


AI has fundamentally changed how software gets built. Tools like Cursor, Copilot, and Claude Code have made it possible for smaller teams to ship more code at higher velocity than anyone thought feasible even a few months ago. Developers who used to write hundreds of lines a day now manually (or using an AI agent!) review thousands, and that acceleration does not stop at the merge.
Every line of code shipped is a line someone has to manage. Production environments are growing in volume, surface area, and change velocity, and the humans responsible for them are quickly losing the ability to keep pace. The same AI wave that unlocked development productivity has made the operations problem significantly harder.
Observability, as most teams practice it today, was built for an earlier era. Dashboards, alert thresholds, and traditional on-call rotations were designed around the assumption that humans were the main watchers, operators, and diagnosers. With the advent of agentic workflows, that model and the underlying assumptions no longer hold. The bottleneck has moved. It used to be in development. Now it is in production. Observability has to be rethought: from a tool engineers reach for during incidents, to a system that runs continuously, hardens production over time, and surfaces only what requires human judgment.
How Observability Was Built
The primitives of modern observability tell you a lot about the assumptions behind them. Dashboards display metrics for a human to look at, while alert rules encode what a human decides to care about. PromQL and LogQL are query languages that require a person to understand the intricacies of their respective syntaxes before an answer can surface, and on-call rotations exist in their current instantiation primarily because the system assumes a human will always be needed.
The knowledge that makes this system function is rarely documented anywhere it can be recovered. It lives in postmortems that get read once and archived, in Slack threads that are always difficult to find, and most significantly in the heads of senior engineers who have seen the same failure mode often enough to diagnose it in two minutes while everyone else is still reading dashboards and trying to form a mental model of what is happening. Getting teams aligned on even basic questions like what to monitor tends to require cross-team coordination, and the institutional knowledge required to operate the system well accumulates in individuals rather than anywhere the organization actually owns.
This was a functional model for an era when code shipped on a human schedule, production environments changed slowly, and a small team of experienced engineers could reasonably stay on top of it. That era is ending.
What Changed
Progress in foundational models over the last two years has been decisive. Models can now perform long-horizon reasoning across large, complex contexts, use tools reliably, chain together multi-step operations without falling apart, and correlate signals across systems in ways that make it possible to form hypotheses and propose actions that a human can evaluate and approve. Work that previously required a skilled engineer to read the signals, pull context from multiple sources, form a mental model of what was happening, and decide what to try can now be done autonomously.
The harder question is where to deploy that capability. Agents have proven themselves in environments that are controlled and self-contained, where feedback loops are tight and mistakes are recoverable. Production is different in almost every way. It is live, constantly shifting, and unpredictable in ways no development environment can replicate. Services interact in combinations that were never tested. The system that was stable an hour ago is already a different system. When agents move from contained settings into production, the cost of getting it wrong is direct customer impact.
Why Observability Is a Hard Place to Deploy Agents
There are a number of reasons the observability problem is genuinely hard for agents, each capable of causing failure on its own.
Scale. Production environments generate telemetry at a volume that most agent architectures were simply never designed to handle: petabytes of logs, metrics, traces, and events streaming continuously from hundreds or thousands of distributed services. Context windows overflow, meaningful signals get buried under noise, and correlations that depend on detecting patterns across large time windows become unreliable in ways that are difficult to detect and even harder to debug. The data volume problem alone is sufficient to break most naive approaches before they produce anything useful.
Speed. Unlike most domains where agents work against static or slowly changing data, observability operates on live streaming feeds where the relevant window can close in seconds. When a service begins degrading, the gap between first signal and meaningful customer impact is often far shorter than the time it takes a batch-oriented agent to gather context, form a hypothesis, and surface a conclusion, which means that by the time the analysis arrives, the damage is already done.
Fragmentation. Telemetry captures what the system is doing, but understanding why typically requires context scattered across half a dozen different systems. Deployment history lives in GitHub, cluster state lives in Kubernetes, on-call history and past escalations live in PagerDuty, and the team discussions where engineers talked through the last similar incident live in Slack. Stitching all of this together manually, under pressure, during an active incident, is consistently one of the most time-consuming parts of incident response, and an agent working only from telemetry is, by definition, operating on an incomplete picture of what actually happened.
