


Alert fatigue has become a major challenge for observability teams. As alert volumes grow, these teams are forced to triage reactively, which often causes critical issues to slip through the cracks. AI-powered analysis can help them manage and respond to alerts at scale, but most agentic tools can’t analyze live data accurately, which is a non-negotiable for effective alert response.
Edge Delta’s collaborative AI Teammates is a multi-agent AI platform that automates workflows across SRE, DevOps, and Security, including real-time alert analysis and response. These out-of-the-box AI agents work together — and with your human team — to continuously evaluate new alert triggers, summarize related events, and initiate remediation plans.
AI Teammates stand out from other agentic solutions because they’re built on top of Edge Delta’s enterprise-grade Telemetry Pipelines, which continuously supply them with the freshest, most valuable data — grounding their responses and keeping them operating in real time.
In this post, we’ll show you how to use AI Teammates to manage and respond to alerts in Edge Delta’s Observability Platform — and demonstrate how their reliable analysis helps reduce alert fatigue so teams can stay focused on their highest-priority incidents.
Using Periodic Tasks to Automate Monitor Check-Ins
Monitors are essential for catching issues early and keeping systems healthy, but they can also overwhelm teams with noisy signals and false positives. As environments grow more complex, teams are flooded with alerts that look urgent but often turn out to be harmless fluctuations. A typical on-call engineer might start the morning sifting through dozens of notifications before finding one that truly matters.
AI Teammates help break that cycle by periodically reviewing monitor output in context. Instead of simply checking whether monitors are healthy, AI Teammates analyze the surrounding telemetry data to determine whether an alert reflects a real issue.
In the example scenario below, there are a several live monitors running in Edge Delta’s Observability Platform, tracking important performance metrics including pipeline throughput, error log rate, and pattern anomaly frequency:
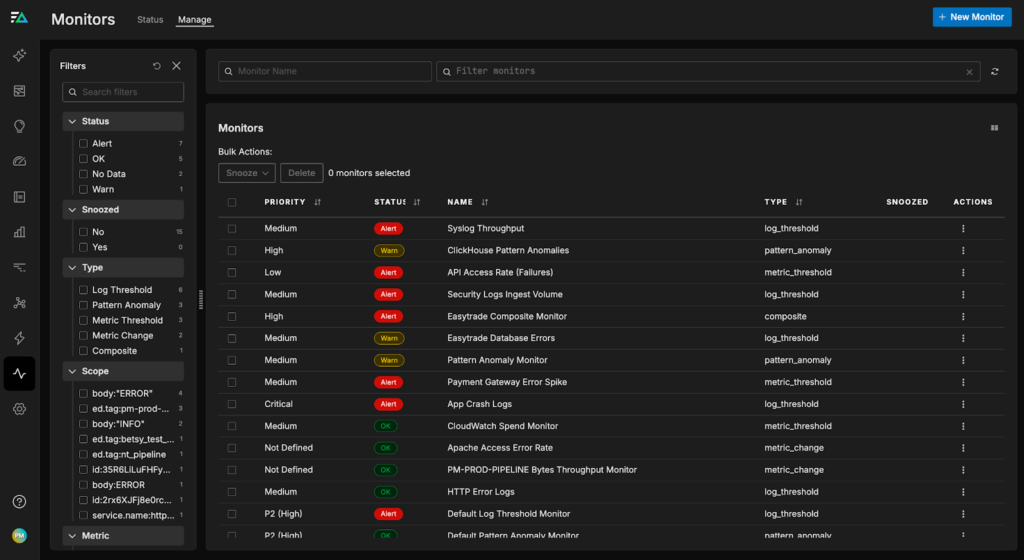
