


Amazon Athena is fast, flexible, and serverless. It lets you query data in S3 with nothing but SQL. No clusters to manage, no provisioning delays. Just point, query, and go.
But speed and simplicity come with a price. Athena charges for every terabyte scanned, and that number adds up fast when hitting raw, uncompressed files or skipping smart partitioning. The tool isn’t the problem. It’s how you use it.
Athena rewards good data hygiene and punishes inefficiency. Query clean, compressed, and well-partitioned data and your costs stay low. Get lazy, and you’ll pay for every extra byte.
This guide will show you exactly how Athena charges you, where most teams go wrong, and how to squeeze real performance out of every dollar. If you’re using Athena or thinking about it, read this before your next query hits production.
What is Amazon Athena?
Amazon Athena is a serverless, interactive query service that lets you analyze data directly in Amazon S3 using standard SQL. There’s no infrastructure to set up or manage.
Under the hood, it’s powered by Presto, the high-performance distributed SQL engine used by Facebook and other data-heavy enterprises.
Athena works on a pay-per-query model: you’re charged $5 per terabyte of data scanned. That means the less data your queries touch, the less you pay (regardless of how complex the logic is).
It’s built for speed. You can connect Athena to your S3 buckets, define your schema via AWS Glue or manually, and start running SQL almost instantly.
There’s no need to load or transform data into a traditional data warehouse. It’s ideal for ad hoc queries, log and clickstream analysis, data lake exploration, and feeding business intelligence tools like Amazon QuickSight or Tableau.
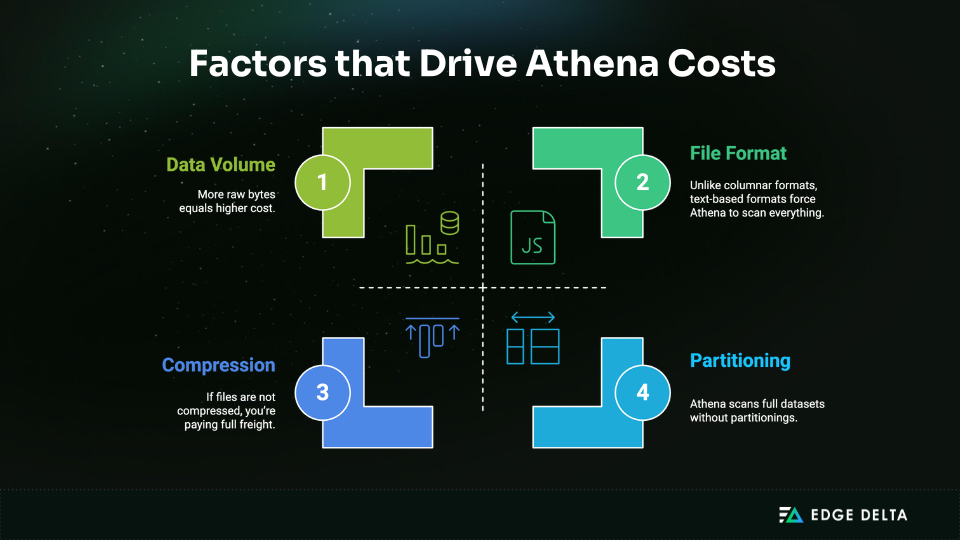
Athena supports multiple formats: CSV, JSON, ORC, Avro, and Parquet. But how you store that data matters. Compressed columnar formats like Parquet drastically reduce the amount of data scanned and, in turn, the cost.
The catch? Athena doesn’t limit what you scan; you do. Query a poorly partitioned 20TB dataset with a lazy SELECT *, and you’ll get your answer fast, but you’ll also get a massive bill. Athena’s real power is shown when paired with disciplined data structuring, smart partitioning, and efficient querying.
If you use it right, Athena will become one of the most cost-effective analytics tools on AWS. Use it wrong, and it is a silent budget sink.
How Athena Charges You
Athena’s pricing model is simple: you pay $5 for every terabyte of data scanned. There are no upfront costs, no server fees, and no minimums. Query once, pay once. But that simplicity hides a reality: your cost is entirely tied to how efficiently your data is structured.
