


Modern distributed and cloud-native environments are generating telemetry data at unprecedented rates, which presents significant challenges when it comes to downstream storage, processing, and analysis. If left unchecked, this volume of data can lead to massive costs and diminishing returns from legacy observability platforms.
In this blog post, we’ll dive into the mechanics of a popular sampling method — consistent probabilistic sampling — that helps teams reduce downstream ingestion volumes while preserving insight quality. We’ll cover the fundamentals of consistent probabilistic sampling, and share how it’s implemented in Edge Delta’s easy-to-use Sample Processor node.
What Is Sampling, and How Does It Work?
Sampling is a popular volume reduction technique that works by removing subsets of log, metric, and trace data from an entire dataset. Instead of capturing every log, metric, or trace item, sampling selectively retains a subset of data based on predefined rules or probabilities. By applying sampling at the pipeline level, teams can control their storage and processing costs while maintaining an accurate, representative view of system behavior.
Although sampling techniques can be applied to any data type, they’re primarily used to filter log and trace data. Sampling trace data can be slightly more complicated, as you have to choose between a head or tail-based approach. Regardless of when in the data’s lifecycle you choose to perform sampling, you’ll need to identify a sampling mechanism to apply during evaluation. Consistent probabilistic sampling is a popular choice, largely due to its underlying deterministic hashing mechanism. In the next section, we’ll explore how it works in more detail.
Consistent Probabilistic Sampling
Traditional probabilistic sampling works by randomly including or excluding data points based on a fixed acceptance probability. In distributed systems, this often results in incomplete or partial trace data along with inconsistent log sampling, as different services disagree on which logs and traces to sample.
For example, consider a distributed trace with traceID=10 involving two services, A and B. Each service will sample its corresponding span independently — and with traditional probabilistic sampling, there’s a chance one will drop its span while the other keeps it, resulting in a partial trace. Similarly, if both services generate logs associated with the trace event, there’s a possibility that only a portion are sampled out, even though ideally they should be kept or dropped together.
Consistent probabilistic sampling addresses these inconsistencies by using consistent hashing, which ensures that the same input always hashes to the same output, regardless of which service is performing the evaluation. Its deterministic nature makes it particularly valuable for sampling logs and traces created in distributed environments.
Consider again the example mentioned above. By applying consistent hashing on a persistent field like traceID, Services A and B will create the same hash for their respective spans and will therefore agree on which traces to preserve and which to drop, even though they perform the sampling independently. Additionally, creating a consistent hash on log IDs will also ensure all associated logs are either kept or dropped together.
Let’s go over how consistent probabilistic sampling works step-by-step:
- The sampler receives an item to sample or drop.
- It extracts field values which will be used to calculate a hash.
- A hash value is then calculated using a deterministic and uniformly-distributed hash function.
- The hash is normalized to be between 0 to 100.
- The hash is compared with the sampling percentage. If the hashed value is higher than the percentage, then the item is dropped. Otherwise, the item is passed through.
This approach ensures that the same input always leads to the same sampling decision, making it ideal for distributed systems where consistency is critical.
Consistent Probabilistic Sampling with Edge Delta
At Edge Delta, we’ve implemented consistent hashing in the form of a Sample Processor node within our Telemetry Pipelines. Using consistent hashing, our agents apply consistent probabilistic sampling on all given telemetry data, ensuring no partial traces or log inconsistencies occur. Additionally, since the consistent hashing function generates outputs that are uniformly distributed over its range, it guarantees an even spread of sampled data, preserving statistical accuracy while effectively reducing data volume.
