


The logging world will change. And though I certainly have a horse in the race, it’s going to change regardless of the winner. I’ve spent most of my career working with observability tools, and it only takes a not-so-long stroll back in time to see precisely why I believe that change is coming.
APM Evolved to Uncover Meaningful Insights from Large Volumes of Data
Though the logging world has remained much the same in the last decade, Application Performance Management (APM), in comparison, has gone through substantial changes. APM was all about deep transaction tracing down to the method level over ten years ago. That was the key to understanding what was going on in monolithic applications at the time. As the world moved more towards microservices with Docker, Kubernetes, and others, going down to the method level became less critical and extremely noisy. With microservices becoming more prevalent, APM shifted towards time-series metrics, which are much more meaningful in the large data world and allow users to identify irregularities quickly.
Centralized Logging Tools Have Grown in Cost, but Not Value
Centralized log management tools took the world by storm in the mid-2000s, and since then, we’ve been putting more and more functionality into them. Unfortunately, the return on investment has not kept up – logging costs have skyrocketed with little additional insights to justify the out-of-control costs.
The increase in logging volume hasn’t gone unnoticed. To save costs and derive more value from logs, companies have adopted increasingly complex logging strategies. The basic premise is there’s stuff that doesn’t need to be logged – or at least you hope not. So, you can lower ingest and index volumes by filtering out those data sets. Executing this strategy means you have to predict what’s important and what’s not important ahead of time. Usually, this is done by looking at what types of dashboards and rules you already have set up in your centralized logging solution to understand what is being used.
The issue becomes that you can’t dig into things that you didn’t account for in those dashboards after the fact. Commonly we’ll work with customers that are experiencing issues they’re not even aware of because they’re not centralizing those datasets. Plus, you still have huge amounts of data to sift through to locate issues – and that’s after it’s all been ingested and indexed.
How Edge Delta Makes it Easier to Uncover Insights from Logs
A more meaningful approach would be to take a page from APM’s playbook and make it easier to locate issues, and then when those issues occur, proactively gather the data needed to investigate those issues. After all, the problem isn’t that logs aren’t useful – it’s just that you don’t know what is useful until after the fact.
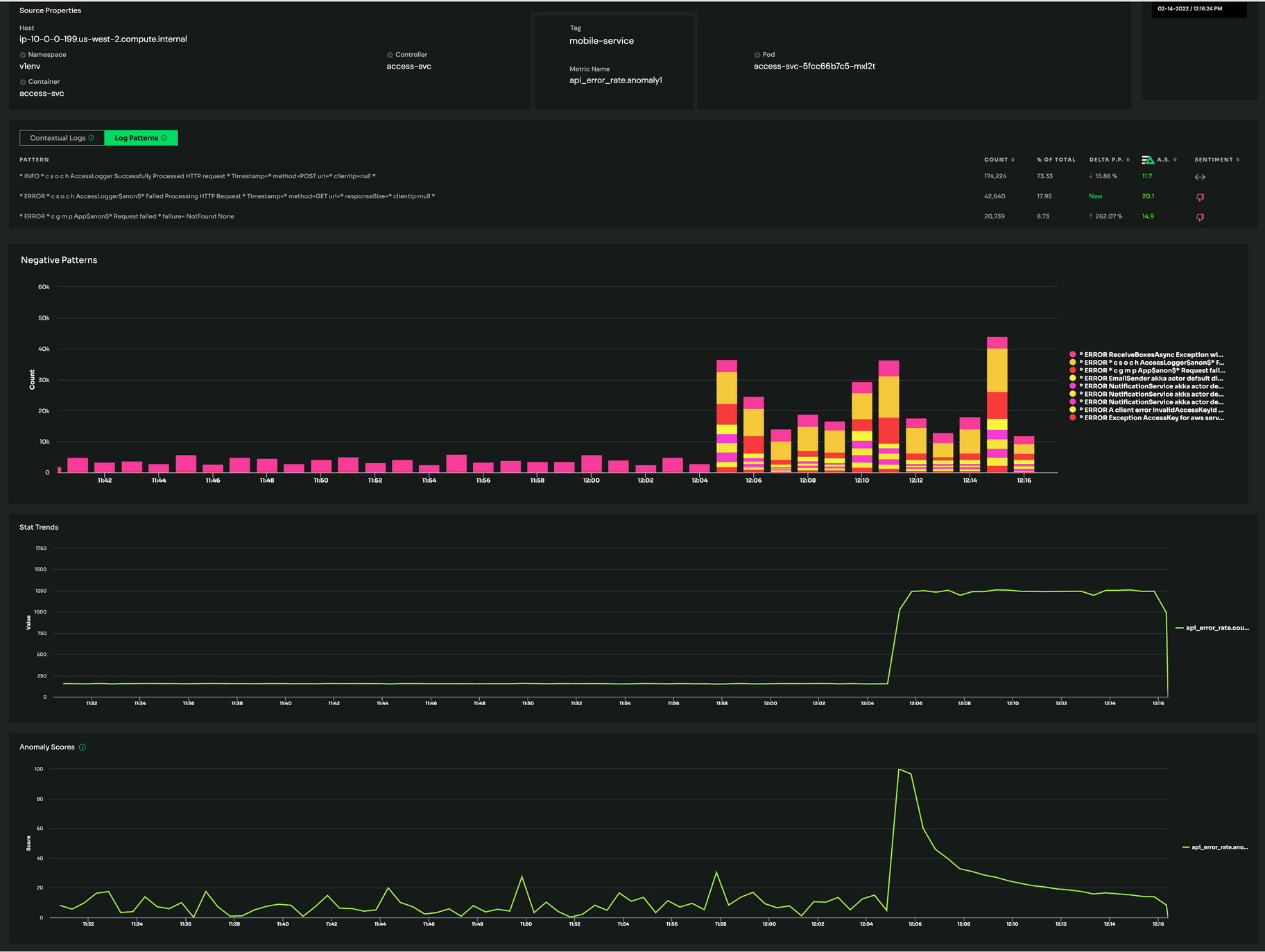
Our approach at Edge Delta is just that. We look at every log message to form and baseline patterns, extract the behavior of those patterns over time, and deliver insights in the form of easy to consume time-series data. That time-series data makes it much easier to identify anomalies via machine learning and visualize them in your favorite observability tools.
Once Edge Delta detects an anomaly, it forwards the actual log messages before, during, and after the irregularity occurs – including messages that are so often discarded like DEBUG messages. These raw logs allow you to drill down to the root cause. Now the log data you need is at your fingertips before you even knew you needed it – and all without paying the logging tax.
It is clear to anyone that has to pay for a log management tool that the time has come for change. It should be possible to get the real value out of your log data without making difficult tradeoffs between costs and your customer experience and to get that value when you need it – in real-time. And it turns out that the change we need is at the edge.



