


This is the first entry in a new blog post series on data normalization. Stay tuned for future posts on this topic.
Many organizations collect data that comes in a variety of formats from multiple sources, making it challenging to build a unified, actionable view of their environments. Teams lack visibility into how well their systems interact, especially when data labels vary across different parts of the infrastructure — like “host” in one log and “hostname” in another. Without proper data normalization, your teams risk dealing with disjointed insights, which leads to slower troubleshooting, inefficiencies, and missed opportunities to optimize operations.
To solve this problem, Edge Delta gives teams the tools they need to normalize data directly within the Telemetry Pipeline, alleviating the need to make changes at the source. By empowering you to make non-breaking changes in the Telemetry Pipeline itself, it allows you to move more quickly and with more flexibility than ever before.
Instead of making upstream changes, Edge Delta provides flexibility by allowing teams to standardize or enrich metadata during processing, directly within the pipeline. With features like intelligent pipeline processors, you can easily unify different naming conventions across logs, metrics, and traces. This organizational strategy helps teams focus on gaining insights rather than dealing with format inconsistencies.
In this post, we’ll cover:
- How Edge Delta pipelines give teams the flexibility to normalize data within the Telemetry Pipeline using the OpenTelemetry standard.
- Practical examples of adding and transforming metadata in your data streams.
- How Edge Delta’s approach to data normalization improves efficiency, accelerates incident response, and future-proofs your observability strategy.
What is Data Normalization?
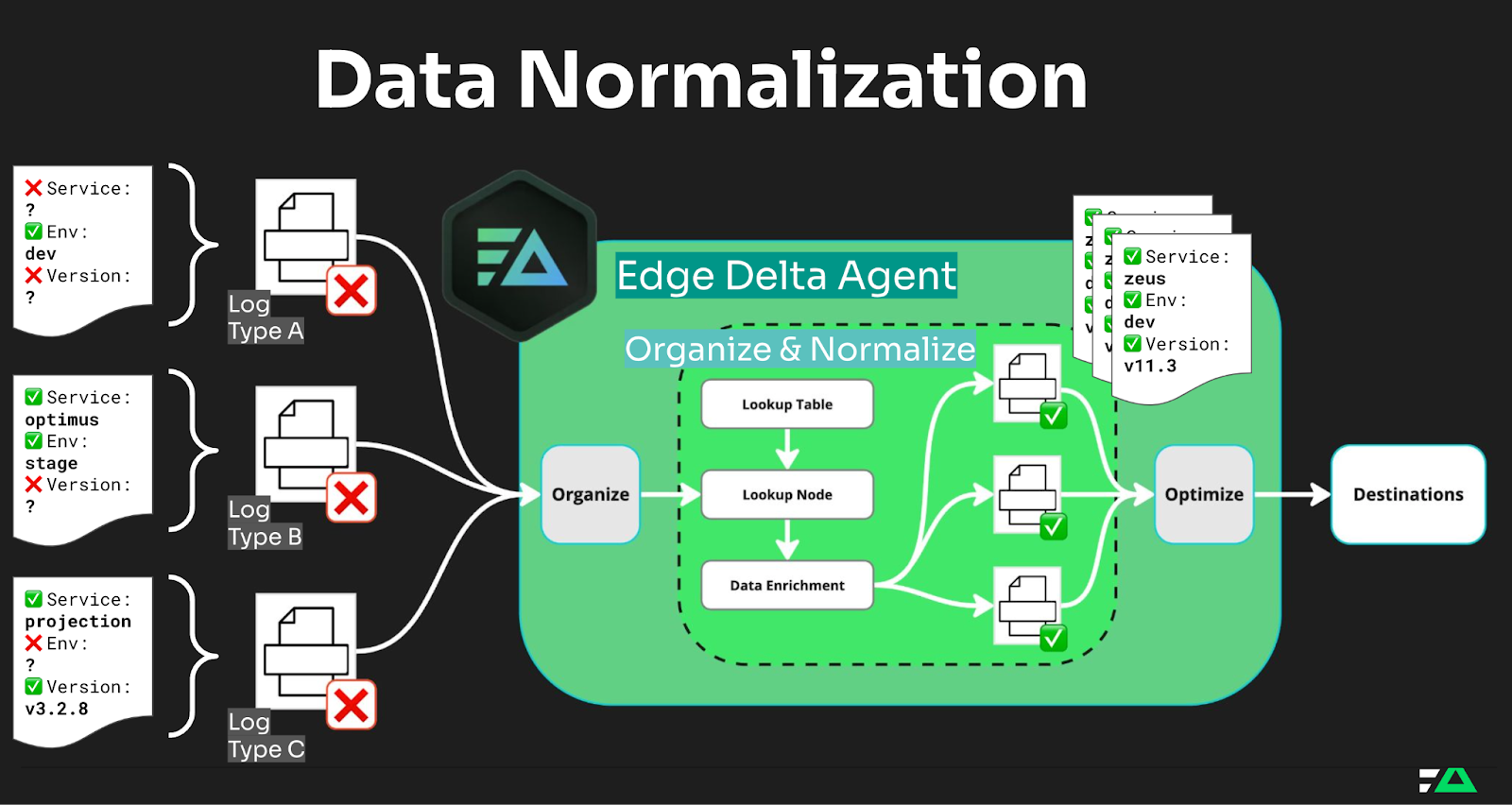
Data normalization is the practice of transforming data into a common, consistent format. In observability, this often means reformatting log entries, aligning metrics labels, or standardizing traces so they can be analyzed collectively, regardless of their original source.
