

Kubernetes environments generate massive volumes of telemetry data, but infrastructure issues are notoriously difficult to troubleshoot, even for experienced SREs. With the typical Kubernetes adopter now running over 20 clusters with more than 10 software elements across multiple clouds and data centers, a pod crash might stem from resource constraints, network policies, or upstream service failures, while autoscaling inefficiencies can be buried across thousands of metrics. SREs are forced to pivot between monitoring dashboards, log explorers, and kubectl commands while troubleshooting, which delays resolution and increases their MTTR.
Edge Delta’s AI Teammates transform this workflow by continuously monitoring and analyzing telemetry data from Kubernetes clusters, and automatically correlating it with other observability and security data from across your stack. For example, these out-of-the-box AI agents can identify that a CrashLoopBackOff is caused by a missing ConfigMap from a recent deployment, detect inefficient HPA configurations draining your cloud budget, or surface node resource pressure before pods start getting evicted. This helps SRE teams resolve issues faster, reduce manual toil, and maintain more reliable infrastructure.
In this post, we’ll first discuss how to stream Kubernetes data into Edge Delta so that your AI Teammates can use it in their workflows. Then, we’ll explore three common Kubernetes scenarios where AI Teammates expedite troubleshooting and transform reactive firefighting into proactive infrastructure management.
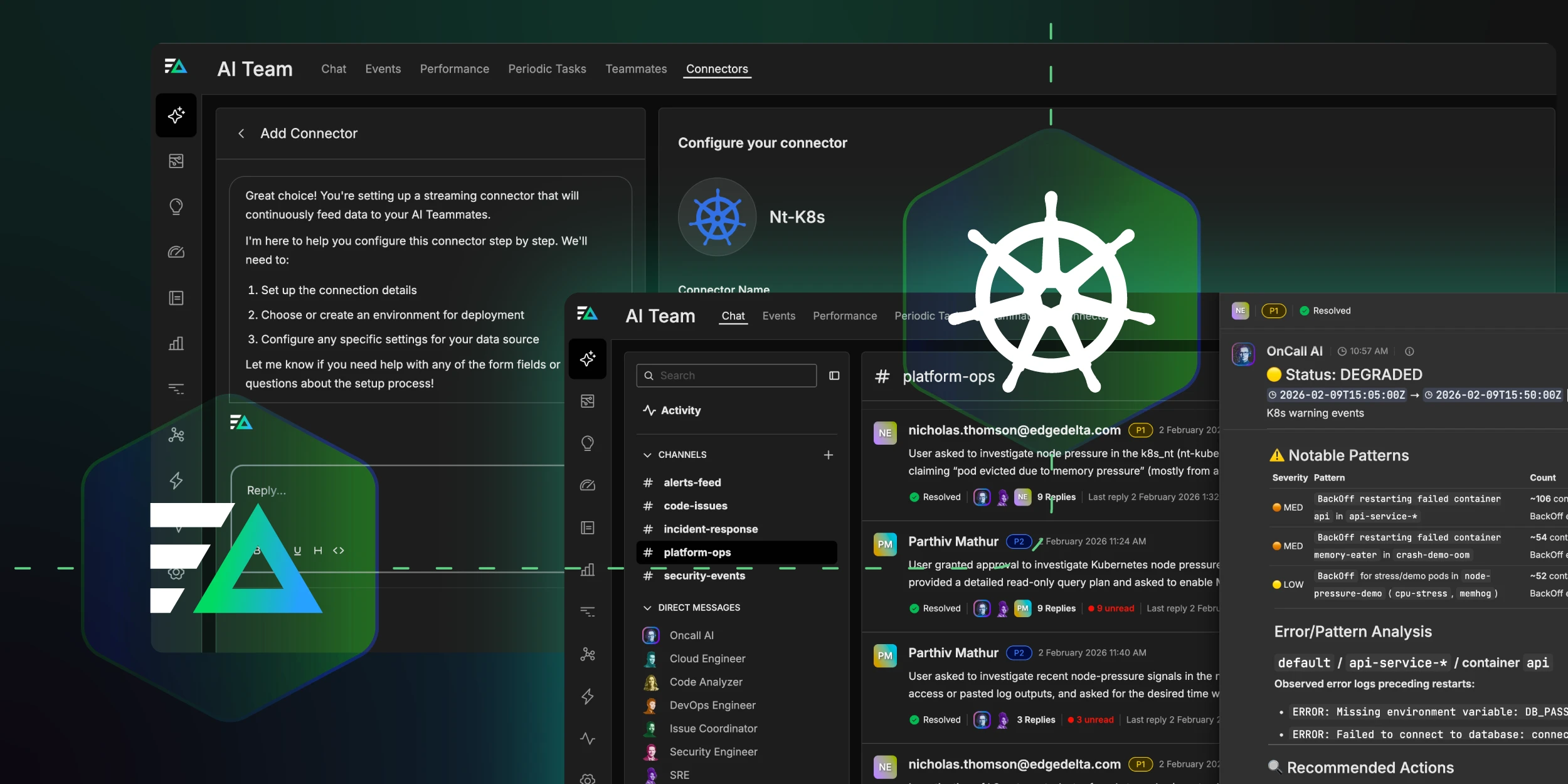
Set Up the Edge Delta Kubernetes Connector
Edge Delta provides a native Kubernetes Connector that makes it easy to ingest pod logs, cluster events, and resource metrics with minimal setup. From there, AI Teammates continuously learn from your specific environment’s patterns and behaviors, becoming more effective at predicting and preventing issues over time.
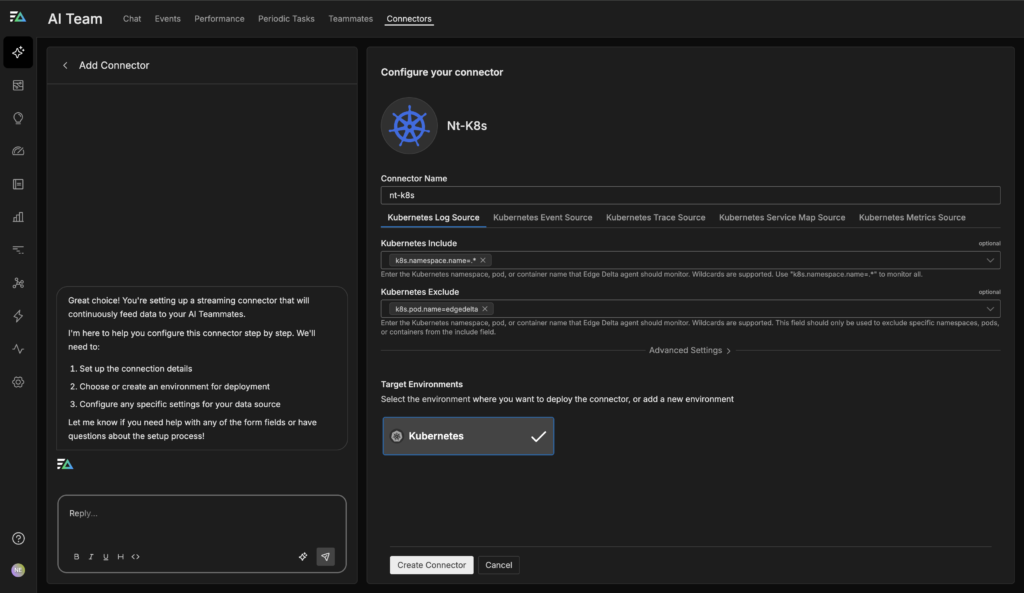
When deployed alongside a Kubernetes pipeline, the Edge Delta Kubernetes Connector creates a direct path from cluster activity to AI-driven investigation. The Connector continuously reads logs, events, and metrics from the Kubernetes cluster and securely uploads them to the Edge Delta Observability Platform, where the data is processed, enriched, and indexed in a Kubernetes-aware model. AI Teammates then use the Edge Delta MCP server to query this indexed telemetry data in real time, correlating signals across clusters, namespaces, and workloads to automate investigation, root cause analysis, and remediation guidance.
