


Batch processing and stream processing are two distinct approaches to data handling and analysis. Understanding the distinctions between batch and stream processing can help organizations choose the most effective solution based on operational complexity, latency constraints, and data processing requirements.
Stream processing continuously processes data, providing immediate insights and actions for real-time analytics, monitoring, and decision-making tasks, including IoT data processing, fraud detection, and live dashboard updates. Batch processing is ideal for ETL operations, report production, and data backups since it can handle massive volumes of data at predetermined times.
This article will explore the differences between stream and batch processing and their advantages and challenges.
Key Takeaways:
The distinctions between stream and batch processing help organizations find the most suitable data processing method.
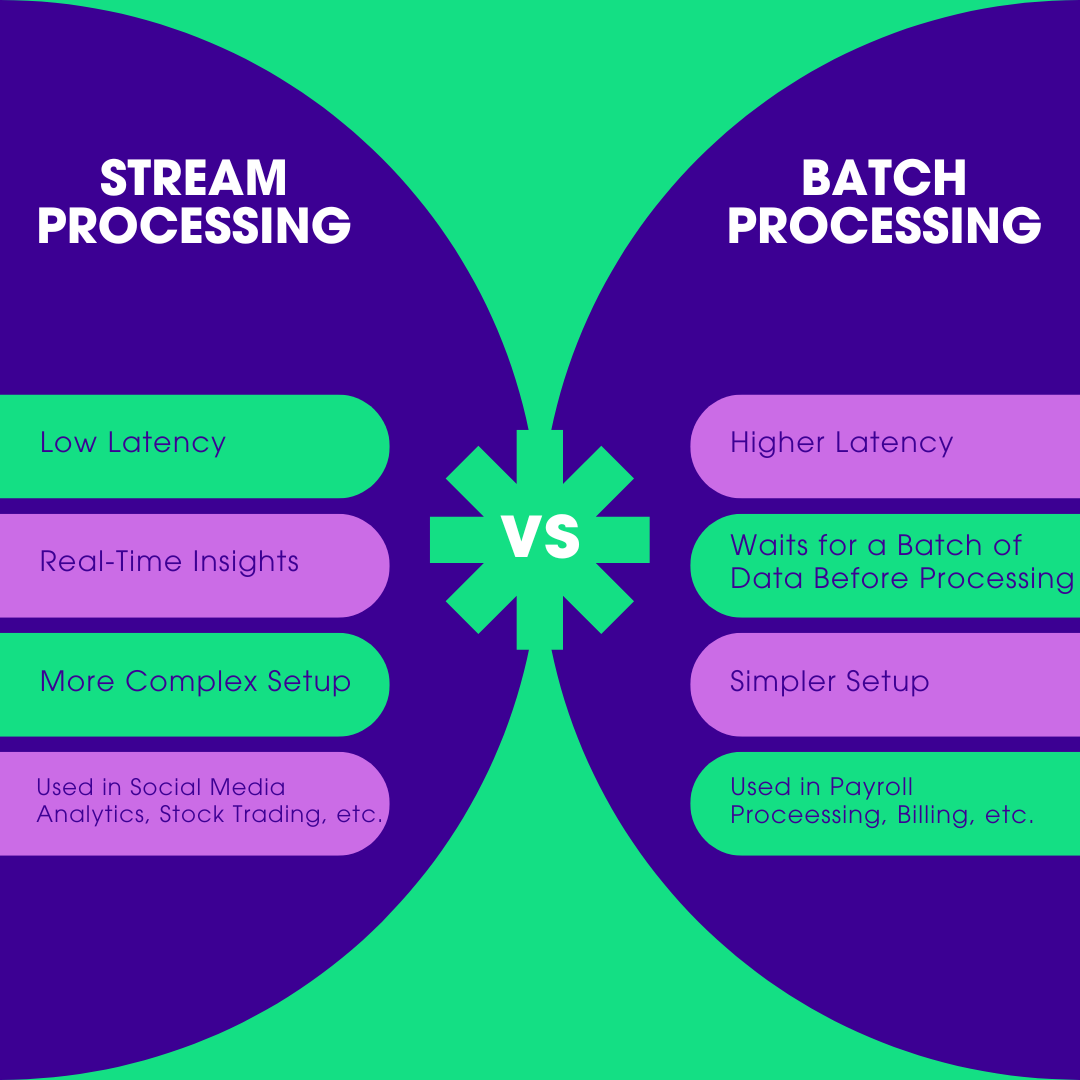
Batch processing organizes data at predetermined intervals, while stream processing handles data in real-time.