Trust. Production is where customers live, and an agent with the ability to modify infrastructure, restart services, or roll back deployments can cause an outage if it gets the reasoning wrong, meaning the cost of a mistaken autonomous action can easily exceed the cost of the incident that prompted it. Teams need complete visibility into what the agent saw, how it reached its conclusion, and what it is and is not permitted to do, and without a system that provides that transparency and makes guardrails configurable, agents end up stuck in advisory mode indefinitely because no reasonable team will grant real autonomy to a black box operating in production.
A Model of Production Is Necessary, But Not Sufficient
One response to the problem is to build a continuously updated, AI-readable representation of the production environment: a living model that agents can query to understand current system state, capturing topology, dependencies, deployment history, and behavioral baselines in a form that enables meaningful reasoning. This is genuinely part of the answer.
The limitation is that a model alone amounts to a smarter dashboard, one that improves the quality of answers without changing who is responsible for asking the questions or doing something about them.
Turning a production model into actual outcomes requires three things to be in place alongside it. Data control comes first: governance over what enters the model, including the ability to filter noise, mask sensitive data, and enrich signals with context before they reach the agent, because a model trained on raw, unfiltered telemetry inherits all of its noise and produces reasoning that reflects it. Auditability comes second: a clear record of what the agent saw, what it hypothesized, and what actions it took, visible to the humans accountable for the system, because without that transparency trust cannot be extended incrementally. A configurable action layer comes third: the ability to define precisely what the agent can do autonomously and what requires a human decision, because without it the loop stays open and the model never becomes more than a sophisticated read-only interface.
The production model is the foundation. The stack built around it determines whether any of it produces outcomes.
Why Bolting an Agent Onto Your Existing Stack Falls Short
The most common approach to agentic observability is to place an AI layer on top of existing infrastructure: connect an LLM to your current data store, add a natural language interface, and let engineers query it. The appeal is obvious because it deploys quickly and requires almost no architectural change.
The agent, however, inherits every limitation of the stack underneath it. If the underlying data is noisy, the agent reasons over noise. If there are coverage gaps, the agent works around them without knowing they exist, which means the gaps never surface as problems until something important gets missed. If the data arrives raw and unfiltered, the agent either times out trying to process query volumes it was not designed for, or it produces correlations that look plausible but fall apart the moment an engineer tries to act on them.
The deeper problem is the absence of any guardrail layer. Without governance over what the LLM has access to, trust never gets established because there is no mechanism for establishing it, and the agent stays permanently in advisory mode because no reasonable team will grant autonomous action to a system operating over an ungoverned data layer in a production environment. The bolt-on approach produces observability with an LLM attached to the side, which is a meaningful improvement to the query experience but leaves the underlying model of how production gets managed completely unchanged.
The Edge Delta Approach: Built for Agents from the Ground Up
Solving this problem requires rethinking the stack from the bottom up, starting with where data is generated and working up through how it is stored, reasoned over, and acted on, rather than adding intelligence at the top and hoping the foundation beneath it can support the weight.
Telemetry Pipelines: Data control at the source
Edge Delta’s pipeline layer processes telemetry at the edge, before it reaches any central store, filtering, enriching, normalizing, and shaping data in real time and at scale so that what flows downstream is already structured for meaning rather than just volume. High-cardinality noise is reduced before it becomes a context problem for agents, and PII, secrets, and sensitive customer data are masked at the source so that agents only ever have access to what the team has explicitly permitted them to see. Beyond cost reduction, the pipeline is where data governance lives and where the difference between reliable agent reasoning and noisy agent reasoning gets determined.
Observability Platform: The system of record agents can reason over
Every signal, hypothesis, and action taken by a Teammate is visible, traceable, and auditable through the platform, giving teams a clear view of what the agent saw, what it concluded, and the reasoning that connected the two. Autonomy is configurable across a full range, from notify-and-recommend through opening incidents automatically to executing remediations directly, depending on the team’s risk tolerance and how much track record the Teammate has established, because trust is something teams extend incrementally as they validate that the agent’s judgment holds up over time.