What drives Athena’s costs?
Several factors directly influence how much data gets scanned with every query:
Regional Price Differences
Pricing can vary slightly depending on the AWS region. For example, $5 per TB is standard in USE-east-1. However, some regions (like Asia Pacific or South America) may run slightly higher.
Always check the region-specific pricing before scaling workloads.
Pro Tip*: More data scanned means spending more money burned. Optimize early.*
Athena will not warn you before it scans. It does exactly what you ask and bills you for each byte that you consume. That is why smart data structuring, compression, and targeted querying are more than just best practices. They’re cost control mechanisms.
Step-by-Step: Analyzing Data in S3 Using Athena
It is quick and easy to set up Athena, but setting it up the right way takes planning. To get quality performance at no additional cost, here’s what you should do:
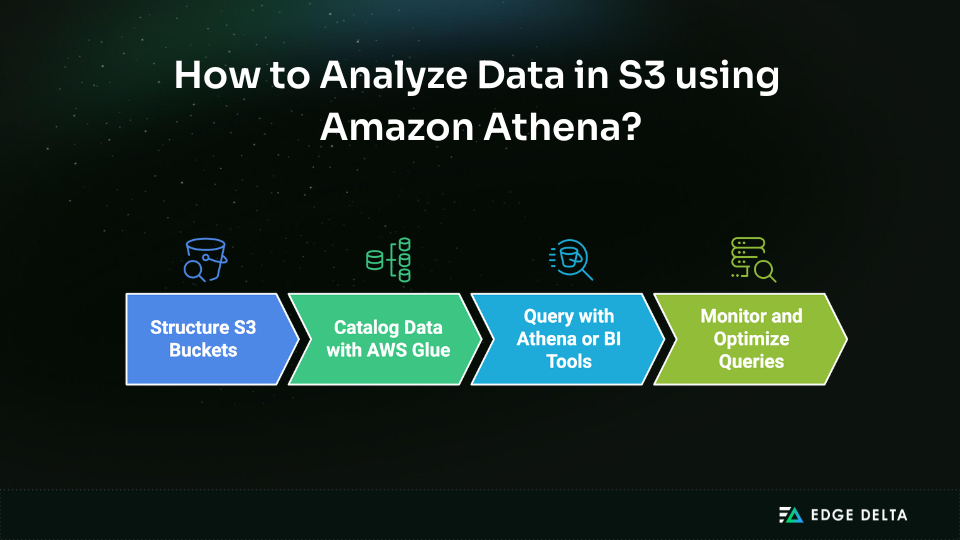
Step 1: Structure Your S3 Buckets with Purpose
Structure matters. Athena treats S3 paths like virtual partitions, so how you lay out folders directly affects performance and cost. Use a consistent folder structure that reflects your query patterns.
s3://your-bucket/logs/year=2025/month=03/day=28/
This layout lets Athena prune unnecessary data using partition filters, scanning only what you need.
Step 2: Catalog Your Data with AWS Glue
Athena doesn’t infer schema on the fly. You need a table definition. Use AWS Glue Data Catalog to register datasets and manage metadata.
- Create crawlers to scan and catalog your files automatically.
- Glue supports schema versioning and works across AWS analytics services.
Cataloged tables make querying consistent and reusable, especially across teams and tools.
Helpful Article
AWS Glue gives you structure, but bloated logs still break budgets. Take a smarter route and streamline your logs at the source for clean data pipelines and lean cost profiles.
Step 3: Query with Athena or BI Tools
Once tables are in place, go to Athena’s query editor. Then, run SQL from the CLI or connect BI tools like Amazon QuickSight or Tableau.
