caching.
Flexibility is its superpower. It handles both structured and unstructured data expertly and scales to petabytes, regardless of whether you’re coding in Python, SQL, or Scala.
However, it might be overkill for simple queries. Without tuning, it can drag on small, interactive tasks. Still, if you’re moving serious data, Databricks is a beast.
4. ClickHouse with S3 Connector
Best for*: Real-time insights, time-series crunching, and high-speed data flows*
ClickHouse is a high-performance OLAP engine built for real-time analytics. It can query data stored in S3 using table functions or native storage integrations.
With blazing-fast query speeds powered by vectorized execution and smart compression, this tool shines when it comes to time-series and aggregated queries. It is perfect for real-time dashboards and low-latency analytics APIs.
ClickHouse handles Parquet, CSV, and JSON natively. Its s3() table function allows direct file access from S3 without ETL. It now also supports limited JSON schema extraction, although schema evolution can still be challenging.
Its advantages? Reliability, low overhead, and sub-second performance where speed is crucial.
Note that it’s not as flexible with semi-structured or evolving schemas, and its ANSI SQL support is a bit on the limited side.
5. Dremio
Best for*: Mid-sized analytics teams*

Dremio is a self-service analytics engine optimized for querying data lakes. It lets users run high-speed SQL queries over raw S3 data without needing ETL or data movement.
The platform delivers seamless S3 support with native compatibility for Iceberg, Parquet, and other open formats, plus direct S3 access and automatic schema detection to keep things frictionless.
It provides lightning-fast performance thanks to its intelligent “reflections” materializations, columnar caching, and Apache Arrow under the hood. It speaks lakehouse formats natively, is easy to use, and integrates seamlessly with BI tools.
However, advanced features like workload management are locked behind Dremio’s enterprise tier.
6. Redshift Spectrum
Best for*: Blending Redshift warehouse data with data lakes*
Spectrum extends Amazon Redshift’s SQL engine to query external data stored in S3. You can join S3 data with Redshift tables, allowing hybrid workloads without loading everything into the warehouse.
Amazon Redshift Spectrum lets you query data directly in S3 using external schemas, with support for formats like Parquet, ORC, and CSV.
Smart partitioning is essential for speed because Spectrum queries are typically slower than in-cluster ones. And since it uses Redshift’s ANSI-compliant SQL engine, you don’t sacrifice syntax compatibility.
With federated queries and unified IAM-based permissions, it excels if you’re already well-versed in the Redshift ecosystem.
But watch out: it shares Athena’s pricing model at $5 per terabyte scanned, and performance doesn’t quite match up to specialized engines.
7. BigQuery Omni
Best for*: BigQuery pros and multi-cloud masters*
BigQuery Omni brings Google’s query engine to AWS and Azure via Anthos. It lets you query data stored in S3 using BigQuery’s familiar SQL interface without moving data out of AWS.
Omni makes it simple to integrate with AWS by providing native S3 support through integrated data connectors and Anthos infrastructure.
Because of its automatic scaling and full use of BigQuery’s optimizer and caching, it offers excellent performance for analytical workloads. It even allows centralized analysis from a single pane by querying across multiple clouds without duplicating data.
However, it’s not all smooth sailing. Its latency can be higher than native GCP workloads, and its cost model may introduce some overhead (e.g., networking and Anthos licensing).
8. Snowflake External Tables
Best for: Snowflake teams skipping full ingestion and offloading cold data to S3
Snowflake’s external tables let you define and query data stored in S3 as if it were local to your warehouse. It works well for analytics on semi-structured data without full ingestion.
The platform offers built-in S3 support, letting you easily define external stages and point to S3 paths using Parquet, JSON, or ORC files. It taps into the power of Snowflake’s warehouse engine, along with smart caching and pruning, to deliver efficient reads.
Setup is a breeze, with native support for popular data lake formats and seamless integration with internal Snowflake tables.
Although, external scans don’t match the speed of internal queries. Costs can also spike if you’re working with large, unpartitioned datasets.
Performance & Cost Comparison Matrix
If you’re choosing an Athena alternative, performance and pricing go hand-in-hand. Here’s a side-by-side look at how each tool stacks up across key factors, so you can pick based on your workload demands.