When you ingest data from diverse systems — like cloud infrastructures, third-party applications, and on-prem services — it often comes with its own unique format. Data normalization brings order to this chaos, enabling a unified view across disparate datasets.
Edge Delta natively uses the OpenTelemetry (OTEL) standard as soon as telemetry data is ingested into our pipeline, and sticks to OTEL standards throughout. This ensures that data normalization, enrichment, and analysis processes adhere to an industry-standard approach, making integration seamless and consistent.
Why Does Normalization Matter?
Imagine troubleshooting a complex issue involving multiple services. If your logs have inconsistent field names, metrics that vary in labels, or traces that follow different conventions, you’re left trying to compare apples to oranges. This lack of consistency adds friction to incident responses, delays root cause analysis, and ultimately affects system reliability.
As an example, consider a large organization where multiple teams have their own deployment methodologies. Each team may use different tagging schemas for their logs and metrics, despite a standardized schema being laid out by the SRE team.
Without data normalization, correlating data across these different systems becomes a cumbersome and error-prone process. This scenario is all too common in enterprises that have grown rapidly or have distributed teams working independently. Data normalization helps mitigate these inconsistencies, making it easier for the entire organization to have a cohesive view of their systems.
Data normalization helps:
- Reduce Noise: Standardized data allows intelligent filtering and aggregation, which reduces irrelevant noise and lets you focus on what matters most.
- Accelerate Incident Response: When data is consistent, teams can identify and address incidents faster — spending less time converting formats and more time solving problems.
- Enhance Automation: Machine learning models and automation workflows thrive on consistent, clean data. Normalization makes it easier to deploy anomaly detection, automate remediations, and establish predictive analytics.
What Are the Benefits of Data Normalization Combined with Telemetry Pipelines?
For years, the industry has encouraged teams to bring data management as close to the source as possible. While this approach has its benefits, it also poses challenges, especially in the context of Telemetry Pipelines.
Consider a scenario where a development team needs to update tagging to align with a new compliance requirement. Traditional approaches often require changes to be made upstream, which can introduce delays and involve extensive change management. This can increase the risk of introducing errors into other systems
Edge Delta provides an alternative approach by allowing teams to take control of data normalization, enrichment, and sanitization directly at the point of data processing. For example, a development team could use Edge Delta to add tags or adjust data scales (e.g., normalizing significant digits) without relying on upstream teams. This allows the security team to apply necessary compliance tags, while an SRE team can adjust other metadata as needed — without affecting each other’s work.
This capability limits the blast radius of changes and ensures that teams can make adjustments on the fly, without waiting for upstream systems to adapt. By managing normalization changes directly within the pipeline, Edge Delta helps teams move faster, facilitating more responsive operations and allowing organizations to keep pace with changes more effectively.
Normalization in the Edge Delta Ecosystem
At Edge Delta, data normalization is a fundamental part of how we help teams make sense of observability data — no matter where it comes from.
Unlike traditional approaches that require data to be normalized before ingestion into the pipeline, Edge Delta enables teams to take ownership of data normalization, enrichment, and sanitization directly at the point of data ingestion. This gives teams the ability to adjust and standardize data as it is collected, ensuring a more flexible and dynamic approach to data management. With the addition of Edge Delta lookup tables, customers can quickly implement data normalization and sanitization processes across their organization, even when adopting new standards like the JSON Schema.
Our platform leverages Telemetry Pipelines that can normalize data that you can’t control at the source. This is particularly useful in environments where different teams have varying conventions or in cases where data collection is distributed across disparate systems and standards.
With Edge Delta’s Telemetry Pipelines and lookup tables, you can easily add missing metadata, align existing fields to a unified schema, or even sanitize data to adhere to organizational standards.
For instance, using Edge Delta’s OTTL transform node, you can compare incoming data against your own JSON Schema definition to validate attribute strings, integers, or other data types. This allows you to ensure that each data attribute conforms to the expected type before it moves further through the pipeline, providing both normalization and quality control.
And if your organization is adopting the JSON Schema standard, lookup tables make it straightforward to ensure compliance by mapping different field names and standardizing metadata consistently. For instance, if one team tags a field as “host” and another uses “hostname,” Edge Delta’s pipeline processors and lookup tables make it straightforward to normalize these fields into a consistent format, ensuring compliance with new standards like JSON Schema, and allowing organizations to quickly standardize across teams.
By performing normalization within the Telemetry Pipeline, Edge Delta ensures that all data streams — whether they’re Kubernetes logs, Prometheus metrics, or event data from your cloud provider — are standardized before they reach your central systems. This guarantees a holistic view, enabling you to generate dashboards, trigger meaningful alerts, and conduct seamless end-to-end tracing.
Future-Proofing Your Observability Strategy
Data normalization isn’t just about quick wins today — it’s about building a resilient foundation for future growth. As systems evolve, new services get onboarded, and data sources multiply, normalization ensures your observability strategy remains agile and scalable.
By treating data normalization as a core tenet of your observability practice, you can future-proof your monitoring capabilities and maintain clarity amid complexity.
At Edge Delta, we believe that normalization isn’t a burden — it’s an opportunity. It’s a chance to unlock hidden insights, empower faster decision-making, and make your data work harder for you.
Whether you’re just starting your observability journey or looking to enhance your existing capabilities, Edge Delta’s edge processing capabilities help you normalize data effortlessly, letting your teams focus on what matters most: keeping your systems healthy and your customers happy.
Ready to learn more? Start a free trial to see how Edge Delta can help you normalize data at scale and supercharge your observability efforts, or hop into our Playground to get hands on with the product.