The image below shows the Sample Processor node in Edge Delta’s Live Capture pipeline view:
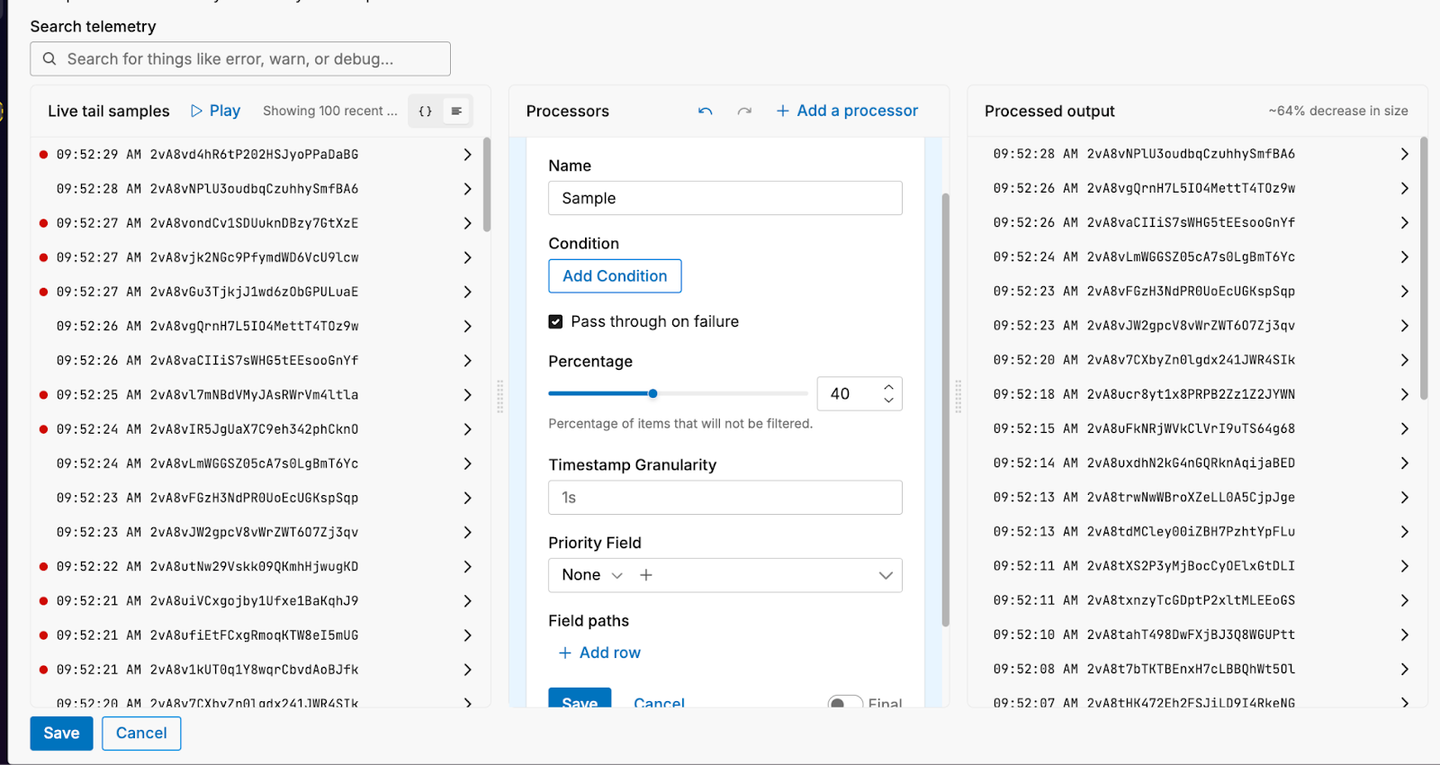
With Edge Delta’s Live Capture view, you can view a live tail of data entering a given node, and visualize how node edits would transform the data in real time.
With a sampling percentage set to 40%, the sampler reduces the output size by approximately 64%. For a dataset of 100 items, a 36% selection rate is within a logical range of variation from a 40% sampling percentage. As data throughput increases, the actual selection rate will converge on the given sampling percentage.
Although the Sample Processor node is easy to use in our UI, implementing the underlying logic required us to make several complex decisions for optimal performance at scale. We will explore those choices in the following sections.
Selecting an Optimal Hash Function
When implementing consistent probabilistic sampling, the output of the hash function must be uniformly distributed. In other words, it must generate numbers within the output range with equal probability. If it isn’t uniformly distributed, the sampling percentage will not be leveraged as intended, which will lead to too many or too few sample successes. Moreover, the hash function must run its computations extremely efficiently to support sampling operations at scale.
After some research and prototyping at Edge Delta, we chose xxHash as our underlying hashing function, which is an extremely fast, non-cryptographic hash algorithm. The Golang implementation of xxHash (called XXH3) outperforms other popular hashing functions across every benchmark category.
Full details are available here.