Stream processing has a low latency, which is ideal for immediate responses.
Batch processing has a higher latency, making it suitable for tasks tolerating delays.
Real-time analytics work best with stream processing, while large-scale data analysis is where batch processing excels.
Stream Processing vs. Batch Processing: What’s the Difference?
Batch processing manages large amounts of data saved at predetermined times, making it great for jobs like order reconciliation and recurring reporting in sectors like banking and retail. Stream processing continuously processes data in real-time, making it suitable for immediate decision-making tasks, including fraud detection, live monitoring, and real-time analytics.
Creating effective data processing systems requires understanding batch and stream processing distinctions. The decision between these approaches is influenced by processing complexity, latency requirements, and data volume.
Here’s a brief comparison of stream and batch processing:
| Criteria | Stream Processing | Batch Processing |
|---|---|---|
| Data Processing | Continuous processing of data in real-time | Processing data in fixed-size batches |
| Latency | Low latency, near-real-time processing | Higher latency, processing occurs at intervals |
| Use Cases | Real-time analytics, fraud detection, live dashboards | Periodic reporting, ETL jobs, data backups |
| Scalability | Scales horizontally with data volume to handle varying data velocities | Scales vertically with batch size or horizontally depending on the use case |
| Complexity | More complex due to continuous data flow | Simpler as it deals with finite data chunks |
| Fault Tolerance | More critical, needs to be highly resilient | Less critical, can be restarted if it fails |
Below is a deeper discussion of stream and batch processing key features for a better understanding of their implications.
- Data Processing
- Batch processing works well for large databases requiring a lot of computing since it entails gathering and analyzing enormous volumes of data over an extended period. After sufficient data has been obtained and saved, it is processed in large quantities or chunks.
- Stream processing ingests, processes, and analyzes data in real-time or almost real-time, even as the dataset grows rapidly. This approach does not require waiting for data to be collected; instead, it processes data as soon as it is received.
- Latency
- Data processing takes longer in batch processing, which results in higher latency. It waits for a batch to be completed or a specified timetable to begin processing, making it suitable for tasks that can tolerate delays. Since data is processed as it enters the system, stream processing has a shorter latency, making it ideal for applications needing immediate insights and real-time analytics.
- Use Cases
- Batch processing is commonly used for applications like monthly payroll processing, creating end-of-day reports, and large-scale data analytics where immediate data processing is not required. Stream processing calls for more advanced fault tolerance systems. If a data stream is disrupted, the system must manage the disruption and guarantee that no data is lost.
- Scalability
- Systems for batch processing are often created with throughput in mind, handling massive amounts of data simultaneously. They can be scaled horizontally to manage different data velocities effectively. Stream processing often requires a more complex configuration to manage state, handle out-of-order data events, and ensure fault tolerance.
- Complexity
- Since batch processing does not have to consider the challenges of real-time processing, it may have a simpler setup and design. Stream processing frequently requires a more complex configuration, especially when handling out-of-order data events, maintaining state, and guaranteeing fault tolerance.
- Fault Tolerance
- Fault tolerance in batch processing refers to using checkpointing techniques or rerunning unsuccessful batches. Since processing operates in real time, it needs strong fault tolerance. However, maintaining fault tolerance while allowing minimal latency can be difficult.
The limitations and advantages of real-time processing and batch processing will be discussed in the next section.
Advantages and Disadvantages of Stream Processing
Stream processing uses real-time analysis, filtering, transformation, and enhancement of continuous data streams to send the processed data as data packets to storage systems, applications, and other platforms. This method is gaining traction as it combines information from multiple sources, including infrastructure resources, stock feeds, internet analytics, weather reports, and linked devices.
For many applications, real-time data processing has become crucial for performing real-time analytics tasks. The real-time feature can range from milliseconds to minutes, allowing developers to package data in short, manageable bursts and easily combine data from multiple sources.
