

By 2025, the global data production is expected to exceed 181 zettabytes. Advancements in IoT, AI, and real-time analytics fuel this astonishing growth. At the same time, traditional formats like CSV and JSON feel pressure from the expanding datasets.
Enter Apache Parquet, a columnar storage format built for high-performance analytics and massive scale. Used across platforms like Spark, Snowflake, and AWS Athena, Parquet is reshaping how modern data stacks handle volume and velocity.
Let’s break down how the Parquet data format stacks up against Avro, ORC, CSV, and JSON. In this article, we will be unpacking its strengths and exposing its limitations to help you make smarter choices for your data architecture.
Key Takeaways
• Parquet reads data fast. It only loads the columns you need, making analytics 10–100x faster than formats like CSV or JSON.
• Parquet shrinks file size. Its built-in compression cuts storage by 2–5x, saving money and speeding up queries.
• Parquet handles schema changes. You can add or change fields without breaking your pipelines.
• Parquet is less optimal for real-time writes. It’s slow for frequent updates or streaming.
• Parquet is trusted at scale. It’s used by companies like Uber, AWS, and Google for big data and cloud analytics.
What is Parquet?
With about 120 zettabytes of data created every year worldwide, handling massive datasets efficiently has never been more crucial.
Apache Parquet is an open-source, columnar storage format designed for efficient data analytics at scale. Created in 2013 by Twitter and Cloudera, it was donated to the Apache Software Foundation and is now a core component of the Hadoop ecosystem.
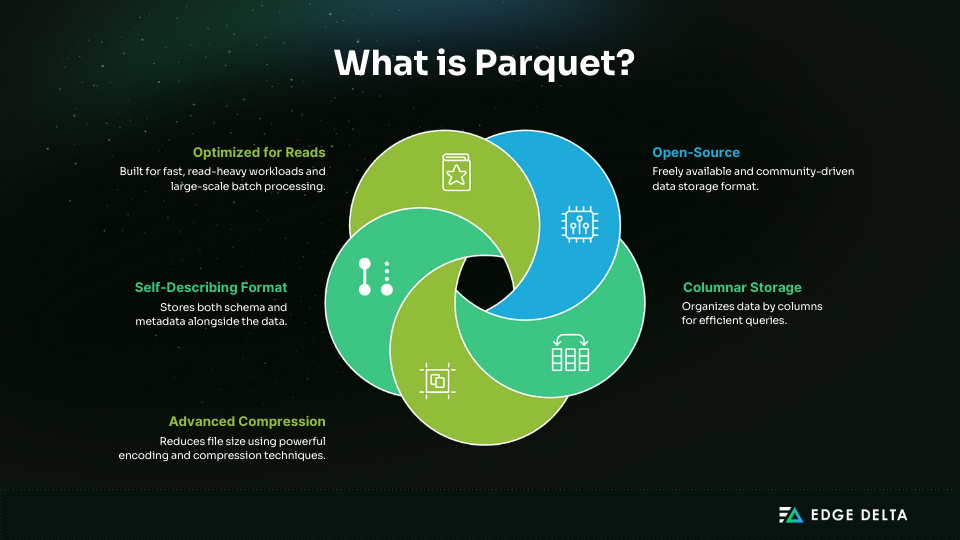
Parquet stores data in columns, unlike row-based formats like CSV or JSON. This design reduces disk I/O for analytical queries. It also supports advanced compression and encoding schemes, including Snappy, Gzip, Brotli, and LZO.
Self-describing, Parquet stores metadata and schema in addition to data. It facilitates schema evolution, which is necessary for long-lived datasets because it permits backward-compatible modifications like adding columns or rearranging existing ones.
Highly parallelized reads are made possible by the internal storage of data in row groups, pages, and column chunks. This format is engineered for batch processing and read-heavy operations. It’s the preferred format for the following systems:
- Apache Spark
- Hive
- Presto
- Apache Drill
- AWS Athena
- Google BigQuery
Parquet is an excellent choice for ETL pipelines that handle large, structured datasets, as well as for business intelligence and data warehousing tasks.
