


Distributed systems generate millions of log lines every minute. Manually searching through that volume wastes hours filtering noise, hides critical signals in plain sight, and drives incident resolution times higher. Grep-based workflows worked for monolithic applications, but they break down in cloud-native architectures built on ephemeral services and constant change.
AI changes the fundamentals of log analysis. Instead of relying on predefined patterns, models automatically detect anomalies, group related events without supervision, and surface causal relationships across the entire service topology. Teams move from reactive searching to proactive understanding.
The operational impact is measurable. Organizations commonly report 30 to 60 percent reductions in MTTR, investigation times cut in half, and log storage costs reduced by up to 25 percent.
In this article, we examine how AI transforms log analysis from an architectural perspective. We explain why manual approaches fail at scale, how AI separates signal from noise in high-volume log data, and how these capabilities translate into real operational value.
Key Takeaways
• Traditional log analysis fails in distributed systems because log volume grows faster than humans can process, making manual search impractical during incidents.
• The core limitation is cognitive. Engineers cannot reliably detect patterns or correlations when millions of log entries create overwhelming noise.
• AI shifts log analysis from manual searching to automated pattern discovery using clustering, classification, and anomaly detection.
• Natural language processing helps interpret unstructured logs by recognizing semantic similarities instead of relying only on exact text matches.
• Anomaly detection improves alert quality by learning normal system behavior and reducing false positives compared to static thresholds.
• Automated cross-service correlation speeds up investigations by identifying likely causal chains without manual timestamp matching.
• AI reduces MTTR and storage costs, but human oversight is still necessary due to model drift, bias, and the risk of incorrect conclusions.
Why Does Traditional Log Analysis Break Down at Scale?
Log volume quickly outpaces human analysis capacity. Every microservice you deploy multiplies log output. API calls generate logs. Database queries generate logs. Cache operations generate logs. Containers continuously spin up and down, each one logging its full lifecycle from start to finish.
A single user action that generated five log lines in your old monolith now triggers thirty services. Those thirty services collectively produce hundreds of log entries for that one action.
This isn’t wasteful logging or poor practices. It’s the observability cost of building distributed systems. The data volume creates a problem that manual search fundamentally cannot solve.
The difficulty also comes from data shape, not just scale:
- Unstructured logs force engineers to interpret free-text messages that resist consistent parsing.
- High-cardinality fields like request IDs, container names, and session tokens constantly change, making grouping and pattern recognition harder under pressure.
Log Volume Growth in Modern Distributed Systems
Cloud-native architectures produce exponentially more data than their monolithic predecessors.
A moderate Kubernetes cluster generates thousands of cluster events per minute on its own. Add your service mesh, serverless functions, and distributed tracing on top of that, and the volume becomes overwhelming quickly.
Microservices amplify the problem geometrically rather than linearly. Services talk to each other, and every interaction produces logs on both sides.
When you add services, you’re not just increasing individual log streams. You’re increasing the combinatorial interactions between all your services.
Annual log data growth rates exceeding 30% in cloud environments
Industry analyses of cloud observability trends report that log data volumes commonly grow by more than 30% year-over-year as organizations expand services and increase instrumentation coverage. Deployment frequency goes up. Observability coverage expands.
Logging verbosity increases to maintain visibility into increasingly complex distributed behavior. These factors compound rapidly, which is why teams struggle to keep pace even with improved tooling.
Compliance requirements also drive expansion. Audit trails, access records, and retention mandates often require teams to store more events than they would for operational purposes alone.
Manual review of millions of log entries during an active incident isn’t feasible. No team has that capacity, no matter how well-staffed.
Fun Fact
As of 2023, about 37% of enterprises were already ingesting more than a terabyte of log data per day, and many generate over 10 terabytes daily in large distributed environments. This illustrates how massive data streams have become in modern systems.
Human-Centered Search and Alerting Limitations
Manual analysis works at thousands of log lines. At millions, it collapses.
Human cognitive capacity has hard limits. Critical error patterns disappear into noise.
