


Argo CD is an open-source, continuous delivery (CD) tool that runs inside Kubernetes clusters and uses GitOps workflows to automate deployments and continuously reconcile any deviations from the defined states within Git repositories. Argo CD emits logs that capture events like sync operations, Git fetches, templating errors, and user actions, but they have inconsistent formats and fields. This makes it difficult to extract meaningful insights or monitor issues at scale.
If you’re using Argo CD, you can leverage Edge Delta’s pre-built Argo CD Pack within our intelligent Telemetry Pipelines to automatically standardize, classify, enrich, and convert Argo CD logs into patterns before sending them downstream. This reduces manual overhead while providing a clearer picture of Argo CD health and performance. Once processed, your Argo CD logs can be routed into Edge Delta’s Observability Platform or any other downstream destination — including legacy observability platforms and cold storage.
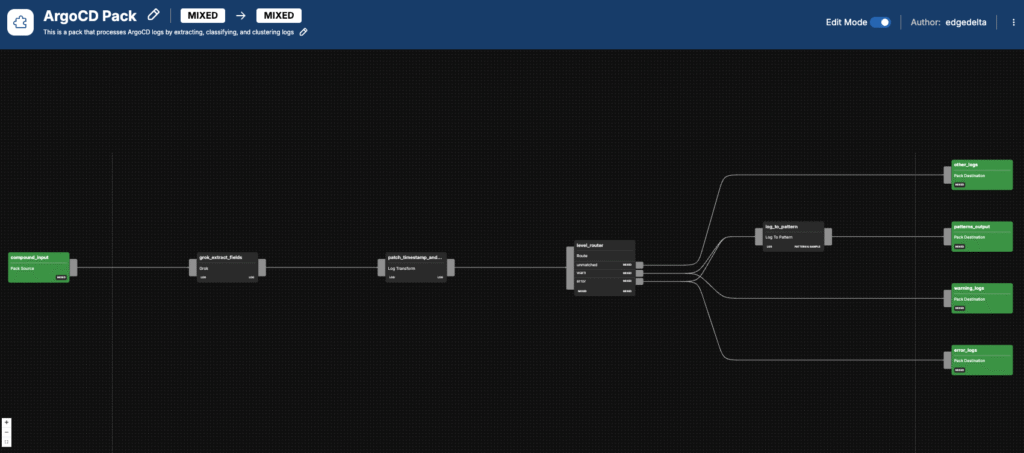
In this post, we will walk through each processing step of the Argo CD Pack to see the transformation in action.
Processing Pathway: Field Extraction
Once Argo CD logs are ingested, the pack performs an initial structuring process to facilitate simplified downstream analysis. Fields such as timestamp, level, message, application, and resource are extracted from log entries and outputted as individual attributes.
Processing Pathway: Timestamp and Severity Standardization
Now that the Argo CD logs are more efficiently structured, the pack standardizes them to provide more clarity and precision for monitoring and alerting workflows. To start, the timestamp field is converted into the Unix milliseconds format, which provides a consistent frame of reference when investigating issues. Additionally, the previously extracted log level is applied to the item[“severity_text”] field, which adds severity-level information to all log entries for noise reduction and more meaningful context during troubleshooting.
- name: patch_timestamp_and_log_level
type: log_transform
transformations:
- field_path: item["timestamp"]
operation: upsert
value:
convert_timestamp(item["attributes"]["timestamp"], "2006-01-02T15:04:05.999999Z",
"Unix Milli")
- field_path: item["severity_text"]
operation: upsert
value: item["attributes"]["level"]Processing Pathway: Log Classification
Next, logs are classified based on the severity_text value, setting up categorized outputting, deeper analysis, and remediation prioritization. Any logs with a severity defined as either warn or error are routed to a log_to_pattern node for a visual, real-time representation of your data, which we’ll discuss more in the next step.
Warning and error logs are simultaneously sent to their own respective output nodes for eventual routing to downstream destinations. By segmenting warnings and errors, you can reduce alerting noise and prioritize investigations. All remaining logs are sent to the other_logs output node to assist with comprehensive analysis.
- name: level_router
type: route
paths:
- path: warn
condition: item["severity_text"] == "warn"
exit_if_matched: true
- path: error
condition: item["severity_text"] == "error"
exit_if_matched: trueProcessing Pathway: Pattern Identification
Converting logs into patterns can help you quickly visualize and identify trends and anomalies impacting Argo CD. For this transformation, the previously mentioned log_to_pattern node takes the logs that were classified as errors or warnings and groups similar entries into log patterns. Logs that flow through this node will then wind up in the patterns_output node for eventual routing to an observability platform or archival destination.
- name: log_to_pattern
type: log_to_pattern
num_of_clusters: 10
samples_per_cluster: 5
See the Argo CD Pack in Action
To begin using the Argo CD Pack in Edge Delta, you’ll need to have an existing pipeline set up.
If you haven’t created one yet, head to the Pipelines section, click “New Pipeline,” and select either Edge or Cloud, depending on your hosting setup. Next, follow the prompts to complete the pipeline configuration.
Once your pipeline is live, open the Pipelines menu, go to “Knowledge,” and select “Packs.” Scroll down until you find the Argo CD Pack, then click “Add Pack.” This will add it to your personal library, which is always accessible via the “Packs” menu.
To install the pack in a pipeline, head back to your Pipelines dashboard, choose the pipeline where you want to use the Argo CD Pack, and enter Edit Mode. Click “Add Node,” and then add your Argo CD log source. Once your Argo CD logs are flowing into your source node, click “Add Node,” navigate to “Packs,” and select the Argo CD Pack.
You can then rename the pack from “Argo CD Pack” to something more descriptive if you’d prefer. Once you’re ready to add the pack, click “Save Changes.” Then drag and drop the initial Argo CD logs source connection to the pack to initialize processing.
To complete the setup, you’ll need to add destinations. Edge Delta Telemetry Pipelines allow you to route your processed Argo CD logs to any downstream destination, such as Datadog, New Relic, Splunk, and Edge Delta. You can also route a copy of your raw Argo CD logs to any storage destination, such as S3, for later analysis.
Get Started
To start using the Argo CD Pack, check out our documentation. And if you’re a newcomer to Edge Delta, explore our free playground to see how we’re helping teams gain greater control, visibility, and flexibility over their observability and security data.