Resolve Pod CrashLoopBackOff
A single misconfiguration can send a pod into CrashLoopBackOff and trigger a scramble across logs, events, and deployment history. With AI Teammates, that scramble becomes an automated workflow.
When a Kubernetes alert fires for a CrashLoopBackOff, Edge Delta AI Teammates immediately move from detection to coordinated investigation. OnCall AI receives the alert and automatically tasks the SRE Teammate with gathering the relevant context — pulling pod logs, Kubernetes events, and recent deployment history within the affected pipeline and cluster. Instead of forcing an engineer to manually pivot between dashboards, the SRE Teammate correlates crash patterns with configuration changes, surfacing clear causal signals such as a missing environment variable like DB_PASSWORD, unreachable database endpoints, or OOM conditions from memory limits set too low.
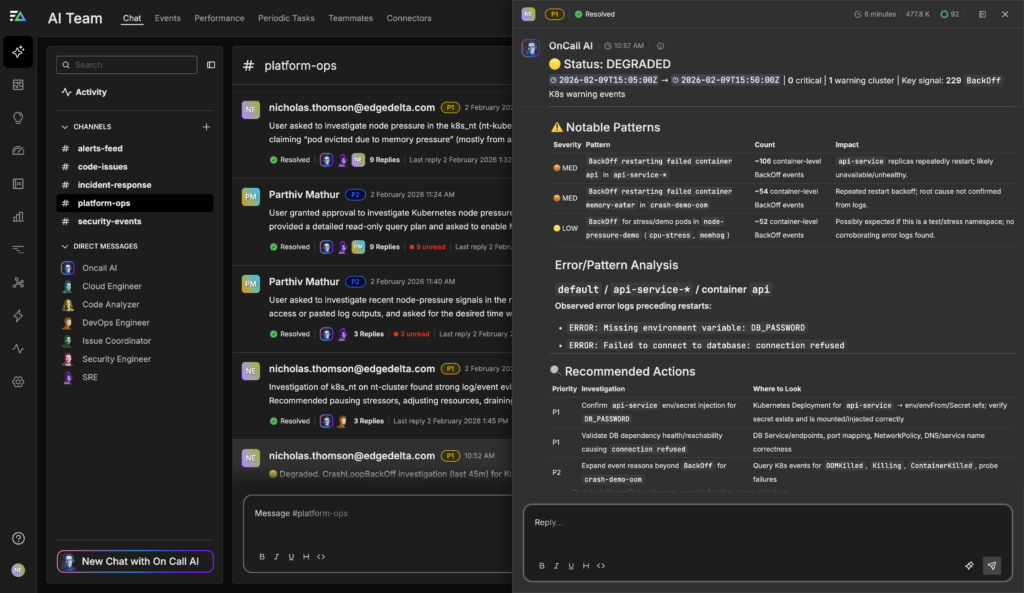
In the example above, the AI Teammate analyzed 229 BackOff events across multiple namespaces, identified the api-service deployment as the primary offender with 106 container-level failures, and correlated error logs to pinpoint two root causes: a missing DB_PASSWORD environment variable and database connection refused errors. The investigation distinguished between genuine production issues and expected test noise in stress-testing namespaces, demonstrating pattern recognition across different failure modes.
Once the likely root cause is identified, the SRE Teammate recommends prioritized remediation steps — in this case, verifying secret injection for DB_PASSWORD and validating database service health and reachability — with the option to auto-apply fixes while retaining rollback capability. OnCall AI then delivers a structured summary of affected resources, root causes, and recommended actions (ranked P1/P2/P3 by priority), so the human operator stays informed without being pulled into the weeds.
