


Today, many teams have an urgent need to control the massive volumes of logs, metrics, and traces that continuously flow across their environment — without sacrificing visibility or driving up costs. Telemetry pipelines play a crucial role in this process, and adoption is growing at a staggering rate.
But not all telemetry pipelines operate the same way. For instance, many legacy solutions require teams to dedicate significant resources to pipeline configuration and maintenance, which forces users to become pipeline experts before they’re able to see any value.
Edge Delta’s Telemetry Pipelines take a different approach, enabling users to manage their telemetry data effortlessly with a modern, AI-powered building experience. Our pipelines provide intelligent processing recommendations for any data stream — and include natural language support for custom processor creation through plaintext requests. Edge Delta fully handles the underlying pipeline configuration and gives users full visibility over changes before they’re applied, enabling teams to build pipelines efficiently and with confidence.
In this post, we’ll demonstrate how to easily configure pipeline processors with Edge Delta’s intelligent recommendations and natural language interface.
Intelligent Data Processing with Edge Delta
Edge Delta’s Telemetry Pipelines are powered by embedded AI, providing intelligent insights and processing recommendations for any data stream directly within the pipeline. To demonstrate, we’ll follow the documentation to deploy a new Cloud Pipeline, and start sending JSON-formatted application logs—like the one shown below—through it:
"{\"timestamp\": \"2025-09-25T07:37:50.423Z\",\"level\": \"ERROR\",\"msg\": \"Voluptates eum consequatur aut sit.\",\"user\": {\"id\": 17,\"name\": \"Chaim Lowe\",\"email\": \"kalliebraun@waelchi.com\"},\"request\": {\"method\": \"PUT\",\"path\": \"/gainsboro/minnow/orange\",\"ip\": \"191.123.68.212\"},\"response_time_ms\": 10}"There are a few changes we need to make to get our log data correctly formatted for analysis. Let’s walk through how to configure the necessary processing steps using Edge Delta’s in-pipeline intelligence.
Intelligent Processing Recommendations
Once logs begin flowing, the pipeline automatically detects a few issues — more specifically, that the JSON isn’t parsed and contains PII — and generates two processor suggestions to solve them:
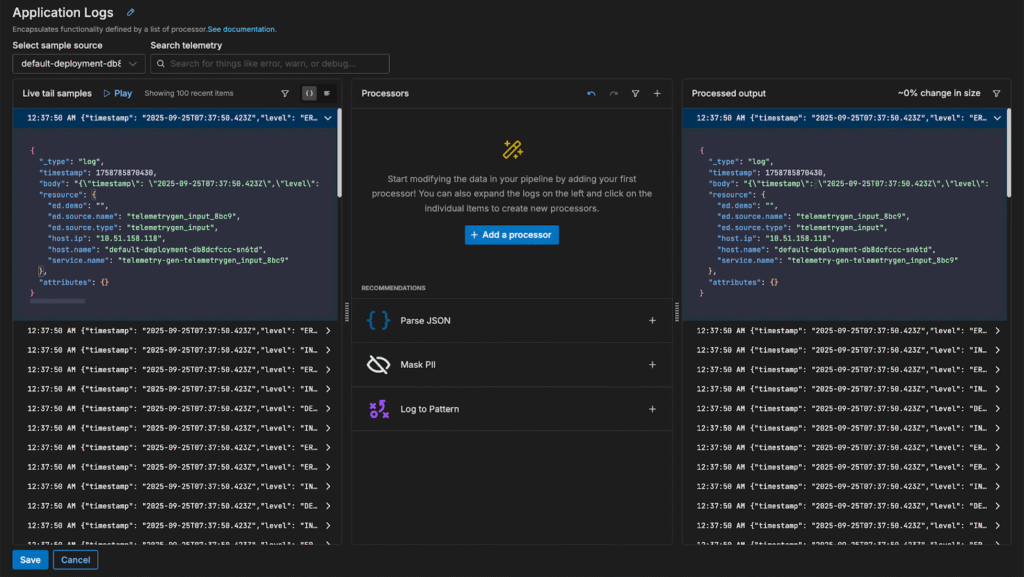
Once the logs are parsed and the fields are structured, the pipeline identifies additional processing recommendations for further optimization:
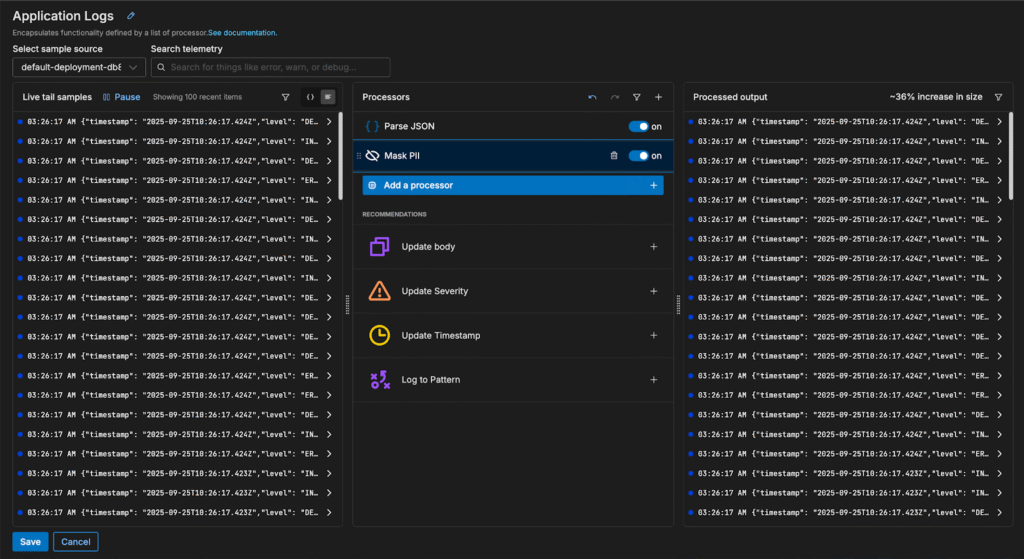
Each of these processors uses OTTL under the hood to perform the operations. For example, the “Update Severity” processor is configured with the following OTTL statement:
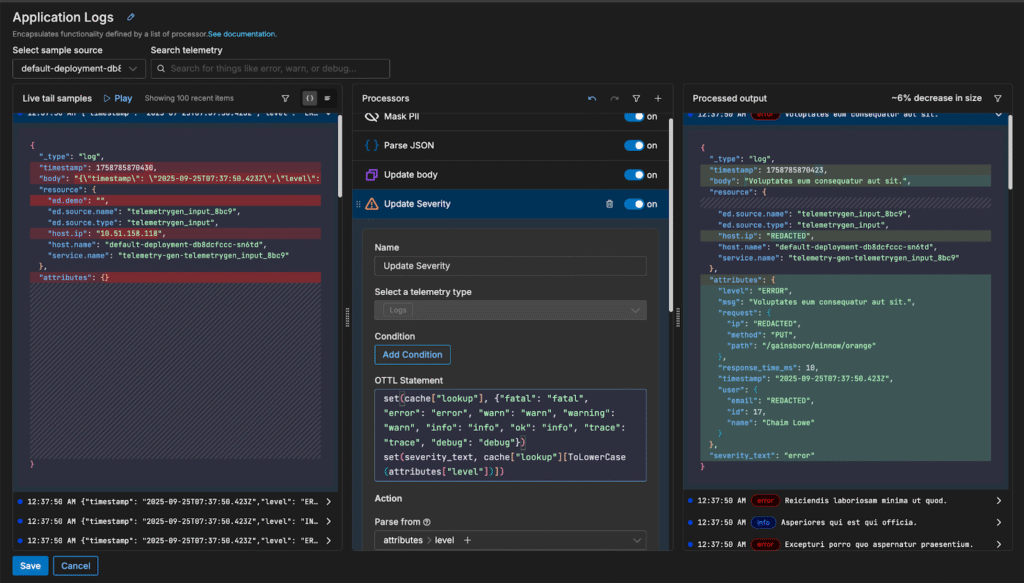
Instead of spending time learning about the complexities of caches in OTTL and manually writing that long statement, we were able to apply it with a single click.
