


ClickHouse is an open source column-oriented database management system known for its blazing fast online analytical processing (OLAP) capabilities on massively large datasets. At Edge Delta, we use it extensively across all our log data to store and query logs, especially for full-text search.
Every day, Edge Delta ingests petabytes of data to deliver real-time observability and actionable insights to our customers. Managing data at this scale is no small feat, so optimizing our ingestion and querying processes is critical to ensure our product remains reliable and efficient.
Recently, we hit a surprising speed bump with one of our query optimization techniques and, as a result, query times began to drag.
In this blog post, we’ll share how we:
- Uncovered the root cause in ClickHouse
- Targeted a fix for implementation
- Dramatically improved both query speed and resource utilization
Pinpointing a Tokenizer Glitch in Massive Searches
We first realized something was off when our larger log searches — spanning tens of terabytes or more — started running abnormally long. Even worse, these queries were consuming almost all the CPU available to them, threatening to bog down other critical processes. Intrigued (and a bit alarmed), we launched a deep investigation into ClickHouse’s full text skip-index mechanism.
Before going further, let’s quickly cover what skip indexes are in the context of ClickHouse. Skip indexes are structures that enable ClickHouse to skip reading significant chunks of data during query time. Well defined skip indexes are powerful for streamlining database read operations — particularly for large queries — as the more data ClickHouse must read, the longer the query takes.
At Edge Delta, we use a particular type of skip index, called the tokenbf index, which works by tokenizing both the stored data and the query input, and then using a bloom filter to determine if data related to the query exists in a particular data block. This technique is highly effective for full-text search queries, like the ones many of our customers run daily.
By combining query profiling data from ClickHouse’s system.query_log table with our own performance tracing tools, we noticed the tokenbf index wasn’t skipping records at all, even for searches on rare text snippets — a clear red flag. The index was supposed to optimize queries by bypassing irrelevant data, yet it wasn’t doing that at all! Tracing the problem further, we discovered a bug buried within the tokenizer logic itself, which was preventing proper tokenization of certain terms. This hidden glitch explained why our high-volume searches were grinding to a halt — and set the stage for a much needed fix.
Detailed Analysis
Our first step was to validate whether the issue lay in how queries interacted with the indexing mechanism, or if it stemmed from the optimization steps ClickHouse performs to prevent high rates of false positives in bloom filters, particularly when working with high cardinality fields and common search terms. We hypothesized that the problem could be tied to either:
- the distribution of data across ClickHouse
- the indexing logic
- a mismatch in how the tokenizer processed certain patterns.
To eliminate potential false positives we devised a series of controlled experiments, including simulated query workloads and targeted stress tests, on both common and rare search terms.
After determining that the issue wasn’t related to the dataset’s structure or distribution, we shifted our focus to the tokenbf index and its interaction with the tokenizer logic. Specifically, we scrutinized the behavior of the index during LIKE pattern searches, which many of our customers rely on for their log queries.
It was during this deep dive that we uncovered the critical bug in the tokenizer logic. The issue caused the tokenizer to incorrectly skip the first and last tokens in the search query. This flaw was particularly problematic because the majority of our customers’ searches involve one or two terms — precisely the type of queries most affected by the bug.
For example, a search like LIKE '%error%' would fail to properly tokenize the prefix “LIKE” and suffix “%error%” tokens, leading to inefficient index utilization and a significant slowdown in query performance. This misbehavior directly explained why searches on seemingly rare terms, in particular, were taking an unusually long time to complete.
Implementing the Fix
Pinpointing the tokenizer bug was by far the most challenging part of this process. Once identified, we shifted our focus to implementing an effective remedy.
The first step was to modify the LIKE tokenizer logic within the tokenbf index to ensure that all search terms, including the first and last patterns, were properly segmented. This involved refining the token extraction algorithm to handle edge cases where prefixes and suffixes were previously skipped.
To address this, we introduced a minor but critical change in the tokenization function, which ensured complete coverage of all patterns in a query. This change dramatically improved index utilization and enabled tokenbf to skip irrelevant data effectively even for single-term or two-term queries — a common use case for our customers.
Additionally, we submitted a pull request to the ClickHouse project to contribute the fix upstream, so future releases of the system benefit from this improvement.
Results and Impact
To validate the fix, we wrote unit tests for the updated tokenizer, covering edge cases like searches with special characters, prefixes, and suffixes. We also ran integration tests in our staging environment to verify the performance improvements on real-world workloads. These tests confirmed a significant drop in query execution time and CPU usage for high-volume log searches, while maintaining backward compatibility with existing queries.The result was a robust and efficient solution that restored the expected performance of the tokenbf index, and directly improved our customers’ search experience.
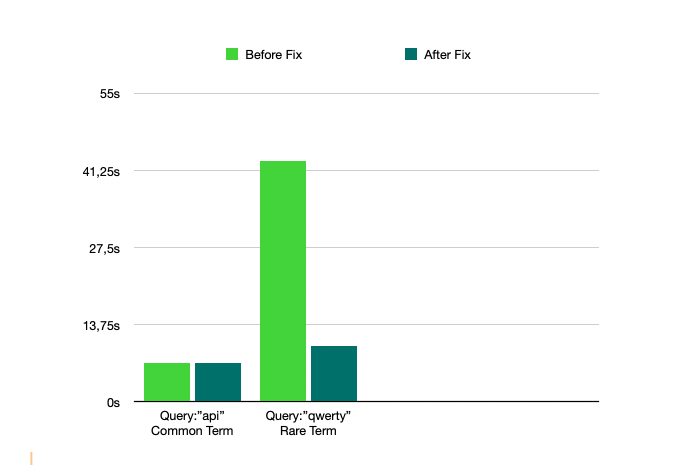
Note: The speed-up is more pronounced for longer search durations with rare terms, as in those cases the fix allows the tokenbf index to skip most granules. This results in similar query times regardless of data volume. Previously, downloading and processing larger datasets led to linearly increasing query times and resource intensive slowdowns.
Lessons Learned
This experience emphasized the importance of continuously monitoring query performance, even for mature and well established systems like ClickHouse. Additionally, it reinforced how critical it is to explore and understand open source codebases — often, small inefficiencies can become major performance bottlenecks at scale. Lastly, working closely with the open source community provided valuable feedback and validation for our approach.
Driving Real-Time Performance at Scale
At Edge Delta, scaling for real-time observability demands not only powerful infrastructure but also a willingness to dig deep into the root causes of performance bottlenecks.
Our investigation into ClickHouse’s tokenizer glitch was a testament to this commitment. By pinpointing and resolving a subtle yet critical bug in the tokenbf index, we achieved a significant improvement in query efficiency — reducing both latency and resource usage for searches spanning tens of terabytes of data or more.
This fix not only restored expected performance, but also underscored the importance of continuously optimizing our systems as we push the boundaries of data volume and query complexity.
With a stronger and more reliable infrastructure in place, we’re better equipped to deliver the real-time insights our customers rely on, ensuring smooth operations even at massive scale.
Looking ahead, we remain dedicated to maintaining peak performance while contributing to the open source ecosystem that makes innovations like these possible. By sharing our findings and improvements, we hope to help others in the community overcome similar challenges and drive the next wave of real-time data analytics.