Fix Inefficient Horizontal Pod Autoscaler (HPA) Configuration
Autoscaling is meant to smooth out demand, but when thresholds are too aggressive, it can introduce instability instead of resilience. AI Teammates continuously analyze workload behavior across your cluster, correlating replica counts, CPU utilization, and scaling decisions to identify when an HPA is reacting to noise rather than sustained load.
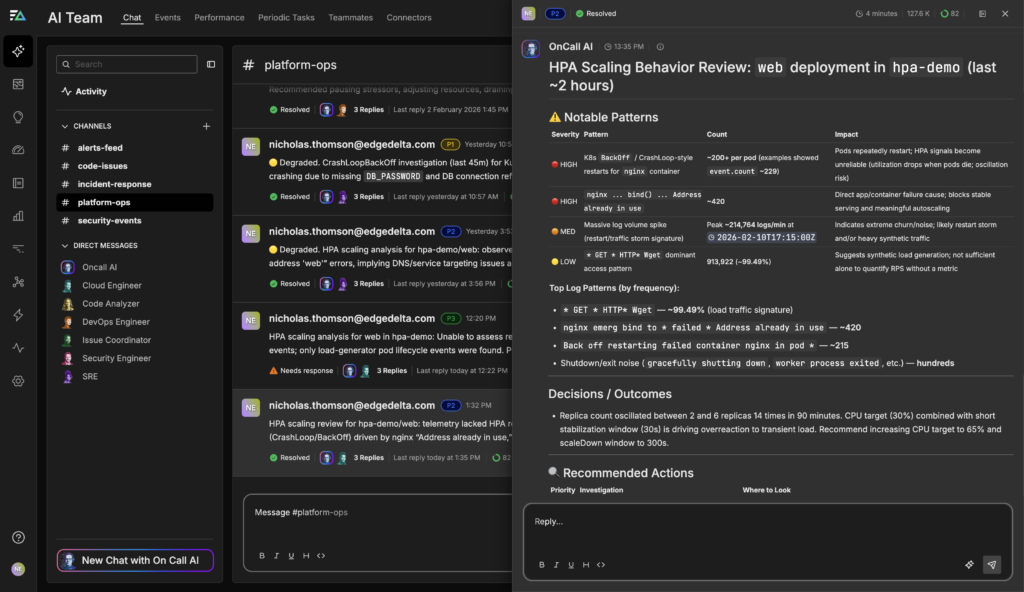
In this example, the web deployment’s replica count oscillated between 2 and 6 replicas 14 times in just 90 minutes. The combination of a low 30% CPU target and a short 30-second stabilization window caused the HPA to overcorrect on transient spikes, creating unnecessary scaling churn, pod restarts, and avoidable infrastructure cost.
By analyzing scaling frequency, replica deltas, and utilization patterns over time, AI Teammates distinguish between healthy elasticity and true thrash. Instead of simply flagging high CPU, they surface scaling volatility as the signal, alerting when replica changes exceed expected variance within a given time window.
In addition to highlighting the issue, AI Teammates recommend tuned parameters, increasing the CPU target to 65% and extending the scale-down window to 300 seconds. Before applying changes, the system can simulate impact and estimate cost implications, enabling confident, data-backed autoscaling decisions as traffic patterns evolve.
Rightsize Under-provisioned Nodes
When multiple pod evictions or scheduling failures indicate a capacity problem, SREs traditionally face a time-consuming investigation across node metrics, deployment configurations, and resource requests to determine the right fix. With AI Teammates, this multi-step diagnostic becomes an automated, coordinated workflow.For example, if Kubernetes alerts fire for pods stuck in Pending state, Edge Delta AI Teammates immediately shift from detection to systematic investigation. OnCall AI receives the alert and tasks the SRE Teammate with analyzing the cluster’s resource pressure, pulling FailedScheduling events, examining node capacity metrics, and identifying which workloads are unable to schedule. Rather than forcing an engineer to manually correlate data across kubectl commands and monitoring dashboards, the SRE Teammate surfaces the precise constraint: in this case, four data-processor pods blocked with 0/1 nodes available due to insufficient memory.