AI Teammates: The agentic layer
AI Teammates are a coordinated team of specialized agents, each built for a distinct role, that work together from detection through remediation without requiring a human to bridge the gaps between them.
The OnCall AI Teammate monitors production continuously, trained to surface meaningful signals from the volume of telemetry your environment generates and route issues to the right place with initial findings already attached. Once an issue is identified, the Work Tracker Teammate begins updating work items to track it as the investigation continues.
The SRE Teammate handles what comes next. Instead of loading raw telemetry directly into a context window, it spins up a sandbox, streams the relevant data into it, and writes code to analyze the logs in real time, processing volumes that would overwhelm a conventional agent approach while keeping the experience for the team as simple as reviewing a finding. The sandbox is created and destroyed on the fly, entirely in the background, so what the team sees is a clear answer with all the infrastructure that produced it abstracted away.
When the SRE Teammate has traced the issue to its root, the Software Engineer Teammate clones the repository, identifies the appropriate fix, and opens a pull request with the full reasoning attached and the change staged for human review before anything touches production. In parallel, the Security Engineer Teammate scans the PR for vulnerabilities, leaked secrets, and other risks to ensure the fix is secure before it progresses further.
Throughout the investigation, Teammates work across the full connected stack via MCP integrations, pulling deployment history from GitHub, querying Kubernetes for cluster state, reviewing PagerDuty for related incidents, and surfacing relevant Slack conversations where additional context often lives, so that by the time a finding reaches an engineer it reflects a complete picture drawn from every system the team relies on.
AI Teammates in Production
To see AI Teammates in action, let’s walk through a real incident from our playground environment.
On a Monday afternoon, the offerservice running in the easytrade namespace had begun generating an unusual volume of log warnings, though nothing on the surface pointed to a serious problem. Request and response traffic looked normal, error logs stayed quiet, and log volume held flat, the kind of signal that a human scanning a dashboard might easily overlook or attribute to background noise.
Edge Delta’s OnCall AI Teammate caught the pattern early and, within a few minutes of the anomaly window opening, had surfaced roughly 4,000 occurrences of “Value of env var [MANAGER_PROTOCOL] is undefined,” each paired with a “Using default value [http] for env var [MANAGER_PROTOCOL]” fallback message.
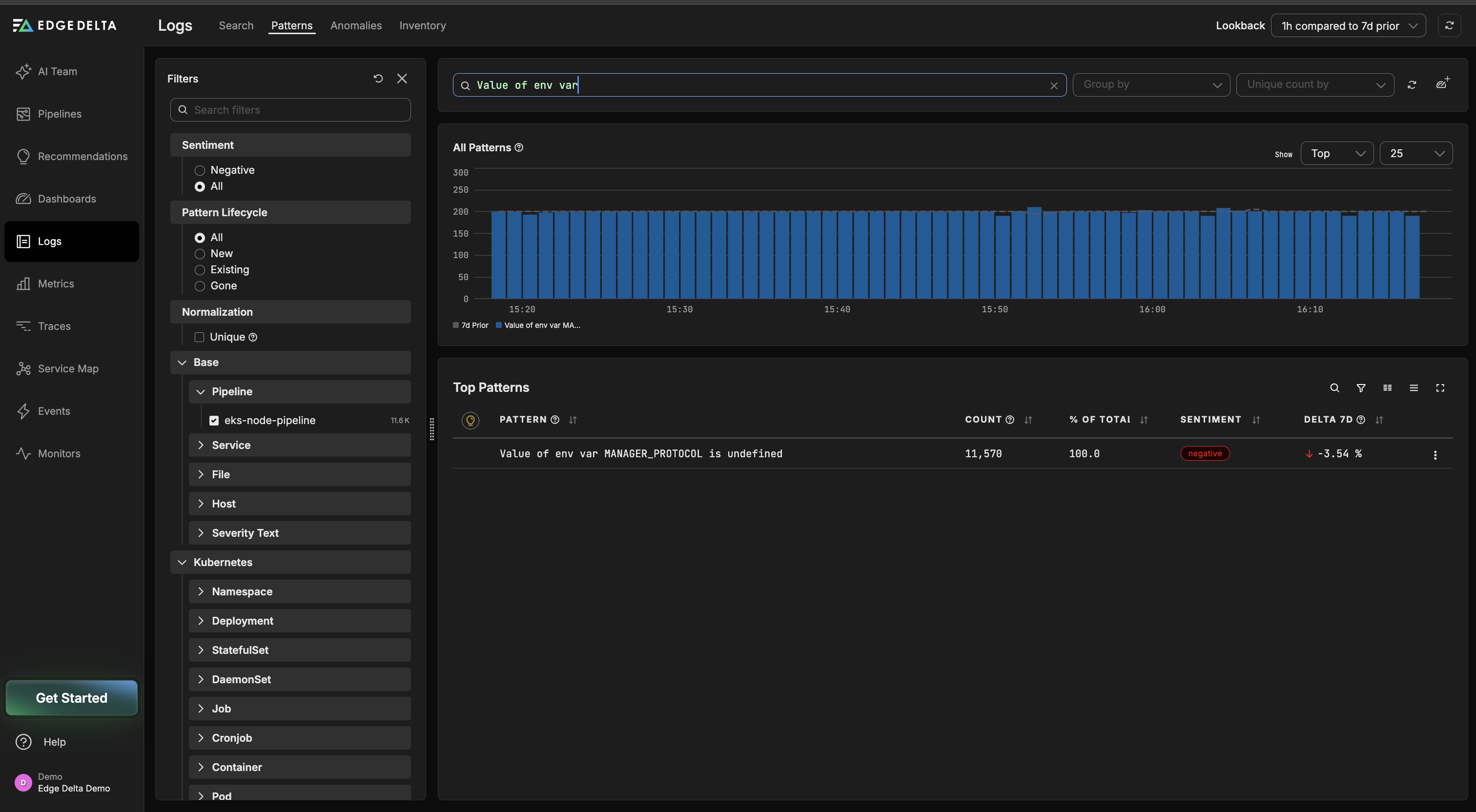