Instead of forcing humans to analyze and prioritize each active alert — which could take hours — let’s set up a Periodic Task for AI Teammates to do it instead. First, we’ll navigate to the “Periodic Tasks” tab in the “AI Team” section, and select “Add Task.” Then, we’ll give Teammates a plaintext request to watch over our monitors, set a frequency and target channel, and save it:
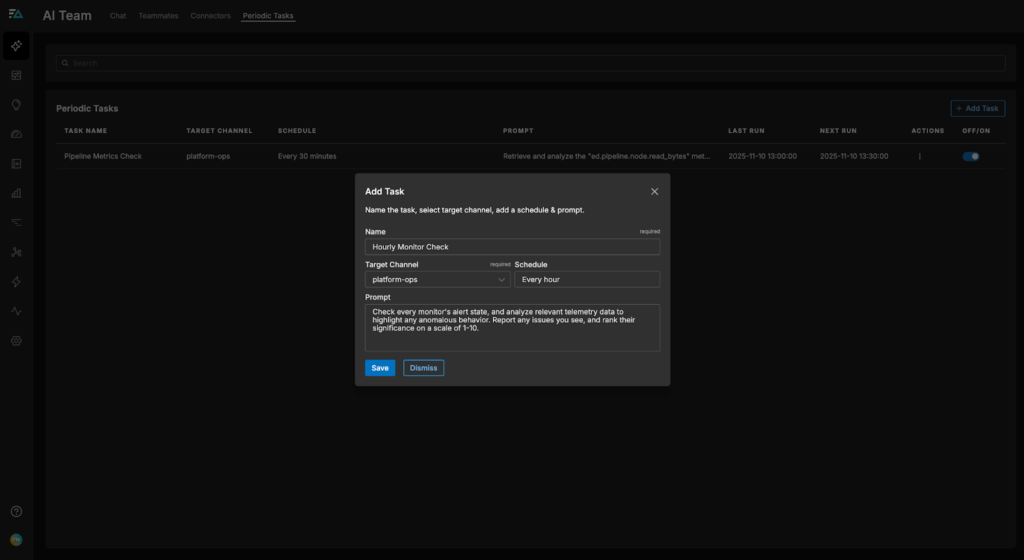
Now, the OnCall AI super-agent will receive an hourly notification in the #platform-ops channel to evaluate monitor behavior and pull in relevant telemetry data. From there, it will open a new thread and call on the appropriate Teammate (most likely the SRE agent) to analyze each monitor state, query the associated logs and metrics, and summarize its findings.
In the thread shown below, OnCall AI receives the monitor check notification and asks the SRE Teammate to perform a monitor health sweep. It immediately begins analyzing recent logs and patterns associated with each monitor — and evaluates the metrics each monitor is tracking. The SRE Teammate highlights a few unusual log spikes, but otherwise concludes that no significant issues are present:
From here, we can continue the investigation ourselves, or ask the SRE agent to take further action — including publishing a summary document in JIRA or creating a low-priority incident in PagerDuty for the unusual spikes.
Notifying AI Teammates Directly With Alert Triggers
AI Teammates can also be notified directly whenever a new alert is triggered, and immediately begin searching through relevant telemetry data, code snippets, or environment changes to pinpoint the root cause.
To set this up, all we need to do is tag a Teammate in the “notification” portion of the monitor. For instance, we can configure the “PM-PROD-PIPELINE Bytes Throughput” monitor to notify the SRE Teammate when it enters a WARN state, or call the Issue Coordinator Teammate when it enters an ALERT state:
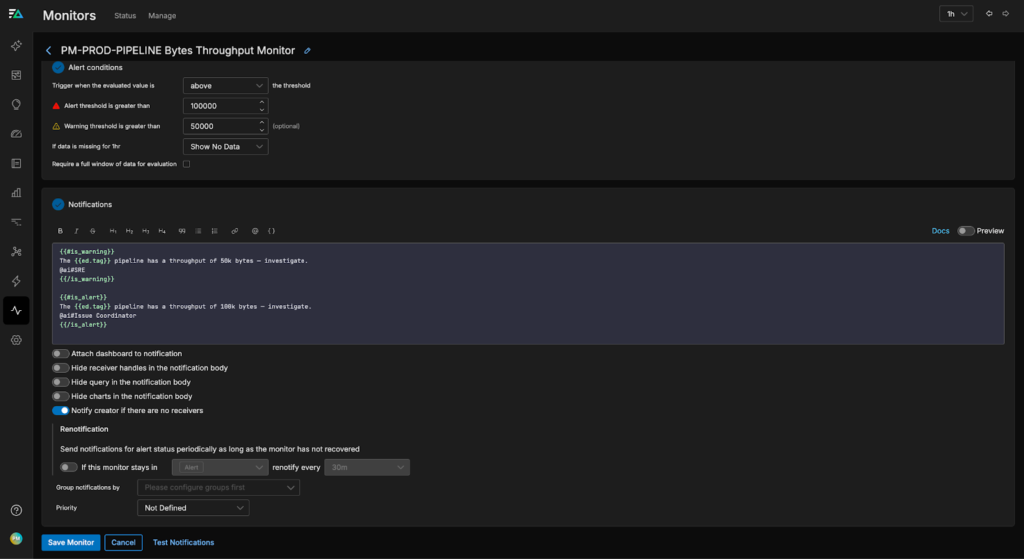
If we aren’t sure which Teammate is the best choice to respond, we can also send a general message in a specified channel and let On Call AI decide in real time, as shown in the configuration for the “HTTP Error Logs” monitor below:
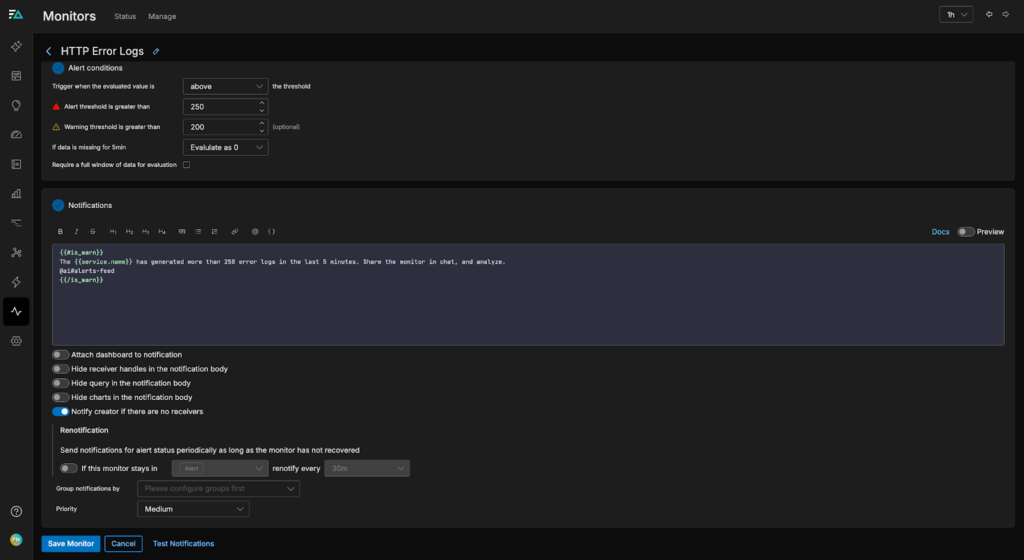
Now, when an alert fires, the assigned Teammates can immediately begin root cause analysis, summarization, and remediation planning. By handling the busywork upfront, they accelerate time-to-resolution and make it easier for humans to step in with clear, data-driven context.