Caching Hash Calculations
Even with a fast hash function, the hashing process is still resource-intensive and can become a bottleneck for sampling decisions. To address this issue, we introduced an in-memory Least Recently Used (LRU) cache to store hash calculations and eliminate redundant hashing.
The most common use case of a probabilistic sampler is to sample incoming traces by their IDs. A given trace can have thousands of spans, all of which have the same trace ID. If we calculate the hash value separately for each incoming item, we’ll use unnecessary resources to perform the same calculation several different times. With our LRU cache, the hash value for each trace ID is calculated once and stored locally, where it can be accessed and used for all future spans within the same trace. This approach improves processing latency and resource usage when sampling large amounts of data. As with the hashing algorithm, high performance and memory efficiency are essential for an in-memory LRU cache. We decided to use LRU by Phushu, which is an LRU cache that outperforms most of the known caches in Golang with zero additional memory allocations.
| Cache Implementation | Ops/sec | ns/op | B/op | Allocs/op |
|---|---|---|---|---|
| Hashicorp | 17,376,360 | 570.8 | 0 | 0 |
| Cloudflare | 74,426,450 | 92.55 | 16 | 1 |
| Ecache | 88,482,524 | 78.37 | 1 | 0 |
| Lxzan | 74,142,448 | 90.51 | 0 | 0 |
| Freelru | 80,740,551 | 88.70 | 0 | 0 |
| Phuslu | 97,101,519 | 65.88 | 0 | 0 |
| NoTTL | 92,839,735 | 65.27 | 0 | 0 |
| Ccache | 25,047,673 | 350.2 | 25 | 2 |
| Ristretto | 90,289,784 | 81.44 | 22 | 1 |
| Theine | 57,348,163 | 114.3 | 0 | 0 |
| Otter | 100,000,000 | 65.72 | 4 | 0 |
Above is a performance comparison of several popular caching implementations. Our LRU cache of choice, “Phuslu,” is highly efficient and does not require any bytes or memory allocations per operation.
Optimizing Memory Management
Inefficient memory allocation during hash calculation time can significantly reduce performance speed by increasing CPU load and pressure on the garbage collector. Memory pools are a common optimization technique used to reduce memory allocations and improve performance in high-throughput applications. Instead of creating and destroying objects repeatedly, memory pools maintain a collection of reusable objects, minimizing pressure on the garbage collector and reducing latency caused by frequent allocations.
In languages like Go, where garbage collection can impact performance, memory pools can significantly improve efficiency in scenarios that require frequent object reuse, such as the hashing operations performed during consistent probabilistic sampling.
Let’s walk through a short example to demonstrate how memory pools work in practice.
To calculate the consistent hash for a given data item, we first need to store the fields we’ll be hashing — for instance, we may want to hash the trace IDs for a collection of traces, which requires us to convert them into byte arrays before hashing. We can avoid memory allocation at each step by using a pool in which we store shared buffers:
func Hash64(value any) uint64 {
hg := HashGeneratorPool.Get().(*HashGenerator)
defer HashGeneratorPool.Put(hg)
hg.WriteValueHash(value)
h := xxhash.Sum64(hg.buf.Bytes())
hg.buf.Reset()
return h
}In the above code snippet, we are working with a hash generator pool. When calculating hashes, we first get a generator from the pool, then write the values to be hashed, and finally calculate the hash. Once finished, the buffer is reset for the next calculation, and the generator is put back into the pool again. With this process, the impact of hashing calculations is reduced significantly.
Looking Ahead
Consistent probabilistic sampling is a powerful solution for balancing telemetry data retention and cost efficiency while maintaining an accurate view of your environment.
Its consistent hashing approach ensures that the same input always leads to the same sampling decision, preventing partial traces, inaccurate log sampling, and inconsistencies across distributed systems.
By developing an efficient consistent probabilistic sampling mechanism in our Sample Processor node, we’ve given teams the ability to leverage this powerful technique within their Edge Delta Telemetry Pipelines — without worrying about the complex underlying implementation.
As observability continues to evolve, techniques like consistent probabilistic sampling will play a crucial role in helping organizations manage their data efficiently, while preserving the fidelity needed for effective monitoring, debugging, and analysis — especially in large-scale, high-throughput environments.