Top Reasons to Use Parquet Format
Let’s get one thing straight: Parquet isn’t your everyday data format. It is built for scale. When you’re wrangling millions or billions of rows, Parquet doesn’t just survive. It dominates!
Why is Parquet the top choice of modern analytics stacks? Find out below.
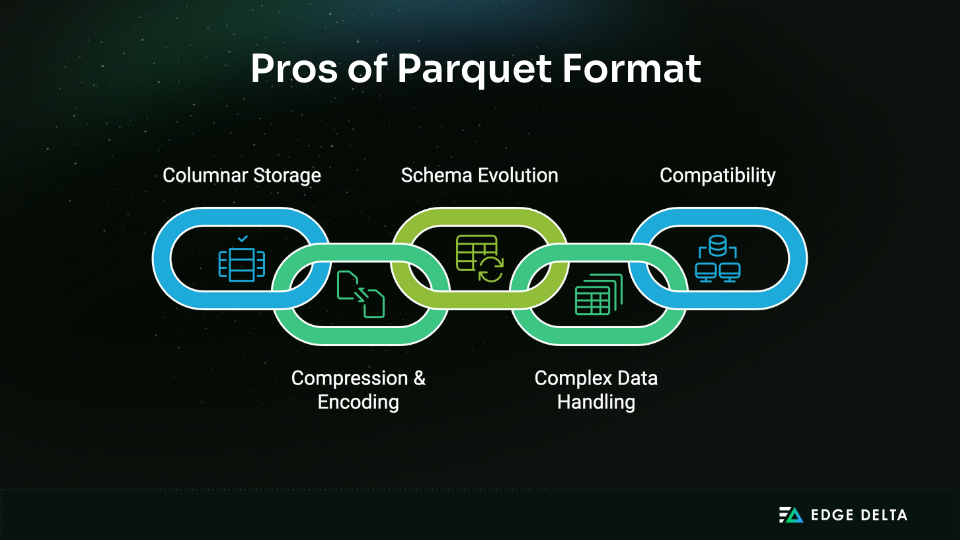
1. Columnar Storage
Instead of packing data row by row like CSV or JSON, Parquet goes column by column. That means if your query only touches two out of fifty columns, it skips the rest (literally). The result? Massive gains in performance.
Don’t just take our word for it. Databricks ran benchmarks showing Parquet can serve up reads 10x to 100x faster than row-based formats. And that’s not theory. It’s production-grade speed for OLAP-style workloads.
Whether you’re scanning billions of rows or slicing columns for analytics, Parquet gets it done without breaking a sweat.
2. Compression and Encoding
Parquet doesn’t just store data. It shrinks it. With built-in support for Snappy, Gzip, Brotli, and others, Parquet compresses each column independently.
Repeated values in a single column? Crushed.
Text-heavy fields? Optimized with dictionary encoding and run-length encoding.
The payoff? Storage that’s 2x to 5x smaller than JSON or CSV, and queries that fly because there’s less data to scan. Google Cloud flat-out states that using Parquet in BigQuery means you save time and money. Fewer bytes = smaller bills.
3. Schema Evolution
Maintaining data quality and consistency is essential in modern data architectures. Adding or dropping a field? In CSV, that’s a disaster waiting to happen. In Parquet, it’s business as usual.
Parquet supports schema evolution out of the box. Tools like Spark, Hive, and AWS Glue handle it smoothly, reading old and new data without a hitch. You get forward and backward compatibility.
4. Complex Data Handling
Parquet wins in workloads that involve nested fields. JSON can represent wrapped, complex structures, but Parquet can optimize them. The latter is also compatible with Apache Arrow under the hood, which means faster parsing and space use.
Whether you’re dealing with telemetry data, user session data, or event data, Parquet embraces the complexity. In fact, it thrives on it! When it comes to scalable ingestion, it’s the go-to format for big platforms like Snowflake and Databricks.
5. Compatibility
Parquet isn’t limited to a closed-off system. It’s everywhere. Whether you’re working with Spark, Presto, AWS Athena, or Google BigQuery, Parquet is ready to go right out of the box. You can read and write it using Java, Scala, and even Python (via Pandas, PyArrow, and Dask).