Here’s a sample query over partitioned Parquet logs:
SELECT user_id, event_type, event_time
FROM logs_db.event_logs
WHERE year = ‘2025’ AND month = ’03’ AND day = ’28’
LIMIT 100;
Why it works:
- Targets specific partitions → minimal data scanned
- Selects only needed columns → lower cost
- Uses LIMIT → great for dev or sampling
Step 4: Monitor and Optimize Your Queries
Track query execution in the Athena console or via Amazon CloudWatch. Pay attention to:
- Data scanned (bytes): The direct cost driver
- Execution time: Useful for tuning partitions or SQL logic
- Failed queries: Often caused by schema mismatches or missing partitions
Use EXPLAIN statements to check query plans before running them and spot inefficiencies early.
Cost Optimization Strategies
Athena bills you for every byte it scans, not how long a query runs or how complex it is. That means cost control is about data hygiene and smart querying rather than computing power.
Below are five essential tactics to cut query costs without sacrificing performance:
Use Compressed Columnar Formats
Let’s get this out of the way: CSV is killing your budget.
CSV and JSON are easy to work with, but they’re bloated, row-based, and lack compression. Every Athena query that touches them scans full rows—even if you only need one column. That’s expensive and inefficient.
Parquet and ORC, on the other hand, are columnar. They are compressed formats designed for analytic workloads. They store data by column instead of row to let Athena read only the relevant parts of your files.
Real-world impact: A raw 10 TB dataset in CSV can shrink to around 1 TB in Parquet, depending on the schema. That’s a cost shift from $50 per query to $5.
Athena is optimized for these formats. If you care about cost, start with Parquet or ORC. You’ll pay less, scan less, and query faster.
Partition Your Data Smartly
Partitioning is Athena’s secret weapon, and it will be your cost-saving best friend.
Partitions split your dataset into smaller, logical segments (e.g., by date, region, or customer ID). Athena only scans partitions that match your query, skipping everything else. No partitions? Athena scans everything.
Say you’re storing access logs:
s3://my-logs/year=2025/month=03/day=28/
A query like this will scan only March 2025 instead of the full dataset:
SELECT * FROM logs WHERE year = ‘2025’ AND month = ’03’;
Partitioning by day can turn a 30 TB monthly scan into a 1 TB daily scan, cutting costs by 96%.
Too many small partitions can slow queries, so strike a balance. Partition by high-selectivity fields and avoid over-partitioning.
Use Caching and Result Reuse
Athena can reuse results from previous queries, but only if nothing has changed.
If you run the exact same query twice (same SQL, same data), Athena pulls the cached result instead of re-scanning. This is automatic and costs $0. Just don’t disable result reuse in your settings.
You can also store query outputs in S3 (in compressed formats) and reference those in downstream queries or dashboards. It’s cheaper to query a pre-filtered dataset than to reprocess the raw data every time.
Pro-Tip*: Set S3 lifecycle policies to auto-archive old query results and avoid long-term storage costs.*
Limit Query Scope (SELECT Smartly)
Athena can scan everything, but it doesn’t mean it should. Stop the habit of using SELECT * for every query. It tells Athena to read every column in every row.
Instead, only select the columns you need. This is especially important with wide tables and large datasets. Also, use LIMIT when exploring data or testing queries:
SELECT user_id, event_type FROM logs LIMIT 100;
This caps your scan, saving both time and money in dev or staging environments. Small tweaks here lead to major cost savings over time, especially in production workloads.
Monitor and Optimize Query Plans
You can’t fix what you don’t monitor. Use the EXPLAIN keyword in Athena to break down your query plan. It shows how much data will be scanned, which partitions are hit, and how efficient your SQL is before you run the query.
In production, monitor top queries using:
- Athena Console: Query history, data scanned
- Amazon CloudWatch: Query metrics, failures, performance bottlenecks
- AWS Cost Explorer: Drill down on Athena-specific spend
If you notice repeated heavy scans, look at:
- File formats – CSV? Convert.
- Partitions – Missing or misaligned?
- Query structure – SELECT * or redundant joins?
Tuning these elements can easily cut query costs in half or more.
Pro-Tip
CloudWatch isn’t free, and it’s definitely not frictionless. Time to ditch centralized monitoring pain and level up your visibility.
Hidden Cost Traps to Avoid
Athena’s pricing of $5 per terabyte is clear as day (AWS Pricing). But how do costs add up? That’s where teams slip. Below are the most common and expensive mistakes that quietly drain budgets.