Here are a few of the most significant benefits that stream processing offers:
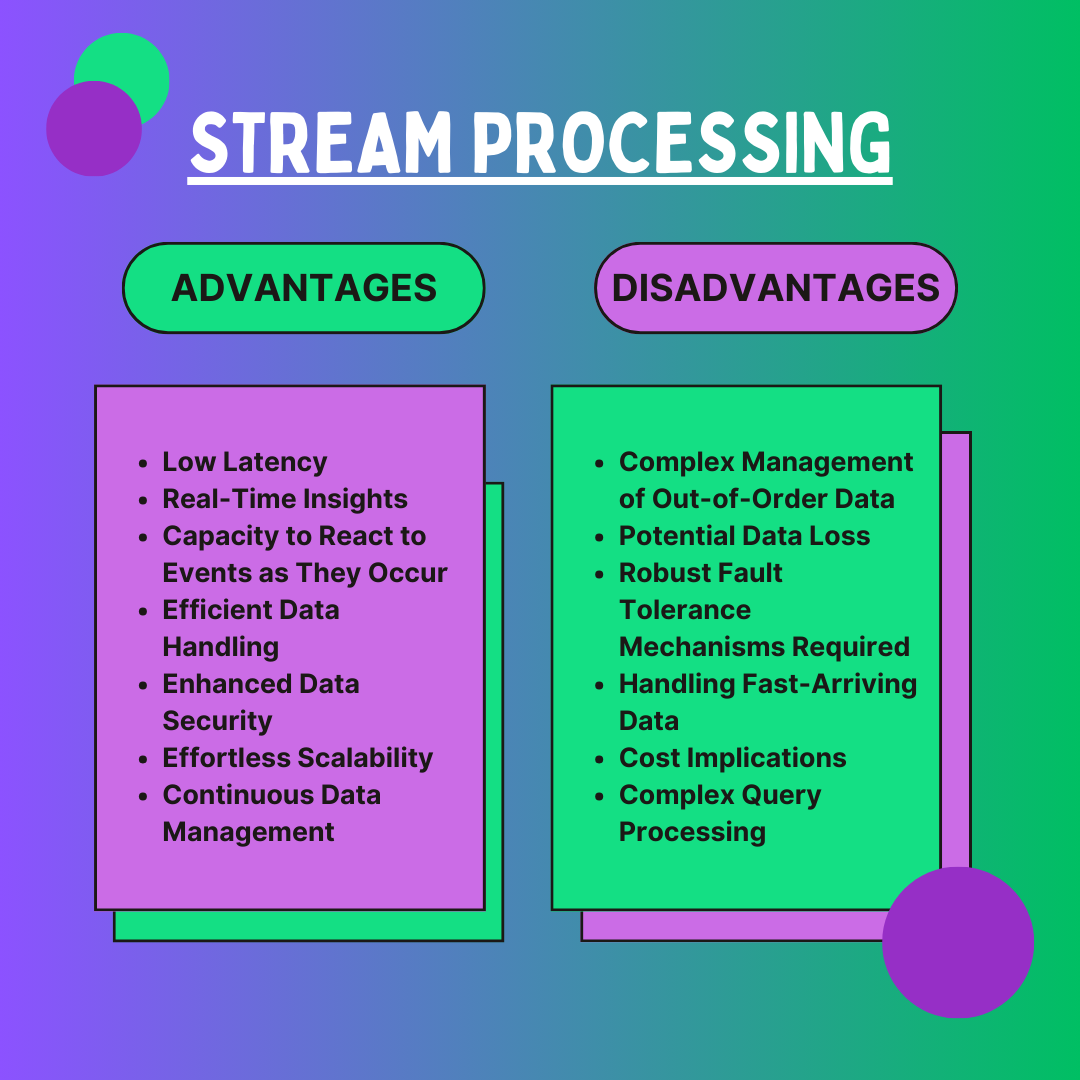
- Low Latency
- Stream processing data in real-time or near real-time minimizes latency and makes it possible to analyze and respond to incoming data immediately. This allows for immediate analysis and response to incoming data, making it ideal for applications that require instant results.
- Real-Time Insights
- Using stream processing, businesses may see data in real time as it flows, enabling prompt action and decision-making. This method is highly effective at rapidly managing massive amounts of data from various sources, making it perfect for high-pressure scenarios like emergency services or stock trading.
- Capacity to React to Events as They Occur
- Stream processing enables organizations to respond rapidly and proactively to events and triggers as they happen. This real-time responsiveness allows for rapid adjustments and interventions, enhancing operational agility.
- Continuous Data Management
- Stream processing effectively controls continuous data flows to extract crucial information from data streams and shape them in the optimal format. This continuous data handling enables better real-time analytics and monitoring.