Search queries match irrelevant entries more often than meaningful ones. Investigation time is spent eliminating false leads instead of identifying root causes. This is not a training problem or a tooling problem. It is a fundamental capacity problem.
Static alerting makes the situation worse. Every threshold you configure requires ongoing maintenance as systems evolve.
Deployments continuously change behavior patterns, but alert rules remain frozen until someone updates them. Teams are forced to choose between nonstop alert noise or silent systems that miss real incidents.
Mean time to resolution increasing year-over-year in distributed systems
Mean time to resolution has increased year over year in distributed environments as service dependencies expand and investigations require analyzing more data across more systems.
Improved observability tools have not solved this problem. The primary bottleneck lies in investigation, not remediation. Engineers spend the majority of incident response time understanding what happened, not implementing fixes.
Log analysis dominates the investigation phase. Triage is where teams narrow scope across dozens or hundreds of services, and it is where most of the time is consumed. Even the fastest deployment pipeline cannot compensate for an hour-long triage process, and MTTR remains high.
The root cause is structural. Exponential growth in data collides with linear human capacity. Manual approaches cannot scale to meet this demand. AI addresses the problem at the architectural level through automated pattern recognition.
What Does “AI Log Analysis” Actually Mean?
AI log analysis isn’t a single technology. These systems combine several approaches:
- Statistical models establish baselines and flag deviations.
- Machine learning models use patterns from past logs to sort and group events.
- Language models interpret unstructured text by recognizing semantic relationships rather than numeric trends.
Within these categories, different techniques serve distinct purposes. Clustering combines related messages, classification predicts how bad an event will be, anomaly detection finds strange patterns, and natural language processing pulls structure from free-text entries.
Each technique solves a different problem in the log analysis pipeline, and they work best when used together.
Machine Learning Techniques Applied to Logs
Machine learning models look at past log data to find patterns and relationships that happen over and over again.
Instead of relying on predefined rules, they learn from past system behavior to surface structures that help teams understand what is typical versus unusual. This allows engineers to move beyond manual searches and focus on broader operational trends.
- Clustering helps group similar log messages so teams can quickly recognize common event types without reviewing individual entries.
- Classification models assign meaning to new events by predicting categories such as errors, warnings, or informational messages.
- Anomaly detection adds another layer by identifying behavior that falls outside learned patterns, often revealing emerging issues before they escalate.
These approaches change log analysis from seeking problems to looking for patterns ahead of time.
By learning from the data itself, machine learning models help reduce noise, highlight relevant signals, and give teams a clearer view of how complex systems behave over time.
Log pattern clustering using unsupervised learning models
Unsupervised clustering puts log messages into groups based on how similar they are, without needing labeled training data. These models understand that entries with the same tokens, timestamp patterns, or contextual cues generally refer to the same type of event, even if the language used is different.
The result is automatic template extraction. Thousands of unique messages collapse into a smaller set of recognizable patterns. Research on log clustering methods shows that unsupervised models reduce message complexity and make dominant event types easier to identify.
Instead of reviewing individual entries, engineers can analyze templates that summarize recurring behavior. This shift changes how investigations begin, making it easier to spot irregularities early.
Clustering helps teams focus on important differences and progress through investigations more quickly by cutting down on noise and bringing repeating structures to the surface.
Natural Language Processing for Unstructured Logs
Most log data is semi-structured text that includes variables, timestamps, and other indicators that make it easier for people to read. Because of this variability, it is hard to consistently parse with existing approaches.
NLP models treat logs as language rather than raw data, enabling systems to interpret meaning instead of relying only on exact matches.
Techniques like tokenization break messages into analyzable components, while semantic embeddings represent entries in ways that allow systems to compare intent rather than wording. This helps identify relationships that keyword searches often miss.
These features are especially helpful in production settings, where multiple services could use various terminology to describe the same occurrences. Dynamic features like stack traces or memory references are common in error messages, and the structure of the timestamp can change from one component to the next.