- Scanning Uncompressed, Raw Files
Dumping CSVs or JSON into S3 is easy, but Athena charges you for every byte it reads. Uncompressed data balloons your scan size.
Always go for columnar, compressed formats like Parquet or ORC for analytics use cases. A 100GB CSV might shrink to 10GB in Parquet, and that’s a $0.50 query.
- SELECT * on Unpartitioned Datasets
Running SELECT * across a wide, unpartitioned dataset is a classic rookie move and an expensive one. Athena scans every row and every column unless told otherwise.
Query only the columns you need and use WHERE clauses that filter on partition keys.
- Neglected Glue Data Catalogs
A stale or broken schema in the AWS Glue Data Catalog can result in failed queries, full-table scans, or missed partitions.
Keep your Glue tables synced with your data. Use crawlers or versioned schemas to secure query accuracy and efficiency.
- Too Many Interactive Queries
Interactive querying is powerful, but overusing it for scheduled reports or monitoring workloads adds unnecessary cost.
Offload recurring queries to scheduled Athena queries or ETL pipelines. Cache results when real-time data isn’t needed.
- Storing Results Without Lifecycle Rules
Athena stores query results in S3. Over time, this becomes a silent cost creep, especially if results are large and rarely accessed.
Set S3 lifecycle policies to move results to Glacier or delete them after a defined period. Use dedicated buckets for query outputs and monitor their size regularly.
Athena doesn’t penalize bad habits up front, but your AWS bill will. Treat every query like it costs money because it does.
Tools & Integrations to Enhance Efficiency
Amazon Athena works best when it’s part of a well-oiled data stack. The right integrations don’t just streamline your workflow. They help you control costs, enforce structure, and get more out of every query.
AWS Glue: Your Schema Backbone
Athena reads data, but it needs to know what that data looks like. AWS Glue acts as a central metadata catalog, defining table structures, partitions, and schemas.
It also handles light ETL (Extract, Transform, Load) jobs to clean and prep raw files before they hit Athena. Glue lets you automate schema updates and discover new partitions without manual overhead.
Bonus: Glue integrates natively with Athena, making schema-on-read feel almost like a traditional database.
Visualization Tools: Turning Queries into Insight
Pair Athena with Amazon QuickSight for dashboards, or plug into third-party tools like Redash, Apache Superset, or Tableau via JDBC/ODBC connectors.
Those tools run Athena queries under the hood, so structuring them efficiently matters. Dashboards that pull wide queries on refresh can burn through terabytes if you’re not careful.
S3 Lifecycle Policies & Storage Classes
Keep your data lake lean. Use S3 lifecycle rules to archive or delete stale data and move infrequently accessed files to cheaper storage classes like S3 Glacier or S3 Intelligent-Tiering.
This won’t directly cut Athena query costs, but it reduces clutter, helps enforce data hygiene, and keeps you from scanning irrelevant files.
Conclusion
Amazon Athena gives you fast, serverless access to S3 data using nothing but SQL. It’s powerful, flexible, and scalable, but it’s not plug-and-play cheap. With a pricing model based on data scanned, every query has a dollar value attached.
The difference between a $0.05 query and a $50 one often comes from basic planning. The more efficient your setup, the more value you get. The lazier your structure, the faster your costs pile up.
If you treat Athena like a one-click analytics tool, you’re leaving money on the table. But if you treat it like an engine that rewards precision, you’ll win on speed, scale, and spending.
Cheap queries require smart setups. Know your data. Structure it right. Query with intent.
FAQs
Is Athena cheaper than Redshift?
Yes, Athena is usually cheaper for ad-hoc queries; Redshift is more cost-effective for large, frequent workloads.
How much does an S3 bucket cost?
Creating an S3 bucket is free. However, you will need to pay for stored data, requests, and data transfer.
Can I use Amazon S3 for free?
Yes, AWS Free Tier offers 5GB storage, 20,000 GET, and 2,000 PUT requests monthly for 12 months.

