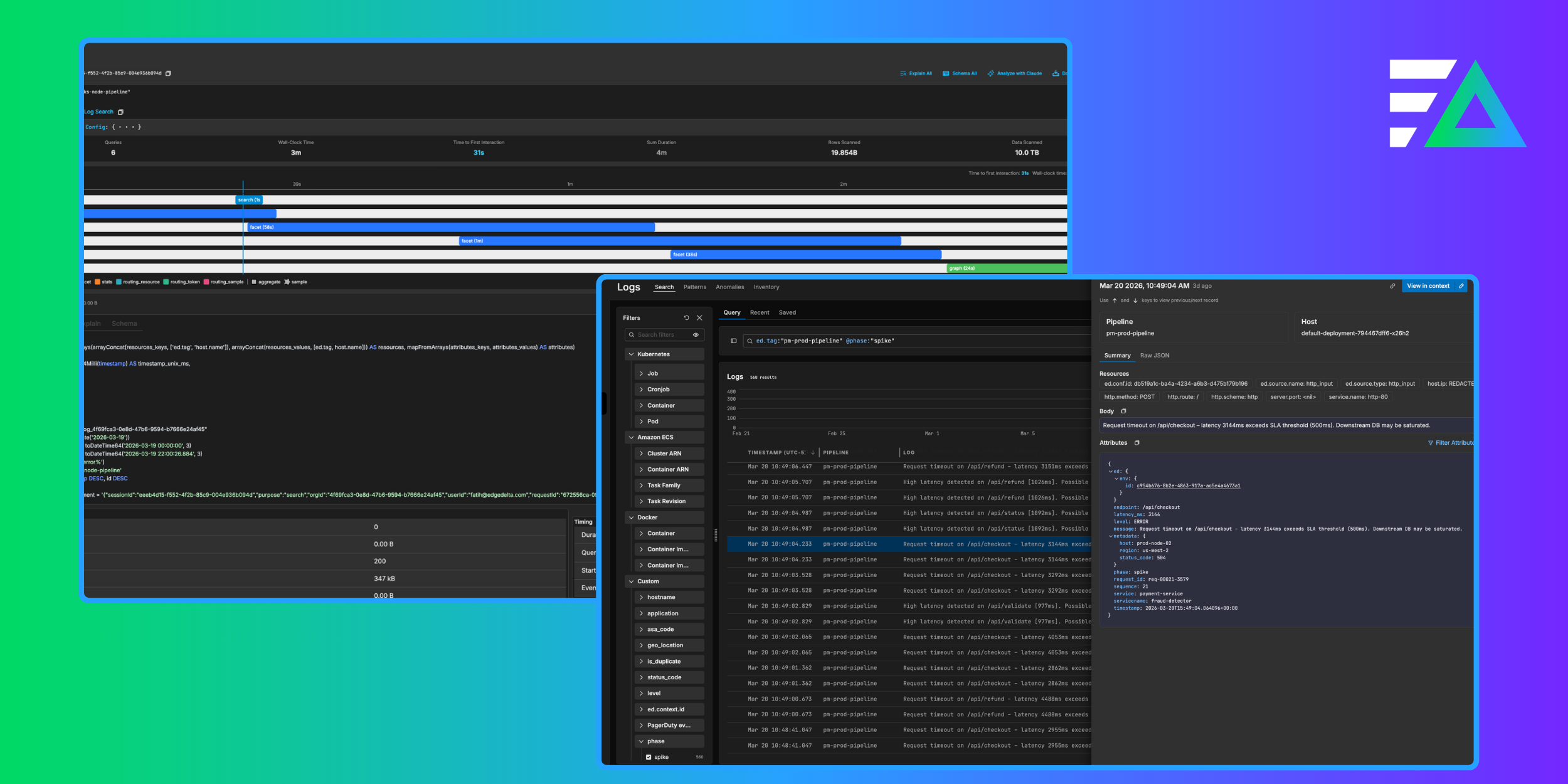
Modern data stacks are the foundation for unlocking the value of data in a data-driven world. A modern data stack is a group of tools, technologies, and processes that help organizations efficiently manage, analyze, and derive insights from their data. A modern data stack typically includes different components to support the entire data lifecycle – from collection to visualization. The ultimate goal of adopting a modern data stack is to leverage your data optimally, enabling better operations, decision-making, and innovation.
