

Complexity is often the enemy of scalability and maintainability. When dealing with high-speed, analytics-optimized databases like ClickHouse, the power often comes with its share of complexities. Read-write separation is a highly effective yet elegant solution for managing this complexity. In this post, we will not only delve into the benefits of separating read and write operations in ClickHouse, but also highlight the simplicity this architecture brings.
Why ClickHouse?
ClickHouse is celebrated for its speed, scalability, and flexibility. It thrives in high-load scenarios where fast queries and real-time analytics are a must. Yet, optimizing it further through read-write separation yields additional benefits, particularly when each service is dedicated to either read or write operations.
The Zen of Read-Write Separation
Read-write separation divides database operations into two categories: read operations (SELECT queries) and write operations (INSERT, UPDATE, DELETE queries). This seemingly simple division brings forth an array of advantages.
Benefits of Read-Write Separation in ClickHouse
Before diving into the benefits, it’s worth mentioning that an observability use case involves processing large-scale data sets that are constantly growing. To serve complex and time-sensitive queries in a data-heavy environment, you need to optimize your database architecture, thus maintaining performance and reliability.
By implementing read-write separation in ClickHouse, you will see the following benefits:
- Resource Optimization: Read nodes are optimized for data retrieval, caching, and faster queries, requiring perhaps higher RAM allocations. Write Nodes are tuned for quicker data ingestion, prioritizing CPU and disk I/O.
- Improved Performance: With read and write nodes operating separately, each can be fine-tuned for its specific function, boosting overall performance.
- Effortless Scalability: The architecture allows for flexible, targeted scalability. Need to speed up read queries? Simply add more read nodes.
- Enhanced Availability and Fault Tolerance: If the write nodes fail or need to be taken down for maintenance, the read nodes can still function, and vice versa. This separation increases the overall availability of your system.
- Simplified Monitoring and Troubleshooting: With separated concerns, it’s easier to pinpoint issues or bottlenecks in your system. Whether it’s an INSERT query causing a bottleneck or a SELECT query taking too long, the issue becomes easier to diagnose when reads and writes are separated.
The Simplicity Factor
Now, let’s discuss the elephant in the room—the beauty of this design’s simplicity. This factor alone can unlock several advantages that make the architecture easier to scale and maintain.
- Simpler Debugging: If there’s an issue, you instantly know it’s either with a read node or a write node. There’s no need to sift through a mixed bag of read and write queries to diagnose problems.
- Ease of Management: With Kubernetes, creating and managing these separate services becomes almost trivial. Kubernetes’ selectors and labels make it exceedingly simple to route traffic to the appropriate nodes.
- Clarity and Predictability: Having two services — one dedicated to reading and one to writing — is architecturally clean. Any new team member or even a third-party service can instantly understand the setup.
- Clean Monitoring: It’s much easier to set up performance metrics or alerts specific to either read or write operations. This makes monitoring a breeze.