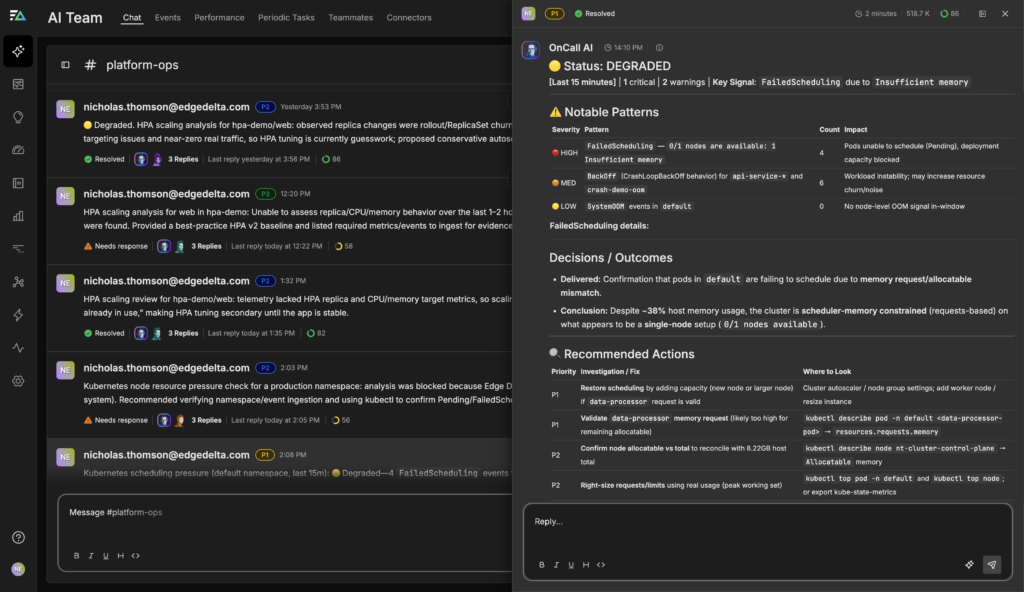
The SRE Teammate goes beyond surface-level metrics to provide context that matters for decision-making. While host memory usage sits at a seemingly comfortable 38%, the AI recognizes that Kubernetes scheduling operates on resource requests versus allocatable capacity, not actual usage. It identifies the critical gap: even with low observed utilization, the scheduler has exhausted available memory allocatable, preventing new pods from being placed. The investigation also flags adjacent workload instability (CrashLoopBackOff patterns from other deployments) that may be contributing to resource churn and noise.
Once the constraint is identified, OnCall AI delivers prioritized remediation options. The P1 recommendations address immediate capacity needs: either scale the cluster by adding a worker node to expand allocatable memory, or validate and reduce the data-processor memory requests if they exceed actual requirements. P2 actions focus on confirming the exact allocatable-versus-requests calculation and rightsizing based on real usage patterns from kubectl top metrics. The AI also provides bin-packing context, noting this is a single-node cluster where scheduling options are inherently limited.
Get Started
Edge Delta’s AI Teammates deliver measurable impact from day one. Operational toil drops as AI Teammates handle repetitive investigation workflows autonomously, freeing your team from constant context-switching between dashboards, kubectl commands, and TicketOps. The result is improved cluster reliability through faster incident response and proactive issue detection before users are affected.
This shift marks a fundamental change in how SRE teams operate. AI Teammates autonomously handle routine troubleshooting, pattern recognition, and first-pass remediation, while humans focus on novel architectural challenges, capacity planning, and continuous improvement initiatives. It’s what observability looks like in the age of agentic AI.
Try AI Teammates yourself with a free trial.