By normalizing these variations, NLP models recognize conceptually similar events despite textual differences. This allows teams to search and analyze logs based on context, which would be difficult to achieve with regex-based approaches alone.
NLP-based log parsing accuracy improvements reported in recent studies
Recent research demonstrates that NLP-based parsing regularly surpasses regex methods in retrieving structured information from various log formats.
Language models identify patterns in unstructured text even when message formats shift across services or evolve over time. This flexibility improves parsing accuracy where rule-based methods often fail.
Higher-quality structured data strengthens downstream analysis, enabling more reliable anomaly detection and cross-service correlation. Even small parsing improvements can significantly increase the quality of insights teams derive from their logs.
How AI Improves Signal Extraction from Logs
Signal amplification is the fundamental value here. Your logs contain critical information about system health, but operational noise buries that information completely under normal circumstances.
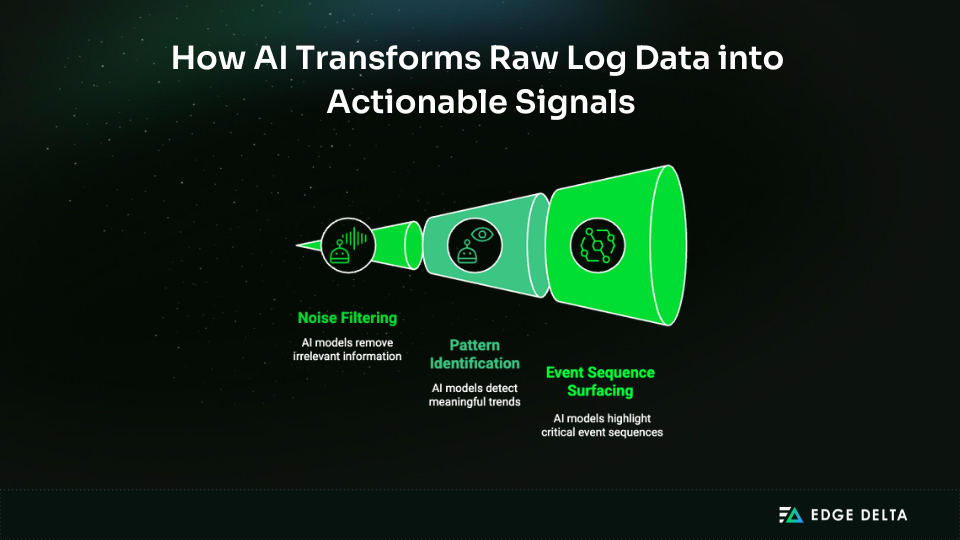
AI tools like Edge Delta’s AI Teammates filter out the noise, identify meaningful patterns, and surface the specific event sequences that matter when you’re investigating incidents. This transforms log analysis from a search problem into a signal detection problem, basically a different approach to the same data.
Traditional approaches assume you know what to search for. AI inverts that model entirely. Systems learn baseline behavior for your specific environment, then flag deviations automatically without you having to define what “normal” looks like in advance.
Anomaly Detection in Log Streams
Anomaly detection models identify events that differ statistically from established patterns. These may include novel error types that have not appeared before, unexpected spikes in warning activity, or unusual cross-service event sequences that fall outside normal system behavior.