A Real-World Example Using Kubernetes
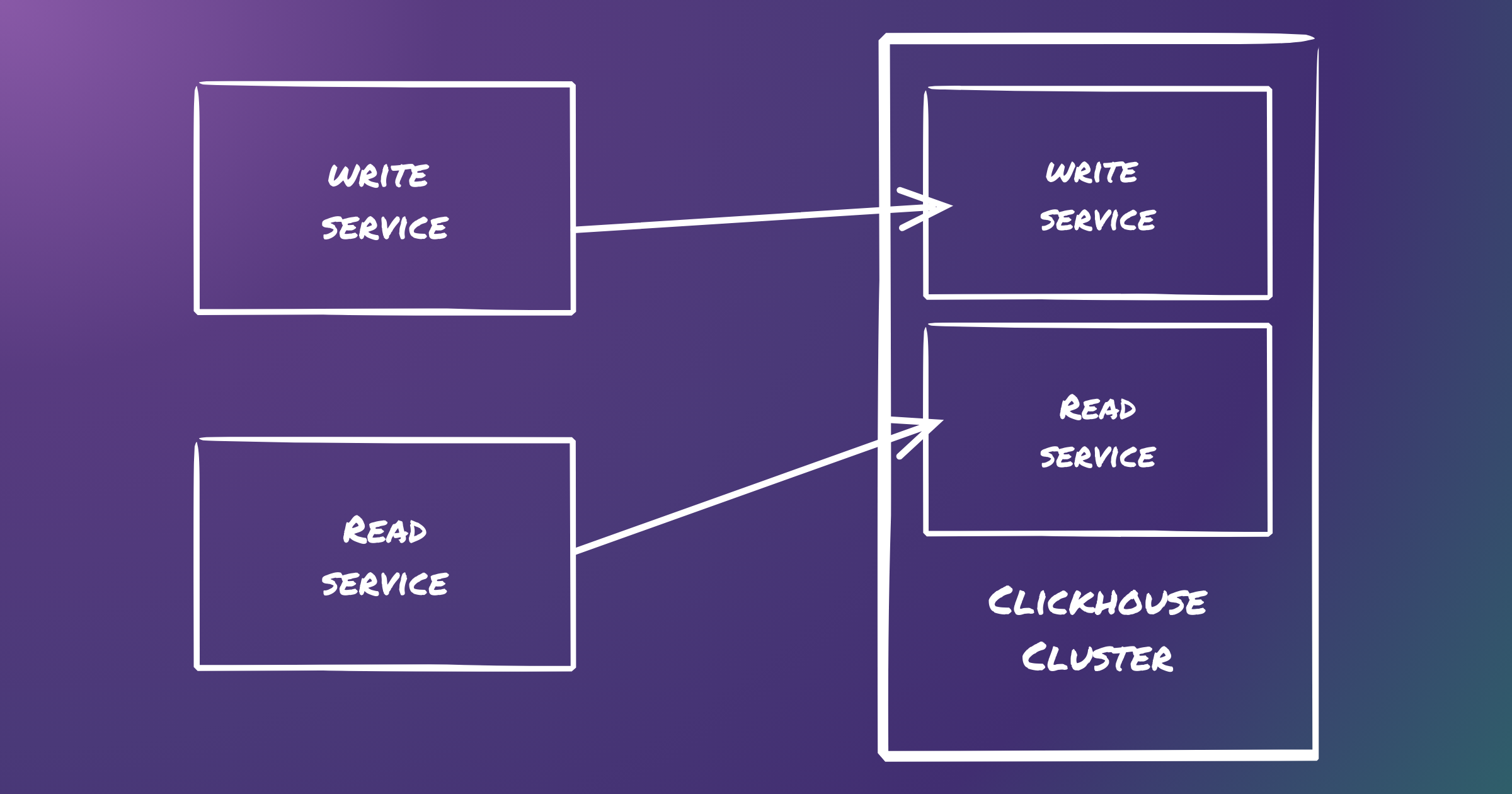
Let’s take a look at the overall ClickHouse architecture:
- Deploy ClickHouse to Kubernetes using Altinity Kubernetes Operator for ClickHouse.
- Create two explicitly different templates for read and write pods.
- Label the nodes as either
readorwrite. - Ensure the read pod template includes the option
always_fetch_merged_part: truebecause we want merges to happen only on the write pods. - Create two services to select on read and write pods.
- Route our read requests to read service and write requests to write service.
In just a few simple steps, we’ve created a ClickHouse cluster capable of routing read and write requests to different sets of pods.
When simplicity meets effectiveness, the result is often a resilient, scalable, and manageable system. ClickHouse is already a robust solution for fast, large-scale data analytics. By implementing read-write separation and focusing on the design’s innate simplicity, we amplify its strengths while streamlining its management and scalability.
This elegant simplicity solves today’s problems and provides a future-proof foundation for tackling tomorrow’s challenges. The result? A ClickHouse architecture that’s both robust and delightfully simple to manage.
But what if I told you this is just the tip of the iceberg? While having a simplified, separated architecture for read and write operations is fantastic, the real magic begins when you introduce auto-scaling into this setup. Can you imagine a ClickHouse cluster that dynamically scales its read and write nodes based on real-time demand? Stay tuned, as we’re about to delve into that game-changing territory in the future.