That means zero vendor lock-in, smooth handoffs between tools, and serious flexibility in cloud and on-prem environments. You’re not stuck converting formats or babysitting fragile ETL jobs. It just works, and that’s why teams across the industry trust it to move data at scale.
Drawbacks and Limitations of Parquet
Parquet is powerful, but it’s not perfect. It’s fast when reading big chunks of data, but it may not be the greatest when you’re trickling in small updates. While it’s great for machines… for humans? Not so much.
Below are the limits teams should be aware of before defaulting to Parquet:
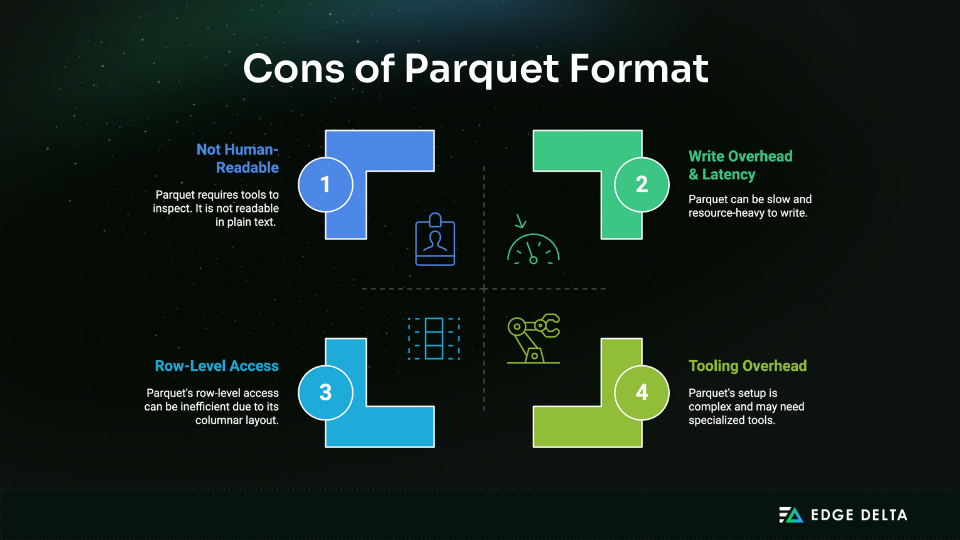
1. Not Human-Readable
You can’t open a Parquet file in a text editor. It’s a binary format. If you’re used to peeking through a CSV or JSON to debug something quickly, that’s not happening here.
Want to spot-check a file? You’ll need a tool like Apache Arrow, parquet tools, or a notebook environment with a proper library. Parquet was built for machines, not human eyes.
2. Write Overhead and Latency
Parquet is optimized for reading, not writing. Every time you write data, it has to go through columnar organization, encoding, and compression. That means more CPU usage, more memory, and more time.
If you’re working with real-time ingestion, streaming logs, or small incremental writes, Parquet can become a bottleneck. Tools like Kafka, Flink, or real-time dashboards usually lean on formats like Avro or even raw JSON because they’re faster to write and easier to handle in flight.
AWS documentation even notes that Parquet isn’t ideal for frequent small writes or transactional workloads. It shines with batch, not trickle.
3. Inefficient for Row-Level Access
Need to grab a single row? Parquet’s going to make you work for it. Because of its columnar layout, each row’s data is split across different sections of the file. This makes row-level access inherently inefficient.
Row-based formats like Avro or Protobuf are much better at this. They store entire records together, making them easier to fetch, mutate, or stream. Parquet is the wrong tool if you need fast point lookups or frequent row updates.
4. Tooling Overhead
Getting started with Parquet isn’t as easy as it sounds. Sure, the ecosystem’s massive, but setting up the right tools can be challenging.
You’ll likely end up dealing with libraries like PyArrow or FastParquet or linking up with Spark, Hive, or Presto to kick things off.
Parquet vs. Other Formats
Saying that Parquet is awesome is one thing, but how does it really measure up against its rivals? We’re referring to the familiar names: CSV, JSON, Avro, and ORC. Each of these formats has its own niche in the data ecosystem, but the real challenge is figuring out when to use which one.