Context awareness gives you the critical advantage over threshold-based alerting. Whether something counts as anomalous depends on multiple factors, as shown in the digram below:
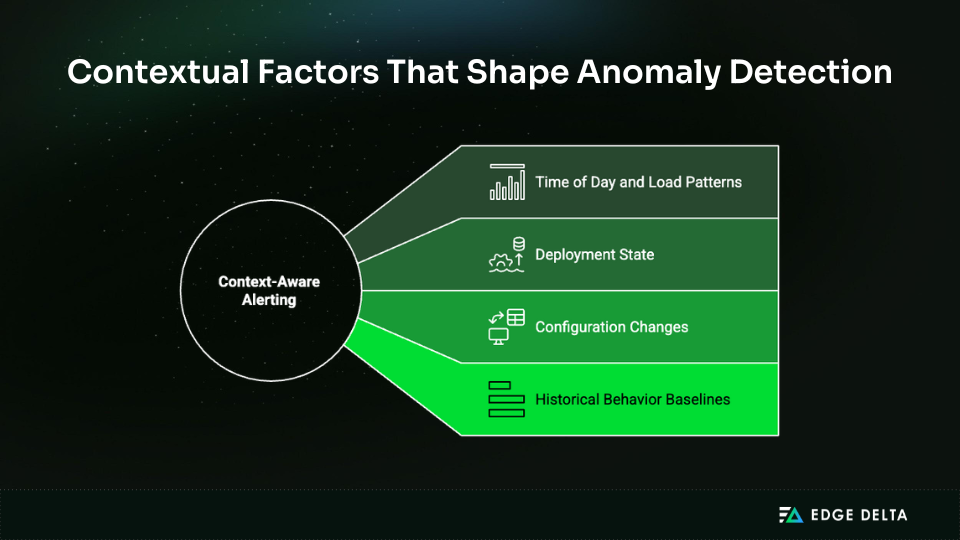
During high traffic, a 5% error rate might be totally acceptable. However, at 3 AM, when you expect almost no errors, it could be a symptom of major difficulties. Some forms of errors might be acceptable during deployments but not during steady state.
Machine learning models capture these contextual dependencies without manual configuration, which means your anomaly detection actually gets smarter over time instead of requiring constant threshold tuning.
Log anomaly detection precision improvements of 20–40% in ML-based systems
Research on machine learning–based log anomaly detection reports precision improvements ranging from 20–40% compared to static threshold methods.
In operational terms, higher precision implies fewer false positives, which lets teams focus on alarms that are more likely to be related to real issues. This saves time spent looking into regular system behavior caused by misconfigured warnings and lets you decide which situations need your urgent attention.
The impact becomes especially noticeable in environments with many services, where alert noise can otherwise slow response efforts.
Automated Log Correlation Across Services
Cross-service log correlation is definitively the hardest part of distributed systems debugging.
Service A throws an error. You need to know whether Service B caused it, whether Service C triggered the causal chain, or whether these events are completely independent. This is where understanding how logs, metrics, and traces work together in distributed systems becomes essential.
Without correlation, you’re investigating each possibility manually. Manual correlation means:
- Opening multiple log viewers
- Aligning timestamps by hand
- Matching request identifiers when they exist
- Tracing execution flow across service boundaries
The process is time-consuming and error-prone, and it gets exponentially harder as the service count increases.
AI models learn typical causal chains from your historical data. They identify statistical relationships between events across services, even when you don’t have explicit trace identifiers connecting them. This is particularly valuable in legacy systems or during migrations.
The models look for temporal patterns and event sequences that frequently occur together. They might discover that your payment service errors consistently appear 50 milliseconds after specific database timeout patterns.
You’d never spot that correlation manually across millions of entries, even if you were specifically looking for it.
Cross-service log correlation reducing investigation time by up to 50%
Studies on large-scale distributed systems indicate that automated log correlation can decrease inquiry time by as much as 50% by highlighting relevant occurrences across services.
By linking events that share timing or behavioral patterns, correlation narrows the number of systems engineers must examine, effectively collapsing the search space during incidents.
Instead of manually reviewing logs across systems to reconstruct what happened, teams receive pre-correlated sequences that highlight likely causal chains. This allows engineers to identify affected services and focus their analysis much sooner.
As a result, triage moves faster because teams spend less time searching and more time validating root causes, leading to quicker decisions about remediation.
How AI-Based Log Analysis Impacts MTTR and Operational Cost
You can immediately quantify the benefit of AI log analysis in two ways: it helps you fix problems faster and lowers the cost of your infrastructure. These benefits aren’t just ideas; they show up in your stats and your cloud bills.
Investigation speeds up because of better signal extraction during triage. Costs go down through intelligent filtering and volume optimization. Both connect directly to business outcomes that executives care about.