In the example below, a new permissions issue blocks access to a cloud-hosted Redis cache, leading to a spike in access error logs. The #alerts-feed channel is notified immediately, and AI Teammates begin investigating:
As you can see, OnCall AI first asks the SRE agent to review recent logs and pattern data to identify any anomalies connected to the alert. Next, it loops in the DevOps Engineer agent to validate the SRE agent’s findings and share any relevant pipeline metrics. Finally, the Cloud Engineer agent joins the investigation to verify that all cloud deployments are healthy and to identify any potential issues related to the Redis access issue. After the investigation concludes, OnCall AI writes a short summary that includes the following bullets:
Root-cause hypotheses: likely related to authentication/configuration issues, dependency failures, resource exhaustion, or shared infrastructure problems.
Next steps: monitor for recurrence, review recent changes to authentication and dependencies, check for server-side resource exhaustion.With this in-depth agentic analysis, our human team now has clear, actionable steps to address this permissions issue. What might have taken hours to analyze took AI Teammates a few minutes, giving us a strong foundation to help accelerate remediation.
Conclusion
Managing alerts in modern environments is hard. The sheer volume, complexity, and interdependencies across systems can quickly overwhelm even the most experienced teams, leading to alert fatigue, missed incidents, and slower response times. Traditional tools and basic AI agents often fall short, as they either generate more noise or lack the capabilities needed to prioritize and resolve issues in real time.
Edge Delta’s AI Teammates minimize alert fatigue by analyzing alerts as they are triggered, grounding their analysis in the logs, metrics, and trace data flowing through your pipeline. No matter the issue, these specialized agents know what to look for, how to summarize key insights, and how to provide actionable guidance that accelerates remediation.
To learn more about how AI Teammates can help you automate workflows across observability and security — including live alert analysis that reduces fatigue — start a free trial.