With no active service degradation detected, the OnCall Teammate retrieved past incident context from memory and quickly flagged it as a configuration issue, before routing the investigation to the SRE Teammate with its initial findings already attached.
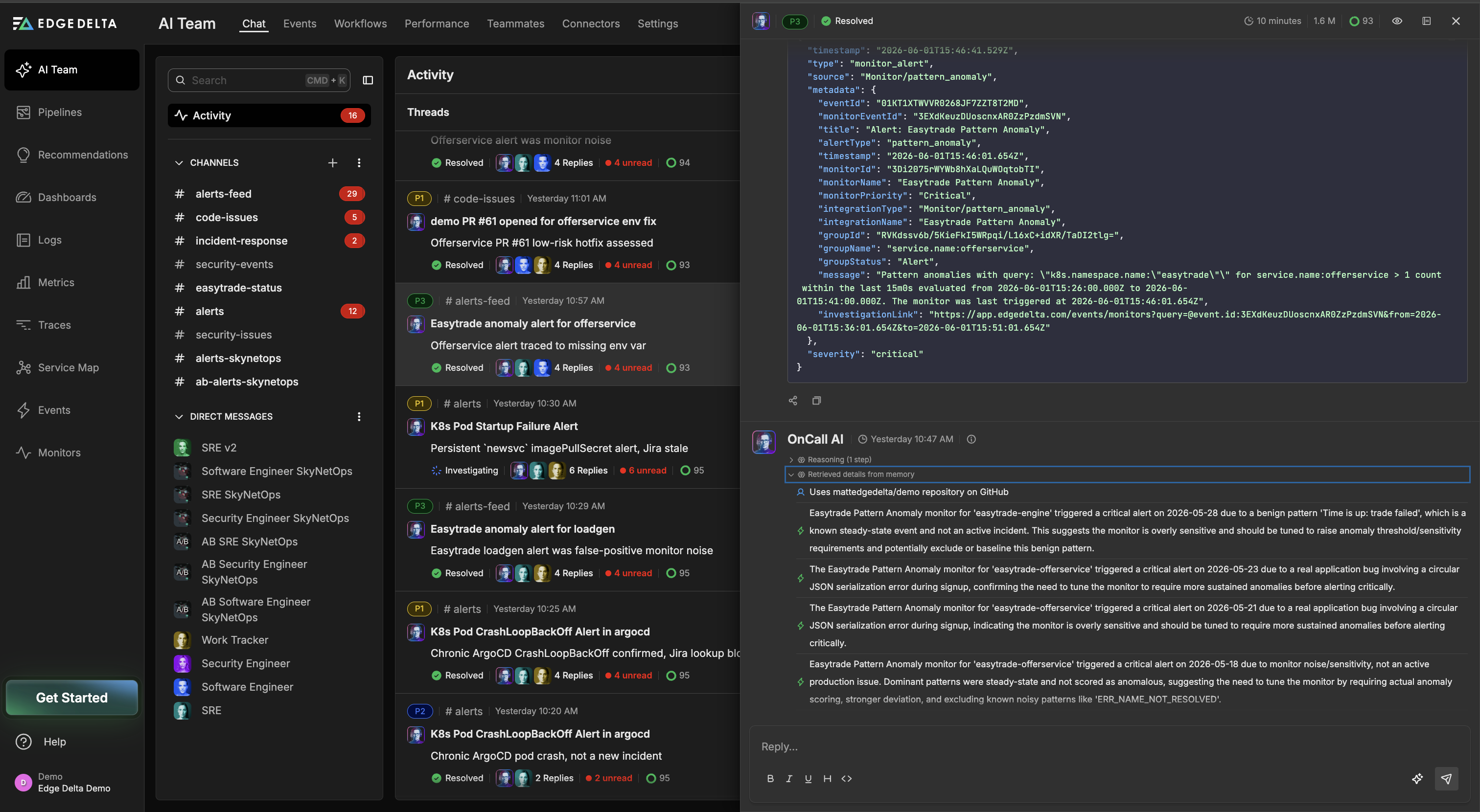
While the Work Tracker Teammate began documenting the investigation, the SRE Teammate worked through the telemetry without waiting for direction, confirming that request traffic was unaffected, ruling out the prior circular JSON and signup issues that had appeared in earlier incidents, and tracing the warning back to a configuration gap that had been partially addressed multiple times without ever being fully resolved.
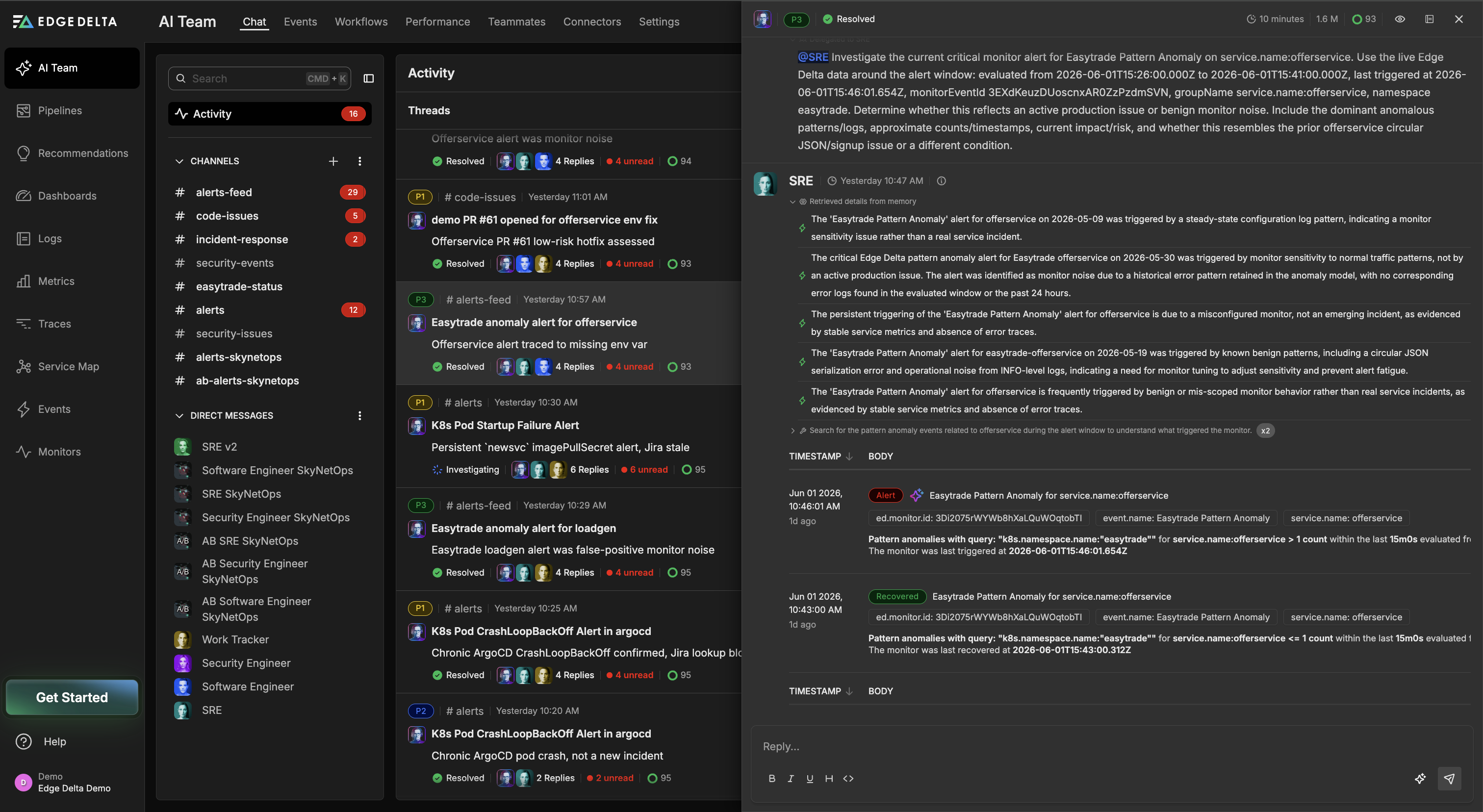
It turns out that MANAGER_PROTOCOL was already defined under offerservice.env, but a series of prior rollout-only fixes had treated the symptom each time rather than the underlying cause, which meant every new rollout surfaced the same warning at the same volume. With a clear root cause identified, the Software Engineer Teammate cloned the repository, located the relevant configuration in easytrade/helm/easytrade/values.yaml, and added MANAGER_PROTOCOL: "http" to global.env, addressing the issue at the right level of the configuration hierarchy rather than reaching for another service-level override.
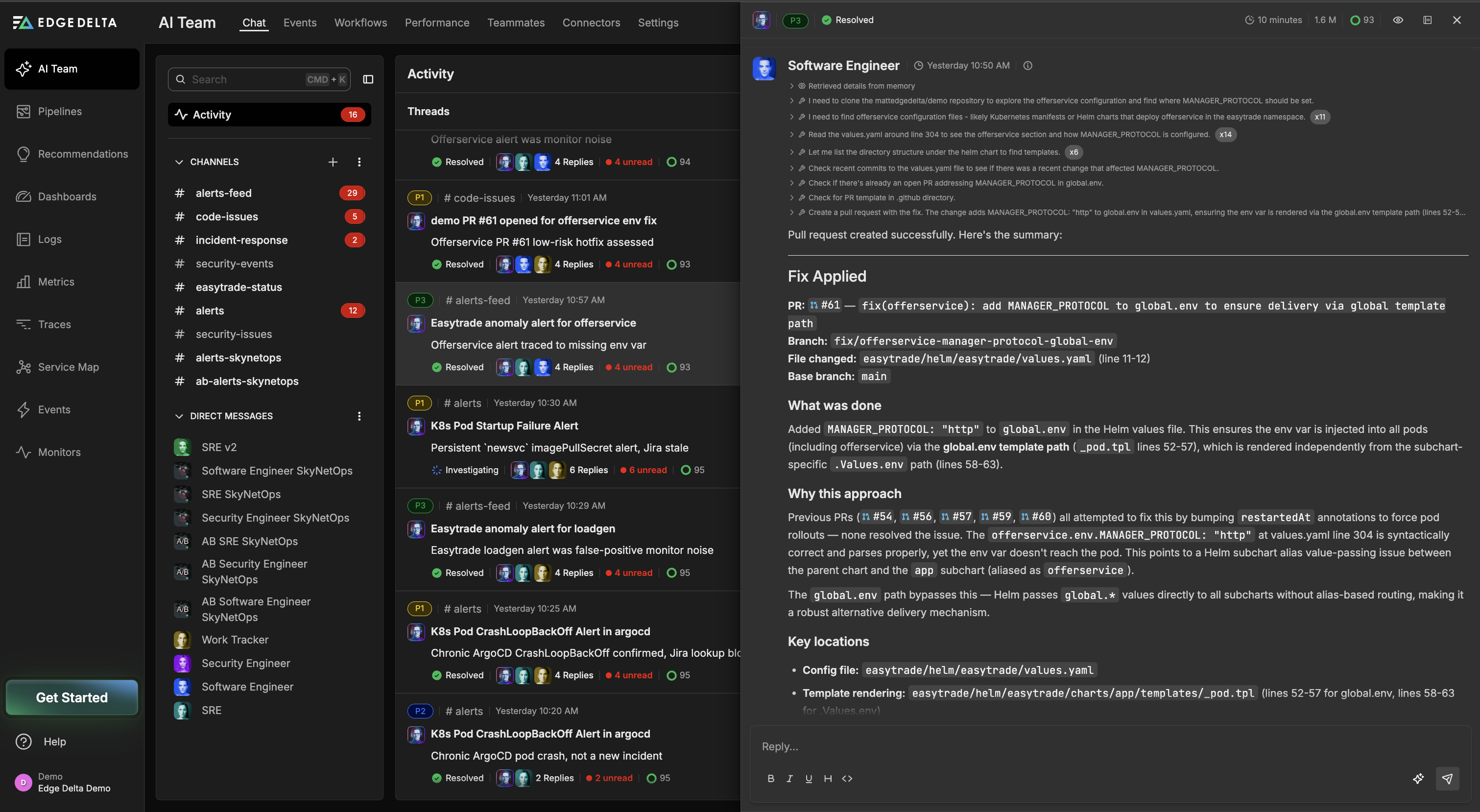
PR #61 was opened from branch fix/offerservice-manager-protocol-global-env with a targeted change and the full reasoning visible to whoever reviewed it.