MTTR Reduction Through Automated Triage
Triage consumes the largest share of incident response time, often accounting for 60 to 70 percent of the total time required to resolve an issue. You’re going from “something is broken” to “these specific services are affected, and this part is the cause.”
Manual triage has multiple steps, represented below:
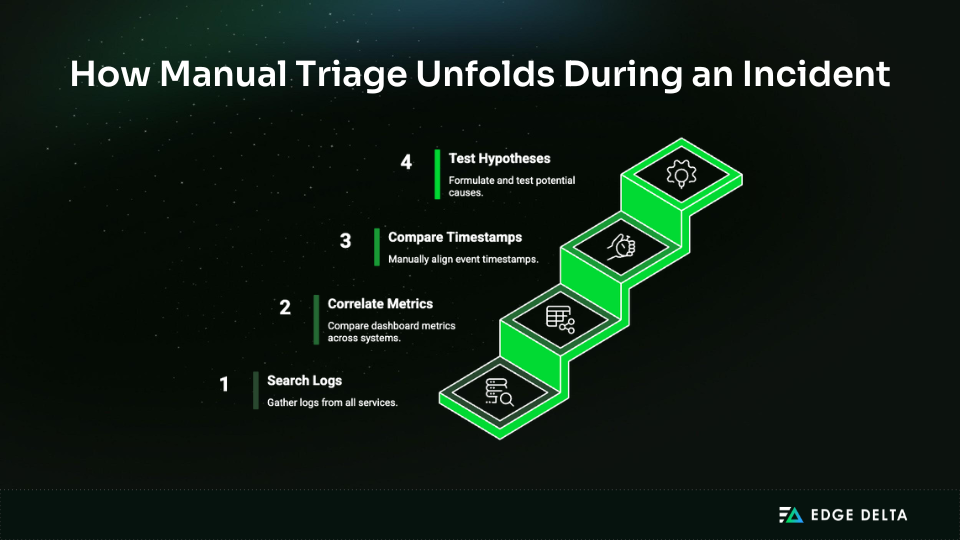
It takes time for each iteration, and complicated systems often need several rounds before you can narrow down the problem enough to start fixing it. During events, the back-and-forth between seeking, testing hypotheses, and validating them takes up valuable time.
AI tools like Edge Delta’s SRE Teammate accelerate this workflow by surfacing relevant patterns automatically, identifying anomalous behavior without manual queries, and correlating events across your services.
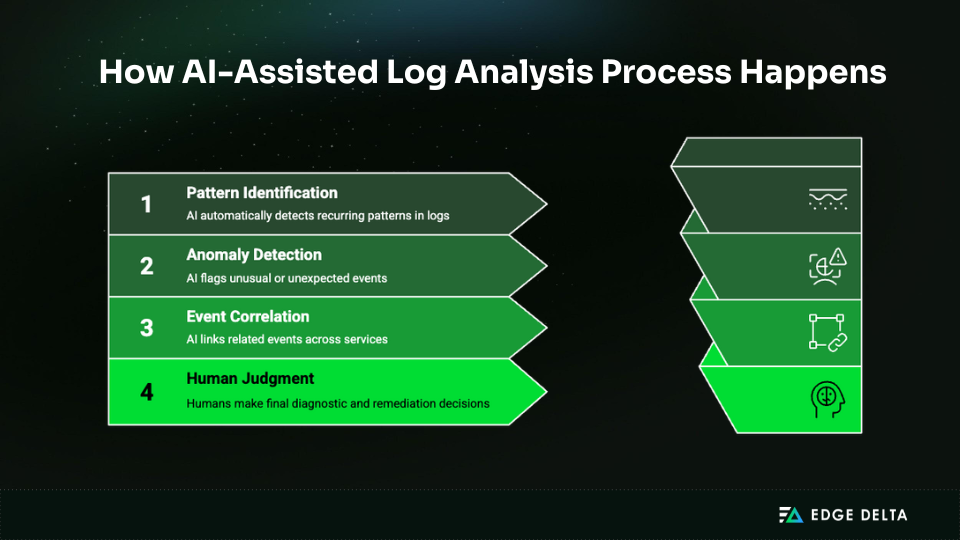
You still need human judgment for final diagnosis and remediation decisions, but you reach that point much faster because the initial investigative work happens automatically in the background.