- Efficient Data Handling
- Stream processing provides a consistent, real-time approach to data analytics by quickly recognizing and storing the most crucial information. This approach guarantees the timely processing and utilization of valuable data.
- Enhanced Data Security
- By prioritizing secure transmission methods, stream processing reduces disparity in data handling and guarantees that data is protected and unaltered. This process lowers discrepancies and improves the data’s general integrity.
- Effortless Scalability
- Stream processing smoothly handles data, unlike batch processing, which may need significant modifications to handle increasing volumes. This scalability ensures continuous performance, even as data volumes grow.
Despite the advantages it offers, stream processing also has some drawbacks. These include the following:
- Complex Management of Out-of-Order Data
- Rearranging data and preserving data consistency in stream processing systems can be challenging when dealing with out-of-order data. This approach calls for complex algorithms and processes, complicating pipeline processing.
- Potential Data Loss
- Resilient data recovery procedures are necessary since stream processing systems are susceptible to data loss from events like system breakdowns or network outages. These procedures reduce the risk of potential data loss.
- Robust Fault Tolerance Mechanisms Are Required
- Excellent architectures and fault recovery techniques must be implemented to ensure fault tolerance. These safeguards are essential for maintaining system reliability and data integrity in stream processing, as well as for maintaining continuous operations and preventing data loss.
- Handling Fast-Arriving Data
- To maintain pace with the data flow, stream processing systems must handle rapidly arriving data, which calls for quick processing and analysis. High-performance systems with real-time data handling capabilities are needed to meet this speed requirement.
- Cost Implications
- Modern infrastructure for stream processing is expensive, involving high initial setup, maintenance, and potential upgrades. These expenses may be significant regarding money, labor, and other resources.
- Complex Query Processing
- Handling several standing queries across incoming data streams is necessary to serve various customers and applications. This demands effective algorithms and substantial memory resources to manage the data effectively.
Did You Know?
Batch processing was used on the Apollo mission in the 1960s to compute trajectories and other vital data, demonstrating the dependability of batch tasks in high-stakes situations.
Advantages and Disadvantages of Batch Processing
Batch processing accumulates data into “batches” and feeds it into an analytics system. This approach is ideal for handling large datasets or in-depth data analysis, where data points gathered over a predetermined time are processed together.
Since batch processing does not provide real-time results, data must be kept in file systems or databases. Although this approach is not suitable for projects requiring immediate results, it’s still necessary for many legacy systems that can only handle batch processing.
There are several benefits to batch processing, which are best illustrated by the following points:
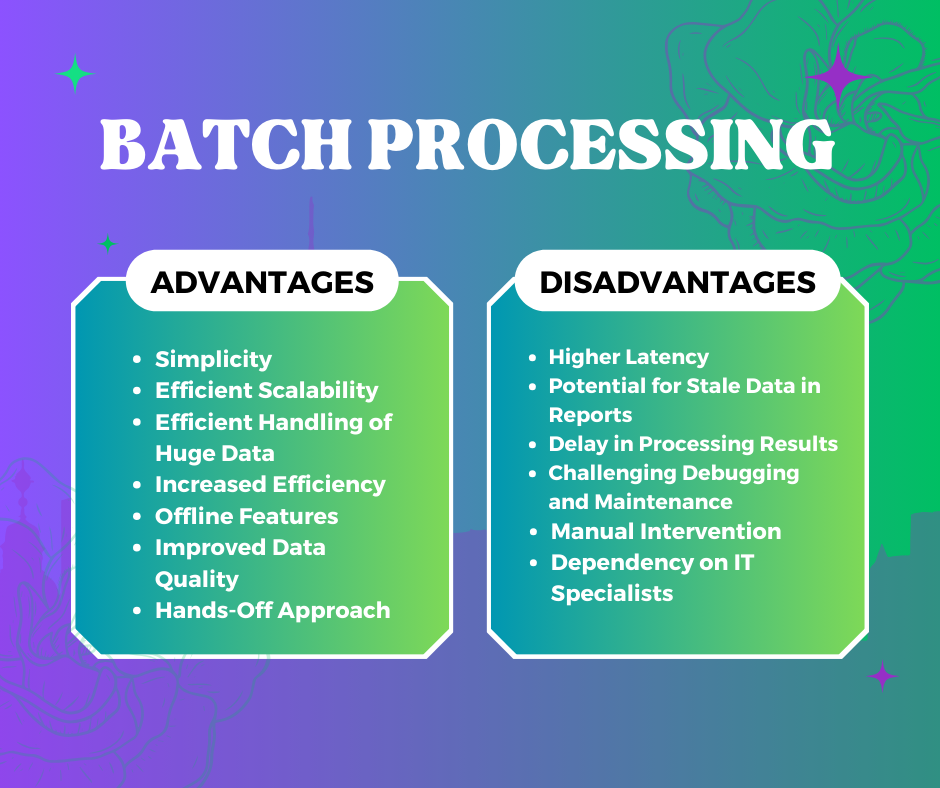
- Simplicity
- Batch processing is accessible to enterprises with basic data processing requirements due to its ease of implementation. It also eliminates the need for specialized hardware, complex data entry, and ongoing system support, simplifying the overall process.