Below is a direct, side-by-side breakdown of how Parquet compares across the metrics that matter: speed, compression, schema handling, and overall use case fit.
| Feature | Parquet | CSV | JSON | Avro | ORC |
|---|---|---|---|---|---|
| Storage Type | Columnar | Row-based | Row-based | Row-based | Columnar |
| Compression | High (Snappy, Gzip, Brotli) | None (manual) | Moderate (manual) | Moderate (Deflate) | Very High (Zlib, LZO) |
| Read Performance | Excellent (esp. for selective columns) | Poor | Poor | Moderate | Excellent |
| Write Performance | Moderate to Slow (due to encoding) | Fast | Fast | Fast | Moderate |
| Schema Support | Strong (with evolution) | None | Weak (schema-less) | Strong (with evolution) | Strong (with evolution) |
| Nested Data Support | Excellent (via Arrow) | None | Good (but inefficient) | Moderate | Excellent |
| Human Readable | No | Yes | Yes | No | No |
| Best Use Cases | Analytics, Data Lakes, BI Tools | Quick Inspection, Debugging | Logging, Config Files | Streaming, Serialization | Data Warehousing (esp. Hive) |
| Cloud Compatibility | Universal (AWS, Azure, GCP) | Universal | Universal | Universal | Mostly Hadoop Ecosystems |
When it comes to heavy analytics, Parquet and ORC take the lead. If you need super-fast writes or streaming, Avro is your best bet. For quick debugging or one-time scripts, CSV or JSON will do the trick.
However, when it comes to storage efficiency and query performance, especially in the cloud, you can’t go wrong with Parquet.
When to Use Parquet
Two out of three data leaders say data and analytics are key to driving innovation in their organizations. But innovation doesn’t just come from collecting more data. It comes from using it smarter.
That’s where Parquet comes in. When used right, it can cut costs, boost performance, and scale effortlessly. Let’s explore where Parquet shines the most.
1. Analytics Pipelines
Parquet thrives here. With Spark, Presto, Hive, or any SQL engine, its columnar format reads only what you need. No wasted I/O, just speed.
2. Large-Scale Reporting
Running massive dashboards or BI reports? Parquet compresses like a champ, slashing query time and costs, especially in platforms that bill you by scanned data like Athena or BigQuery.
3. Columnar Querying
If you’re filtering by region, Parquet skips the fluff and hits just the columns you need unlike clunky row-based formats.
4. Cloud Cost Optimization
Parquet’s efficiency can cut query costs by up to 90%. Less data read means more money saved.
When Not to Use Parquet
Now, let’s dive into the tricky side of Parquet. Using it in the wrong situation is like trying to deliver a pizza with a freight train. Totally off the mark!
Here are some instances where Parquet might not be the right fit:

1. Real-Time Log Streaming
Parquet wasn’t built for speed in the fast lane. If you stream tiny data chunks in real time, it can choke.
2. Debugging or Data Inspection
Need to crack open a file to see what’s inside? That is not possible with Parquet. It’s binary, not human-readable.
3. Frequent Small Updates
Parquet isn’t designed for casual edits. Updating just a few rows requires rewriting large sections of data.
Looking ahead
Parquet is the no-brainer for big data. Tools like Spark, Athena, and BigQuery are practically built for it as they depend on its columnar strengths. It is the go-to for engineers who value about speed, scalability, and cost-efficiency.
However, Parquet isn’t a one-size-fits-all solution. If you try to force it into real-time streaming or debugging workflows, you’ll soon run into obstacles. It really shines when you’re reading columns, not when you’re updating rows.
If your pipeline is built for analytics or if your data lives in the cloud, Parquet isn’t optional. It’s essential. For teams running analytics pipelines on Parquet data, AI Teammates can monitor pipeline health, detect processing anomalies, and reduce operational overhead.
Parquet FAQs
What is the data structure of a parquet file?
Parquet packs data in layers: footer, row groups, column chunks, then pages. The footer holds the schema and metadata, perfect for blazing-fast reads and killer compression.
Can CSV be converted to Parquet?
Yes! Tools like Pandas or Apache Arrow easily convert CSV to Parquet.