MTTR reductions of 30–60% reported with AI-assisted log analysis
According to industry data on AIOps adoption, AI-assisted log analysis used for incident triage can reduce MTTR by 30 to 60 percent.
These improvements occur primarily during triage and correlation, not during fix implementation, which reflects where teams spend most of their time during incidents.
Triage typically accounts for the largest share of MTTR because engineers must first identify the affected systems and the most likely causes before remediation can begin. AI accelerates this narrowing process by surfacing relevant patterns and relationships earlier.
Engineers still need to design, test, and deploy fixes, but reaching that stage sooner reduces overall downtime and improves consistency in incident response.
Log Volume Optimization and Cost Control
It’s clear that not all logs are equally useful, but that distinction is easy to miss when everything is ingested by default. Many logs contribute little insight into system behavior while still consuming storage and indexing resources. Common examples include:
- Verbose debug output from stable services
- Repetitive health check messages
- Routine system events that rarely correlate with incidents
AI models identify these low-signal sources and either filter them at ingestion or intelligently reduce sampling rates. Storage costs decrease, indexing overhead is reduced, and processing performance improves. Observability quality often remains the same or improves as resources are reallocated toward high-value logs.
Volume optimization works by learning which log patterns are associated with incidents and which represent normal operation. Logs that rarely appear in incident timelines can be reduced or removed, while logs that consistently precede failures are retained at full fidelity. This adaptive approach outperforms static filtering rules that require constant manual updates.
Log ingestion cost reductions of up to 25% through intelligent filtering
Industry studies on log management practices show that intelligent filtering can reduce log ingestion costs by up to 25% by prioritizing higher-value data.
The savings come from eliminating redundant or low-value logs before they enter your downstream services, which means you’re not paying to store and index data you’ll never use.
This approach improves the cost-to-signal ratio by focusing resources on logs that contribute most to incident investigation and system visibility.
Log management costs scale with volume in most systems, whether you’re using a SaaS solution or running your own infrastructure. Reducing ingestion volume directly lowers observability spending without sacrificing your ability to debug production issues.
Here’s how traditional and AI-driven approaches compare across key operational metrics:
| Metric | Traditional Approach | AI-Driven Approach | Improvement |
|---|---|---|---|
| MTTR | Manual triage, correlation | Automated pattern detection | 30-60% reduction |
| Investigation Time | Linear search across services | Pre-correlated event sequences | Up to 50% faster |
| Alert Precision | Static threshold rules | Context-aware anomaly detection | 20-40% improvement |
| Storage Costs | Ingest all logs | Intelligent filtering | Up to 25% savings |
| Pattern Discovery | Manual observation | Automated clustering | Scales beyond human capacity |
These improvements are substantial and measurable. AI approaches also have limitations you need to understand clearly before implementing them in production.
What Are the Risks and Limitations of AI Log Analysis?
AI-based log analysis is not a complete solution, despite some vendor claims. It has well-defined limitations, requires ongoing maintenance, and is most effective as an assistive capability rather than an autonomous system that operates without human oversight.
The greatest risk is false confidence. Models surface likely root causes, and in high-pressure incidents it is tempting to accept those conclusions without validation. However, these models are probabilistic by nature. They infer outcomes from historical patterns, and those inferences can be incorrect, sometimes significantly so.
Training Bias and Concept Drift
Research on concept drift shows that machine learning models lose accuracy over time as real-world systems evolve beyond their training data.
Systems change through deployments, infrastructure migrations, and architectural refactoring. When this happens, model understanding becomes outdated because learned patterns no longer reflect current behavior.