Atlan, a metadata platform, reported that 56% of data leaders declared a significant boost in their budget allocation for data & analytics initiatives in 2023. This number shows the growing recognition of data as a driving force in decision-making within organizations.
Automate workflows across SRE, DevOps, and Security
Edge Delta's AI Teammates is the only platform where telemetry data, observability, and AI form a self-improving iterative loop. It only takes a few minutes to get started.
Learn MoreDelve into the complexities of modern data stacks by exploring more about:
- What they are and how they work
- The benefits of leveraging them
- What challenges arise when using them
Read on.
Key Takeaways
- A 56% increase in the 2023 budget allocation for data and analytics underscores the rising importance of data in organizational decision-making.
- Modern Data Stacks are frameworks on cloud platforms that streamline data collection, processing, and analysis.
- The optimal data stack should be highly available and elastically scalable via resilient and adaptable data infrastructures.
- Modern data stacks enable scalability, real-time processing, and cost-efficiency. However, organizations can still struggle with integration complexities, data quality concerns, and skill gaps.
Unlock the Power of Data: An In-Depth Exploration on Modern Data Stacks
“Data is the new oil” — this was a popular statement coined by the British mathematician Clive Humby in 2006. While this metaphor raised concerns by a few individuals and groups, it is undeniable that data is a valuable resource in today’s world.
Data influences decision-making and promotes development. With up to 2.5 quintillion bytes of data that internet users generate daily, one can say that data is a game-changer for businesses. That is why 60% of organizations use data analytics to fuel business innovation.
To extract the true value of data, you will need specialized tools. This is where modern data stacks come in. A modern data stack is a set of interconnected tools used to handle the collection, storage, processing, visualization, and analysis of data.
A well-designed modern data stack can help unlock the full potential of your business and its data—whether you are a startup that wants rapid growth, an SME looking for cost-effective solutions, or a large enterprise that requires tools to handle intricate data.
What are the Principles of Modern Data Stacks?
To have an effective modern data stack, you must achieve two crucial architectural principles: Availability and Elasticity. Resilient and flexible infrastructure helps ensure an organization’s data and systems are accessible and adaptable to changing demands.
Check out what each principle means below.
- Availability: Availability refers to the data being readily accessible and usable at any time. You can achieve high availability through several best practices. This includes implementing redundant and geographically isolated storage, backup and recovery procedures, fault-tolerant architectures, and monitoring and alerting tooling.
- Elasticity: Elasticity is the ability of a modern data stack to scale its resources up or down automatically based on changes in workload demands. Resource consumption fluctuates dramatically, so the ability to scale up or down guarantees top-notch performance and cost efficiency.
By prioritizing availability and elasticity, you can build a more resilient and adaptable data stack. However, implementing both principles requires tedious planning, architecture design, and continuous monitoring.
Components of Modern Data Stacks
Modern data stacks consist of interconnected elements that streamline data processing. Different components work collaboratively to handle large volumes of information. These integrated systems empower businesses to extract valuable insights and make data-driven decisions efficiently.
Discover more about the components of modern data stacks below.
Data Storage and Processing
The data storage and processing layer concentrates on efficient data usage. It revolves around where data is stored and how it is processed. Data lakes and data warehouses are the two most regularly utilized storage formats.
Data Warehouse
A data warehouse is a repository for structured and semi-structured data. Data, such as point-of-sale transactions, is collected, reformatted, cleaned, and uploaded to the warehouse.
IBM researchers Barry Devlin and Paul Murphy introduced the concept of data warehousing in 1988. Its purpose was to facilitate the examination of past data. A data warehouse allows users to execute queries and analytics on historical data collected from transactional sources.
Data Lake
A data lake is a flexible storage option for structured, semi-structured, and unstructured data. It can store data in various formats and sizes.
Real-time data import is possible with data lakes. Leveraging data lakes enables organizations to generate various insights and resolutions with machine learning (ML).