| Tool | Query Performance | Pricing Model | File Format Support | Integration Ease | Real-Time Support |
|---|---|---|---|---|---|
| Trino | High (scale-out parallel) | Self-hosted (infra-based) | Parquet, ORC, JSON, CSV | Medium (needs config) | Moderate (not built-in) |
| Starburst Galaxy | Very High (optimized Trino) | Usage-based SaaS | All Trino formats | High (plug-and-play) | Moderate (limited caching) |
| Apache Spark | High (batch-optimized) | Cluster/hourly (infra + jobs) | All major formats | Medium (platform-specific) | Limited (via micro-batch) |
| ClickHouse | Very High (OLAP-tuned) | Infra-based or SaaS | Parquet, CSV, JSON | Medium (S3 setup needed) | Yes (sub-second latency) |
| Dremio | High (Arrow + Reflections) | Freemium + Enterprise tiers | Iceberg, Parquet, ORC | High (SaaS or on-prem) | Yes (with caching) |
| Redshift Spectrum | Medium (partition-dependent) | $5/TB scanned (like Athena) | Parquet, ORC, CSV | High (native for Redshift) | No |
| BigQuery Omni | High (BigQuery backend) | Usage-based (SaaS + Anthos) | Parquet, ORC | Medium (requires setup) | Limited |
| Snowflake External | Medium-High (caching helps) | Compute + storage-based | Parquet, ORC, JSON | High (native support) | No (batch-only) |
Use Case Recommendations
Picking the right engine comes down to what you’re trying to do. Here’s a no-nonsense breakdown of which tools fit which jobs based on real-world strengths, not vendor hype.
Batch Analytics: Apache Spark, Dremio
If you’re running large-scale data transformations, scheduled jobs, or ELT pipelines, you want something that chews through data efficiently without choking on volume.
- Apache Spark (via EMR, Glue, or Databricks) is built for heavy lifting. It excels at transforming terabytes or petabytes of raw data into clean, structured outputs. It’s also deeply integrated into orchestration tools like Apache Airflow and Kubernetes.
- Dremio, on the other hand, offers high-speed batch query performance without the need for staging or ETL. Its “reflections” feature makes repeated queries dramatically faster by materializing results under the hood.
Interactive Dashboards: Trino, Starburst Galaxy
If analysts are using Tableau, Superset, or Looker to run ad hoc queries or slice dashboards, you need low-latency, high-concurrency performance.
- Trino is designed for distributed SQL at scale, with strong support for BI integrations and ANSI SQL compliance. Netflix and Lyft use it to power dashboards over multi-source datasets.
- Starburst Galaxy enhances Trino with autoscaling, caching, and query optimization, giving analysts faster results with zero tuning required.
Low-Latency Analytics: ClickHouse
When milliseconds matter (like in IoT metrics, user tracking, or live dashboards), ClickHouse is hard to beat.
It’s optimized for OLAP-style queries, with vectorized execution and compressed storage that makes real-time querying fast and cheap. Companies like Cloudflare and Yandex rely on it for sub-second analytics.
ClickHouse doesn’t just run fast. It’s built to stay fast, even under load.
Mixed Workloads: Databricks, Snowflake
Need to run BI queries, ETL pipelines, and data science workloads on the same platform? These two offer flexibility without compromise.
- Databricks supports SQL and notebooks, making it perfect for teams juggling dashboards and ML pipelines. With Delta Lake, it brings ACID compliance to your S3 data lake and speeds up queries through caching and indexing.
- Snowflake handles structured and semi-structured data. With its external table support, you can query S3 without ingestion. It also scales compute separately from storage, which is great for balancing workloads.
Serverless Simplicity: BigQuery Omni
If you want to run SQL on S3 data without managing any infrastructure and keep your data in AWS, BigQuery Omni is built for that.
It’s powered by Google’s BigQuery engine but runs queries directly in your AWS environment using Anthos. You avoid data movement, get Google’s analytical horsepower, and keep everything serverless and managed.
Conclusion: Is Athena Still Enough for Serious S3 Analytics?
As we said earlier, Amazon Athena is great until it isn’t. If you’re hitting limits on cost, speed, or flexibility, there are better tools built for scale, real-time needs, and complex pipelines.
Trino and Starburst shine for interactive analytics. Spark and Dremio are workhorses for batch workloads. ClickHouse owns low-latency use cases. And if you want simplicity without infrastructure, BigQuery Omni or Snowflake External Tables offer clean, serverless options.
No one-size-fits-all. The right choice depends on your architecture, query patterns, and cost tolerance. Start small. Benchmark. See what fits not just technically but operationally.
Modern data lakes are growing fast. Your query engine should keep up.
Athena Alternatives FAQs
Can Athena query S3 glacier?
No, Athena cannot query data directly stored in S3 Glacier or Glacier Deep Archive. Data must be restored to S3 Standard or S3 Standard-IA first.
Which AWS service can be used to query data stored in S3?
Amazon Athena can query structured data directly in S3 using SQL. Amazon Redshift Spectrum and AWS Glue can also query S3 data.
What is the difference between Athena and Redshift?
Athena is serverless and is used for ad-hoc queries on S3 data. Redshift is a data warehouse optimized for complex queries and long-term analytics at scale.