- Efficient Scalability
- Businesses can effectively handle growing data volumes by scaling their batch processing systems. System stability is maintained as data rises, guaranteeing that growing datasets are managed without significant performance deterioration.
- Capacity to Handle Huge Data Volumes Efficiently
- By managing large data volumes in batches, batch processing maximizes resource utilization and reduces processing times. This approach speeds up processing and increases overall efficiency, making it ideal for handling large datasets.
- Increased Efficiency
- Batch processing allows scheduling tasks based on resource availability. Less critical work is delegated to batch processing, and urgent activities are prioritized, leading to smarter and more effective task management.
- Offline Features
- Batch processes allow for time flexibility by running regardless of whether they are online or offline. Tasks can be completed during off-peak hours or when the system is not in use, optimizing resource usage.
- Improved Data Quality
- Batch processing automation lowers the need for manual intervention and human errors. This increases overall data quality and yields more accurate data, crucial for reliable analytics and decision-making.
- Hands-off Approach
- Batch processing systems are self-sufficient and designed to require less supervision. They also transmit alarms when problems occur, which minimizes the need for continuous monitoring.
Although batch processing provides organizations with various advantages, it also has several limitations, including:
- Higher Latency
- When data is handled in groups or batches, batch processing adds latency, resulting in delays between data arrival and processing. Because of the latency between data gathering and processing, applications that need real-time data analysis are less suited for it.
- Potential for Stale Data in Reports
- Since batch processing works with stored data, reports could include old or stale information. This is particularly likely to happen if there is a lag between data collection and processing.
- Delay in Processing Results Until the Next Batch
- Batch processing results are only accessible after a batch. This delay may affect business operations by preventing prompt insights and actions based on the processed data.
- Debugging and Maintenance
- Batch processing systems can be challenging to maintain. Small data mistakes or issues can escalate quickly and disrupt the entire processing system, requiring careful and regular maintenance.
- Manual Interventions
- Even with automated capabilities, batch processing could need to be manually adjusted for certain needs. This could result in errors, inconsistencies, and higher labor expenses.
- Dependency on IT Specialists
- Due to complexity, batch processing systems frequently need professional IT expertise for maintenance and debugging. This dependency can slow down operations and increase costs, as organizations need to spend money on continuing system support and troubleshooting.
Conclusion
The choice between batch and stream processing depends on the organization’s specific requirements and objectives. Batch processing is recommended when managing vast amounts of data effectively, but processing in real-time is not essential, like when creating reports or carrying out intricate data analysis. However, when real-time insights and actions are critical, stream processing excels.
It allows businesses to analyze continuous data streams instantly for activities like fraud detection, system monitoring, and real-time analytics. Knowing the benefits and drawbacks of each technique enables businesses to use the one that best suits their data processing requirements, guaranteeing maximum productivity and success in their data management and analytics projects.
FAQs on Stream Processing vs. Batch Processing
What is the difference between batching and streaming?
Batch processing is a method of processing and analyzing a batch of data that has previously been kept for a while. Stream processing occurs as the data passes through a system.
What is an example of batch processing and stream processing?
Batch processing is used in systems for processing food, payroll, and billing, among other things. Stream processing is used in social media, e-commerce, the stock market, and other areas.
Which of the following are the benefits of event stream processing over batch processing in Kafka?
Batch processing enables the efficient processing of enormous data volumes at regular intervals. Event streaming is an essential component of mission-critical applications.