After these processing steps, our log sample now looks like this:
{
"_type": "log",
"timestamp": 1758785870423,
"body": "Voluptates eum consequatur aut sit.",
"resource": {
"ed.source.name": "telemetrygen_input_8bc9",
"ed.source.type": "telemetrygen_input",
"host.ip": "REDACTED",
"host.name": "default-deployment-db8dcfccc-sn6td",
"service.name": "telemetry-gen-telemetrygen_input_8bc9"
},
"attributes": {
"level": "ERROR",
"msg": "Voluptates eum consequatur aut sit.",
"request": {
"ip": "REDACTED",
"method": "PUT",
"path": "/gainsboro/minnow/orange"
},
"response_time_ms": 10,
"timestamp": "2025-09-25T07:37:50.423Z",
"user": {
"email": "REDACTED",
"id": 17,
"name": "Chaim Lowe"
}
},
"severity_text": "error"
}The logs are formatted in the OTel schema, with standardized field names for key values such as response_time and path. This makes downstream analysis and correlation much easier, as operations run far more efficiently on indexed fields than on unstructured plain text.
Field Removal via Natural Language Requests
Before leaving the pipeline, we have one more processing step to configure. The “ed.source.name” and “ed.source.type” fields in the resource section aren’t valuable to us, so we want to remove them. Since this is a unique requirement, Edge Delta hasn’t provided us an out-of-the-box recommendation for this particular operation — instead, let’s do so using a natural language request.
First, we’ll need to add a new {Custom} processor node from the drop down menu:
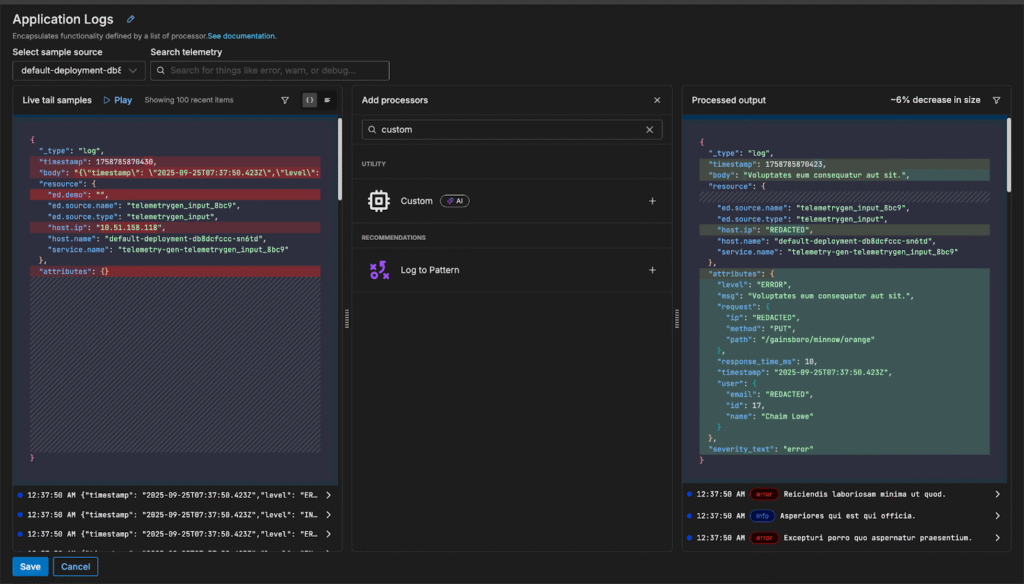
Next, we’ll enter a plain-text command for the processor that describes what we want to happen:
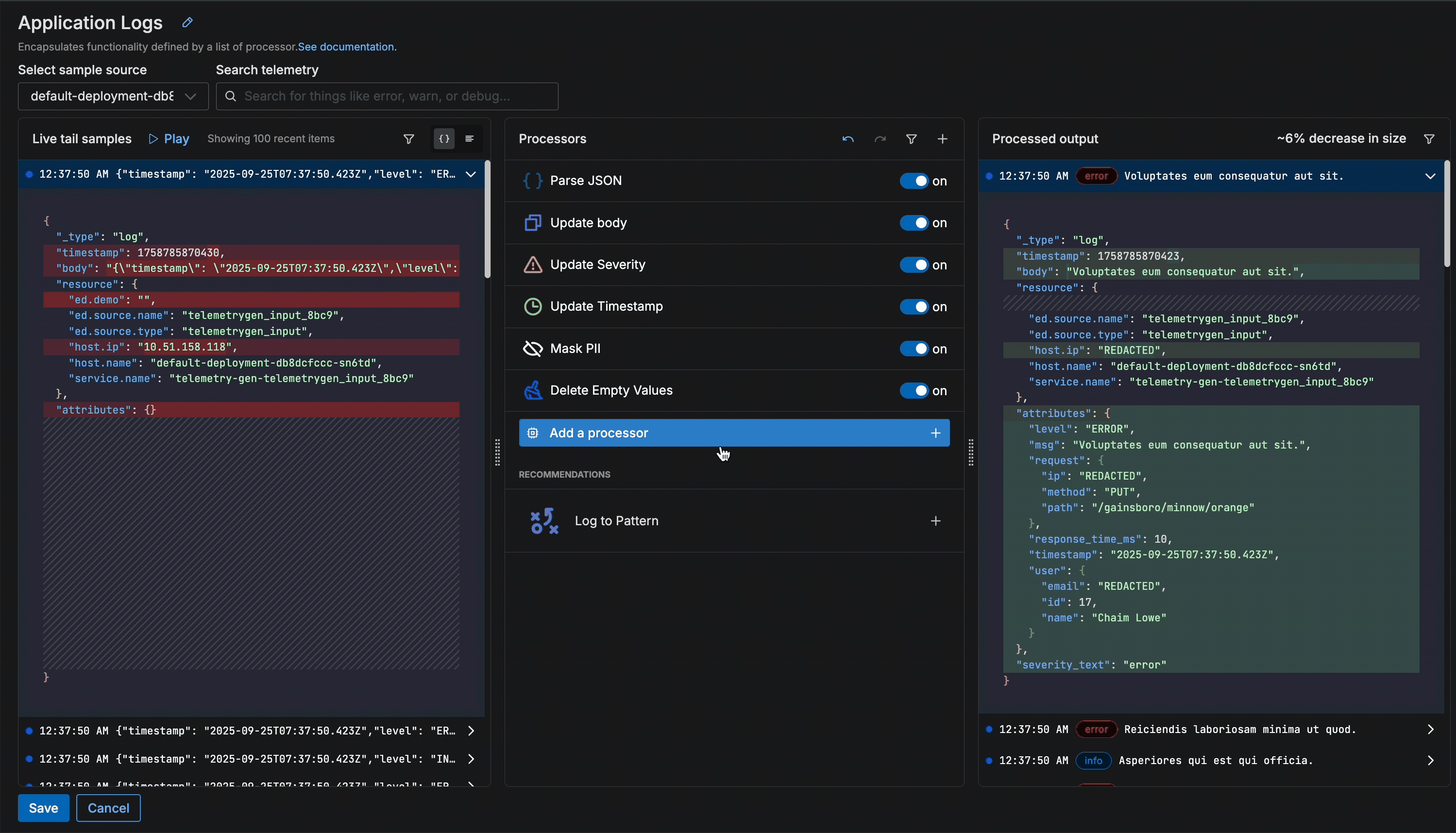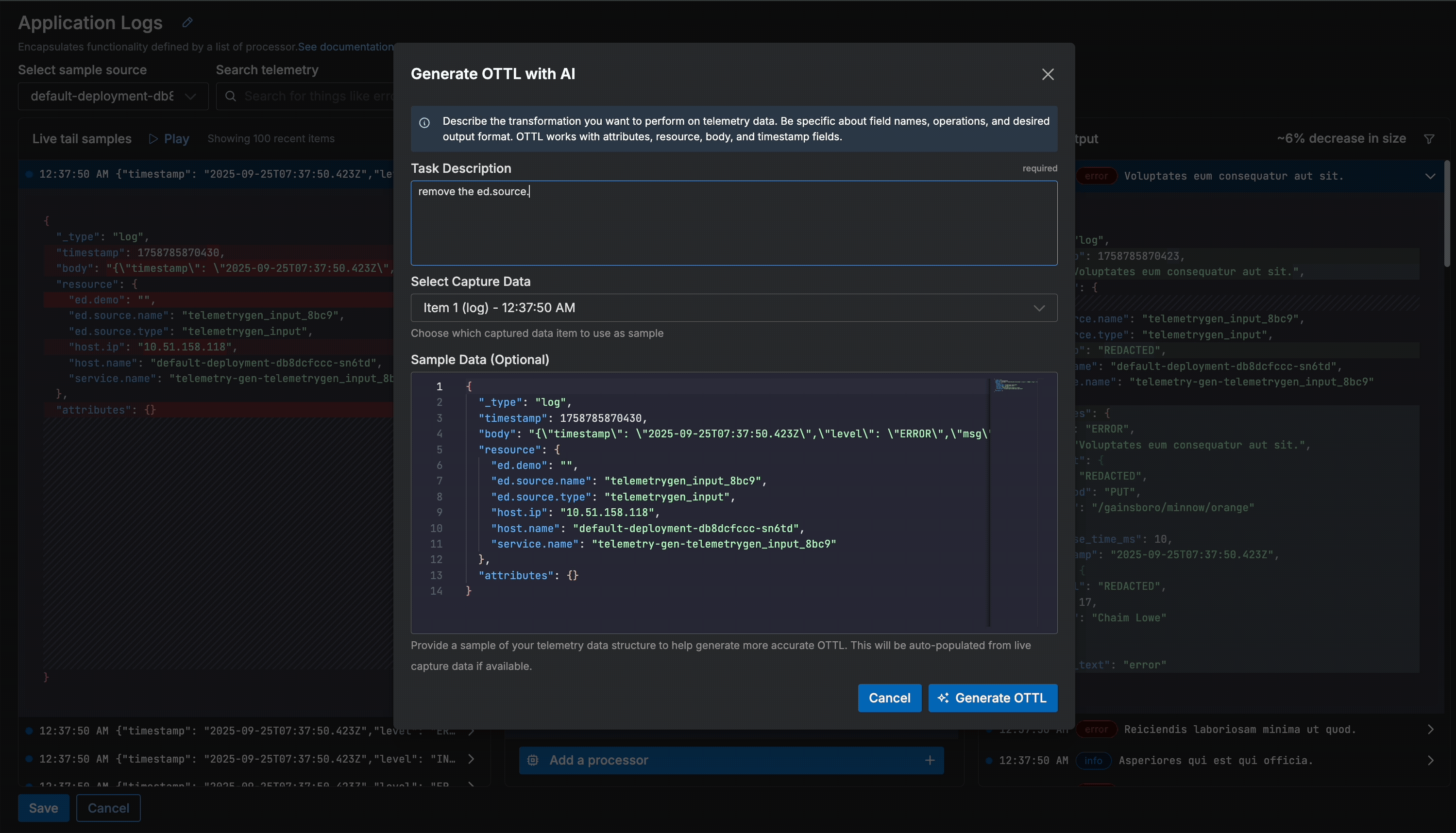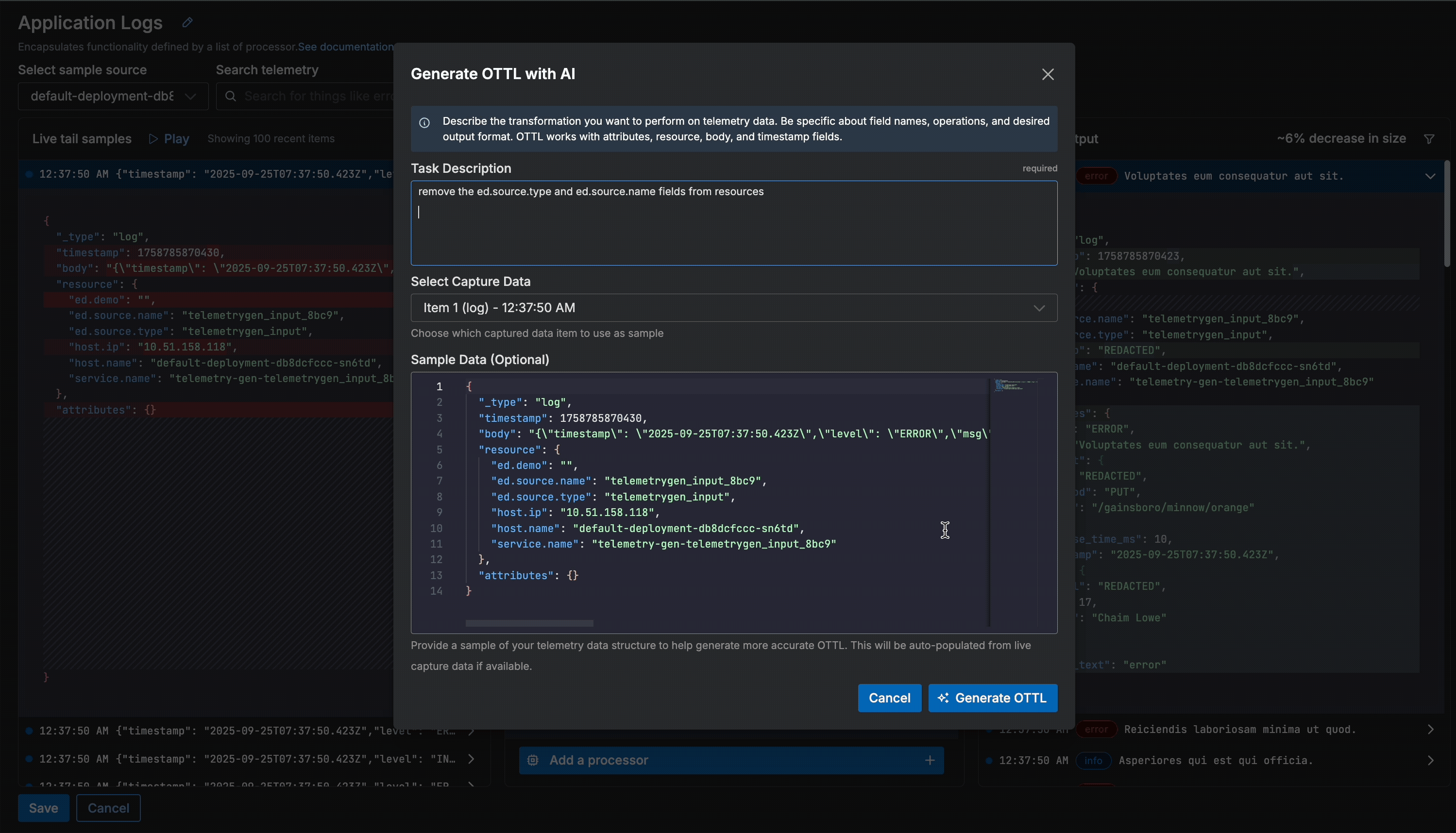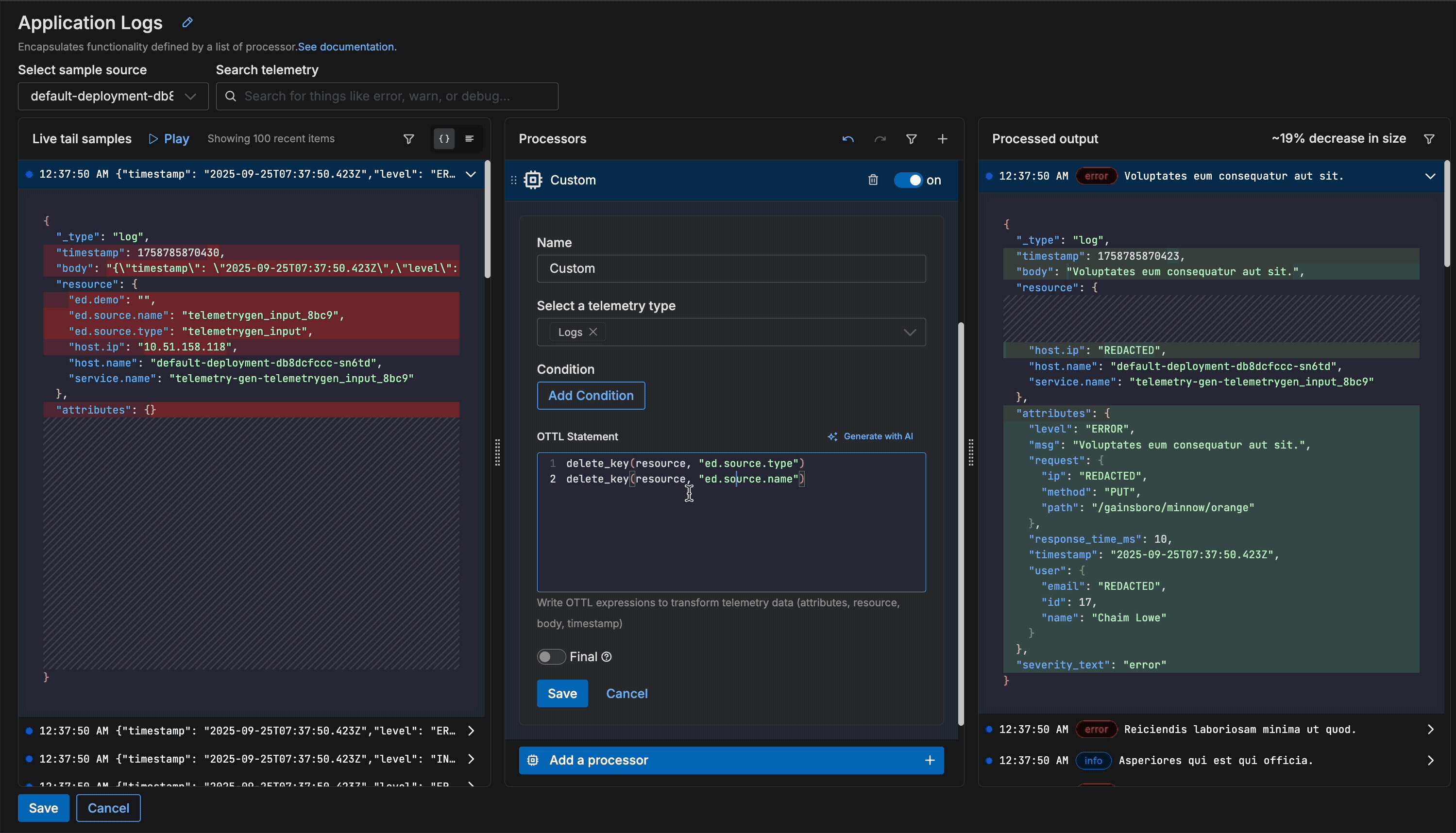
Once complete, you can see both the OTTL statement that was generated and how it modified the data. In this case, our pipeline successfully generated the correct statement and removed the two “ed” resource fields from our logs using the “delete_key” function. From here, we can confirm the changes locally before deploying the new pipeline configuration.
Conclusion
With intelligence built directly into the pipeline, Edge Delta enables teams to turn raw telemetry data into fully structured, optimized streams with just a few clicks and plain language instructions. By automating data parsing, masking, enrichment, and optimization, Edge Delta’s AI-powered Telemetry Pipelines eliminate the burden of manual configuration, so teams can focus on what matters most: deriving insights and resolving incidents faster.
To explore our intelligent Telemetry Pipelines for yourself, visit our free, interactive Playground environment or start a free trial.