Data warehouses and data lakes are both efficient data storage solutions. However, a data lake is more flexible and works well with machine learning. It is suited for diverse data. Meanwhile, data warehouses focus on reporting and are effective when dealing with structured data.
Data Ingestion
Data ingestion involves extracting and delivering data from various sources to the storage layer. Ingestion can be executed through stream or batch processing modes.
Stream Processing
Stream, or “real-time” processing refers to the immediate handling and analysis of data as it is generated or received. Data is processed often within milliseconds or seconds of its creation.
In real-time processing, data streams are analyzed as they pour in. This mode suits applications where quick reactions are crucial—like observability pipelines, fraud detection, stock market analysis, and sensor data analysis.
Batch processing
Batch processing involves collecting and processing data in predefined chunks or batches. In this mode, data is collected and stored until a sufficient volume is reached, and then processing is initiated. This model is also ideal for tasks like analyzing historical data or running ad hoc queries.
Choosing between real-time and batch processing depends on the organization’s needs. If instant insights are vital to your operations, real-time processing is the best way to proceed. Usually, modern data stacks utilize both modes for a comprehensive solution.
Data Transformation
The third layer, data transformation, involves cleaning, shaping, and enriching data to make it usable for analysis. Data can undergo transformation before or after its arrival at the storage destination in a data pipeline.
Traditional data pipelines used ETL (extract, transform, load) to process data before storing it in on-prem warehouses. Organizations can save costs and optimize space utilization by preprocessing data before storage by eliminating low-value data.
Now, cloud-based warehouses offer flexible scaling, making pre-transformations unnecessary. ELT (extract, load, transform) is preferred, storing raw data and transforming it only when needed, improving speed and efficiency.
Business Intelligence (BI) and Analytics
The Business Intelligence (BI) and Analytics layer empowers users to explore, analyze, and visualize data for insights.
Business Intelligence (BI) involves using various data sources to generate actionable insights, enabling businesses to identify trends and optimize performance. BI tools provide user-friendly interfaces for data visualization and exploration. Some examples are Tableau, Looker, and Power BI.
Analytics involves advanced statistical analysis, data mining, and machine learning (ML) techniques to get valuable insights from large datasets. Advanced analytics tools like Looker and ThoughtSpot provide deeper analysis capabilities.
BI and Analytics give businesses the tools to turn data into actionable intelligence for strategic decision-making.
Data Observability
Data observability contributes to the overall performance and health of data pipelines and the system. It uses various tools to monitor data flow, spot issues, and even predict them. This helps data teams fix problems faster and improves overall data reliability.
By implementing data observability with the right features and philosophy, organizations can ensure their data is healthy and reliable, leading to better decision-making and improved business outcomes.
Advantages of Leveraging Modern Data Stacks
Modern data stacks address the evolving challenges of data management. These interconnected ecosystems help businesses make data-driven decisions and offer more efficient operations.
Below are some of the benefits of utilizing modern data stacks:
Scalability and Flexibility
One of the primary advantages of modern data stacks lies in their scalability. It ensures that infrastructure can match the organization’s growing data needs. An effective modern data stack can accommodate data volume, users, and complexity spikes.
Real-Time Data Processing
Modern data stacks excel in real-time data processing, which allows organizations to make decisions based on the most current information. The real-time capability is crucial for industries that require timely insights, like finance, retail, and media.
Cost-Efficiency
With its cloud-based and scalable nature, a modern data stack is more cost-effective than traditional data stacks. Modern data stacks let organizations optimize how their resources are used by scaling up or down based on demand. This is beneficial for startups and SMEs looking to maximize their budgetary resources.
Easy Integration
Modern data stacks make integrating various tools and data sources easy. This flexibility allows organizations to break data down easily to get a more comprehensive view of their ecosystem.
Improved Data Governance and Security
Salesforce revealed that 84% of customers exhibit greater loyalty towards businesses with robust security controls. It’s no surprise that data privacy and security become a primary concern for organizations. This is why modern data stacks integrate robust governance and security features.
Cloud providers implement strong security protocols. Data warehouses offer in-depth access controls, encryption, and auditing. These features help organizations comply with regulatory standards and protect sensitive consumer information.
Common Issues When Using the Modern Data Stack
While modern data stacks offer many benefits, they are not without challenges. As organizations embrace these sophisticated ecosystems, they often encounter limitations. Some of these issues are:
Integration Complexity
One of the primary challenges of using a modern data stack is the complexity of integrating diverse components. Organizations often use a multitude of tools—one for a different purpose. While doing so is beneficial, it can still lead to potential integration bottlenecks.
Ensuring seamless communication between data storage, processing, and analytics components requires careful planning and a deep understanding of the interconnected nature of the tools.
Data Quality and Consistency
Data quality is still difficult to achieve, even with sophisticated data transformation tools. Raw data can be incomplete, inaccurate, or inconsistent. Ensuring data quality throughout its lifecycle requires organizations to develop robust data governance standards and thorough validation processes.
Cost Management
While modern data stacks offer scalability, the dynamic nature of cloud-based solutions can lead to cost management challenges. Organizations must carefully monitor and optimize resource usage to prevent unnecessary expenses.
Skill Gaps and Training
Using modern data stacks demands a trained workforce—teams proficient in various technologies and tools. Organizations might struggle to hire talents with expertise in cloud platforms, data engineering, and analytics.
Investing in training programs and professional development is important to let businesses address skill gaps and ensure that their teams can use modern data stacks to the fullest capabilities.
Performance Optimization
Achieving optimal performance in a modern data stack requires continuous tuning and optimization. Organizations may struggle with query performance, data pipeline efficiency, and response times. Regular monitoring, performance tuning, and periodic reviews are needed to mitigate issues.
The challenges associated with modern data stacks highlight the evolving nature of data. While those obstacles may seem overwhelming, they are also opportunities for growth and improvement.
By tackling the issues head-on, organizations can unlock the full potential of their data stacks. However, navigating the complex data landscape requires the right tools.
How Edge Delta Solves The Modern Data Stack Issues
Edge Delta solves multiple of these issues for teams practicing observability. Deployed as a software agent, Edge Delta sits at the data source – connecting all your data sources to your destination. As a result, you can remove integration complexity.
Once deployed, your engineers gain an easy way to shape and enrich data according to their needs. Moreover, Edge Delta automatically formats data into the OTel schema, driving data quality and consistency across all analytics platforms.
As a byproduct of these capabilities, you can reduce your data footprint to control costs. Additionally, processing data upstream enables you to identify the “needles” in your “haystack” of data to avoid issues.
Do you want to unlock the true potential of your modern data stack? Start your free Edge Delta trial today to see how this observability platform can help you achieve data-driven success.
Key Differences Between Modern Data Stack and Legacy Data Stack
The management and analysis of data have undergone a shift since modern data stacks appeared. A modern data stack differs greatly from the traditional one. Learn more about the differences between the two below.
Cloud-Native Architecture
Traditionally, data infrastructure relied heavily on on-prem solutions. This involves substantial hardware investments with maintenance costs.
Adopting cloud-native architecture, the modern data stack leverages the scalability and flexibility of cloud platforms. This allows organizations to scale resources on demand and reduce infrastructure overhead.
Integration and Compatibility
Legacy data stacks often face challenges in integrating new data sources and technologies. This often leads to isolated data and inefficient workflows.
Modern data stacks boats seamless integration. They support a wide variety of data sources, applications, and tools. This fosters a broader approach to data management.
Data Warehousing
Traditional data warehousing solutions involve monolithic structures. This makes it challenging to adapt to dynamic business needs and changes in data volume.
Modern data stacks leverage distributed data warehousing solutions, which enables organizations to store and process vast amounts of data efficiently. For this reason, modern data stacks can handle the growing data needs of businesses.
Data Processing and Analysis
Batch processing was the norm in legacy data stacks, which resulted in delayed insights and limited real-time analytics capabilities.
On the other hand, modern data stacks support batch and real-time processing using advanced data processing engines and technologies. Actionable insights are derived promptly and adapted swiftly to changing market dynamics.
Data Governance and Security
Legacy data stacks often struggle with comprehensive data governance and security frameworks, making it challenging to comply with evolving regulatory standards.
Modern data stack integrates robust governance and security measures to address data privacy concerns. Features such as encryption, access controls, and audit trails ensure compliance with data protection regulations.
Check the table below for a quick rundown of the differences between legacy and modern data stacks.
| Aspect | Legacy Data Stack | Modern Data Stack |
|---|---|---|
| Cloud-Native Architecture | On-prem with high costs | Cloud-based and scalable; Cost-efficient |
| Integration and Compatibility | Limited integration; Isolated data | Seamless integration; Supports diverse sources |
| Data Warehousing | Monolithic; Challenging to adapt | Distributed; Efficient storage adaptable to business needs |
| Data Processing and Analysis | Batch processing; Delayed insights | Batch and real-time processing; Quick actionable insights |
| Data Governance and Security | Limited security; Compliance challenges | Robust security; Compliance with data protection standards |
The Evolution of Modern Data Stack
The evolution of the modern data stack has been driven by the need for more efficient and scalable solutions to handle the growing volume and complexity of data. Below is a comprehensive timeline of its evolution.
- Early Data Processing (1960s-1980s): The journey of the modern data stack can be traced back to when organizations relied on mainframe systems for data processing. During this period, data management systems were used to organize and retrieve data.
- Relational Databases (1980s-1990s): The widespread adoption of relational models like Oracle and IBM Db2 marked this era. While aiming for data storage and management, relational databases provide a structured and organized approach to handling data.
- Enterprise Data Warehousing (1990s-2000s): Organizations faced challenges in dealing with massive data volume, so the concept of data warehousing emerged. Companies like Teradata and Oracle pioneered the development of enterprise data warehouses.
- Birth of ETL Tools (2000s-2010s): The need to integrate data from different sources led to the rise of ETL tools. Informatica, Talend, and Apache Nifi gained popularity for their ability to extract data from other systems, transform it into a consistent format, and process it into a database or data warehouse.
- NoSQL and Big Data Technologies (2010s-2015): The increase in unstructured and semi-structured data prompted the adoption of NoSQL databases and big data technologies. Apache Hadoop, MongoDB, and Cassandra became key players, helping organizations handle diverse data types at scale.
- Cloud Data Warehouses and Data Lakes (2010s-Present): The data landscape changed with cloud computing. Cloud data warehouses like Google BigQuery and Snowflake emerged, offering scalable and cost-effective solutions. Simultaneously, data lakes became popular for holding extensive raw and unstructured data.
- Modern Analytics and Business Intelligence (2015-Present): The modern data stack expanded to include advanced analytics and business intelligence tools. Tableau, Looker, Power BI, and other technologies allowed organizations to visualize and derive real-time insights from their data.
- DataOps and Data Governance (2020s-Present): DataOps practices and data governance solutions have become integral parts of the modern data stack. These aim to streamline collaboration, automate workflows, and ensure data quality.
The evolution of the modern data stack reflects the dynamic nature of data and the continuous efforts of organizations to address challenges and opportunities. The prospective transformations will undoubtedly influence the future of the modern data stack’s data management and analytics.
Conclusion
Modern data stacks have become the spine of data-driven decision-making in organizations of all sizes. They are essential for extracting valuable insights from your data to make informed decisions, increase scalability, and reduce costs.
While challenges exist in integration, data quality, and expertise, navigating modern data stacks allows businesses to thrive in this data-driven world. Embrace the future of data management and unlock its full potential with modern data stacks.
Modern Data Stack FAQs
How does the stacked data structure work?
The stack data structure is similar to how a stack of plates works. It operates on a “Last In, First Out” (LIFO) principle. You can only add (push) or remove (pop) elements from the top. This approach is ideal for tasks like keeping track of function calls, browser history, or undoing edits in software.
What are the three things to consider while building the modern data stack?
Building a modern data stack focuses on these three aspects: alignment with specific goals, agility for future needs, and robust security. Define your data-driven objectives, then choose tools that scale alongside evolving requirements. Finally, prioritize data privacy by implementing strong security measures throughout your stack.
What is a data analytics stack?
A data analytics stack is a collection of integrated tools that transform raw data from various sources into valuable insights.
Sources