The entire cycle, from the first anomalous log to a staged fix ready for human approval, completed in under fifteen minutes, with no engineer paged, no manual context reconstruction, and no digging through prior postmortems to understand why the same issue had kept recurring. The Teammates identified the problem, traced it to its root, and handed an engineer a decision rather than an investigation.
What This Changes for Engineers
In this new world of agentic-first observability, when the stack is built correctly, remediation looks very different. Most alerts never reach a human because noise has been suppressed and low-risk issues are handled automatically by Teammates operating within established guardrails. Higher-risk changes get staged for a single approval click rather than requiring the on-call engineer to reconstruct context from scratch at 2 AM, and the on-call experience as a whole shifts from reactive firefighting toward reviewing a clear summary of what happened, what was already addressed, and what still requires a human decision. Ownership moves in this model rather than disappearing (an important distinction) and engineers stop being first responders who need to be reachable around the clock and start being the people who set the boundaries, approve the consequential calls, and decide over time how much autonomy the system has earned.
The system also compounds: every incident builds the agents’ understanding of the topology, the recurring failure patterns, and the team’s own preferences, so the longer it runs the more effective it becomes and the harder the advantage it creates is to replicate. Engineers become orchestrators of systems that can reason over production continuously, surface what matters, and act within the limits the team defines. That is a meaningfully better version of the job, and it is available now.
Conclusion
The above scenario, where a configuration gap was detected, traced to its root cause, and resolved with a staged pull request in under fifteen minutes with no engineer paged, is a representative example of what Edge Delta’s AI Teammates handle in production every day. Alerts that used to surface at 2 AM start getting resolved before anyone is paged, incidents arrive as clear summaries with a decision attached rather than a thread to unravel, and the on-call experience, which for most teams has long been the most draining part of the job, starts to look and feel fundamentally different. Over time, the system builds an understanding of your production environment that no individual engineer could carry alone, giving the team a level of coverage and consistency that scaling headcount never would have provided.
This world is here. If you are ready to see what it looks like in your environment, activate Edge Delta’s AI Teammates with the click of a button.