Concept drift describes this gradual loss of accuracy. Models trained on last quarter’s log patterns may miss new error types introduced by recent changes simply because they have never encountered them before.
Training bias creates a related but subtler risk. When historical data is dominated by normal operations, models learn to expect stability and may struggle to recognize truly novel or rare failure modes.
As a result, systems can perform well for common issues while failing during unfamiliar incidents. In practice, teams often see measurable accuracy degradation within a few months if models are not retrained, especially in environments with frequent releases or infrastructure changes.
Model accuracy degradation over time without retraining for months
If models aren’t retrained regularly, their accuracy will drop by a meaningful amount within a few months of being put to use. How soon they break down depends on how quickly your systems change and how distinct new patterns are from old ones.
Rapidly changing environments with frequent deployments see faster drift than stable systems. You need regular retraining cycles to maintain model effectiveness, which adds operational overhead that some teams underestimate when first implementing AI log analysis.
As a result, retraining is not a one-time setup task but an ongoing operational requirement for maintaining reliable log analysis.
Over-Reliance on Automated Explanations
When teams need to move quickly, models can come up with answers that sound reasonable but aren’t always right. This is risky.
A system may identify Service A as the probable root cause, even though that relationship reflects correlation rather than causation. In some cases, Service A is a downstream victim rather than the source of the problem.
In incident response, AI should be treated as an assistive system that narrows possibilities. That’s why high-impact decisions and actions still require human validation. Deployment rollbacks or infrastructure scaling decisions based on incorrect assumptions can extend outages or introduce new failures.
When models show high confidence scores, the danger goes up. A 95% confidence rating can make people feel like they have to accept a conclusion without looking into it any further.
However, confidence reflects certainty within the model’s training data, not the objective truth about the current incident. A model can be confidently wrong.
Human validation required for high-impact incident decisions
AI risk management frameworks stress that human validation is necessary for important decisions, especially in workflows where reliability is very important.
Incorrect root cause identification or premature remediation can extend downtime or trigger additional failures. AI recommendations should accelerate human analysis, not replace it.
The best implementations use AI to narrow down the search space and find important signals. Engineers who know the system’s context and risk trade-offs make the final decisions.
Conclusion: Why AI Is Becoming Essential for Log Analysis at Scale
Traditional log analysis can’t keep pace with modern distributed systems. The gap between what we need to analyze and what we can analyze manually keeps widening.
AI fills this gap by using automated pattern recognition, anomaly detection, and correlation at levels that humans can’t reach. Companies notice real results: MTTR goes down by 30% to 60%, investigation times go down by as much as half, and storage expenses go down by as much as 25%.
As system complexity and log volumes keep increasing, AI-driven log analysis shifts from an optional enhancement to an operational necessity for teams that need to maintain reliability at scale.
Common Questions About Analyzing Logs Using AI
What does it mean to analyze logs using AI?
Machine learning is used in AI log analysis to automatically find patterns, spot unusual events, and link events across log data. These systems don’t look for known error signatures. Instead, they learn what usual behavior is and signal any changes. They also combine similar messages and provide possible reasons across dispersed services.
How is AI log analysis different from traditional search?
Traditional search depends on predefined queries and known error patterns. AI log analysis learns from historical data to surface unexpected behavior automatically, making it effective for identifying issues that don’t match existing rules or signatures.
Can AI replace engineers in log analysis?
No. AI supports engineers by surfacing patterns and likely causes, but humans provide context, validation, and make remediation decisions. The goal is to reduce manual investigation work, not replace engineering judgment.
How does AI improve MTTR through logs?
AI reduces MTTR by speeding up triage and correlation. It surfaces anomalies and related events automatically, helping teams identify affected services and likely causes faster, so they can move to remediation sooner.
What are the risks of AI-based log analysis?
The main risks are model drift, training bias, and false confidence. Models can lose accuracy as systems change and may miss novel failures, while automated explanations can sound convincing even when wrong. Effective use requires regular retraining, human validation, and treating AI outputs as probabilistic guidance rather than definitive answers.
Sources:

