


Bad data is a multimillion-dollar problem, causing an average of $12.9 million in damages to an impacted company. Others face more than monetary losses, such as Uber. The company was already dealing with a reputation problem which was exacerbated by inaccurate data that overestimated driver commissions and payments totaling $45 million. As a data-driven organization seeking success, you should not wait for this to happen to you.
Besides implementing an effective data quality management program, such as data observability and monitoring tools, you must learn all about bad data, its signs, impacts, and ways to deal with it. Discovering them helps you make informed decisions and maintain a quality data ecosystem when faced with bad data.
Key Takeaways
Bad data is data that does not fit its intended purpose and is inaccurate, inconsistent, and irrelevant.
Signs of bad data could manifest as soon as it appears in the database, but some remain unnoticed for a long time. That’s why it’s vital to learn the warning signs of bad data and spot them immediately.
Data-driven organizations lose nearly $13 million from the impacts of bad data and exert more manpower than needed to repair it.
Acknowledging you have bad data is the first step in dealing with it, and ensuring it never reappears is the last step. Every step in dealing with bad data is best taken with a data management tool.
Expert Definition of What Is Bad Data (And Everything You Need to Know About It)
Bad data is a general term for data that does not serve its intended purpose for operations. It does not meet the expectations for data quality based on a metric set by decision-makers.
When bad data enters the ecosystem, some will remain unnoticed for a long time, influencing decisions, impacting plans, and overall analytics, in contrast with Thomas ‘Data Doc’ Redman’s definition of high-quality data.

How Different Types of Bad Data Occur – An Extensive Guide
There are various classifications of bad data, depending on its intended use case and quality expectations. Recognizing what type of bad data you’re dealing with and how it occurred is crucial to its resolution.
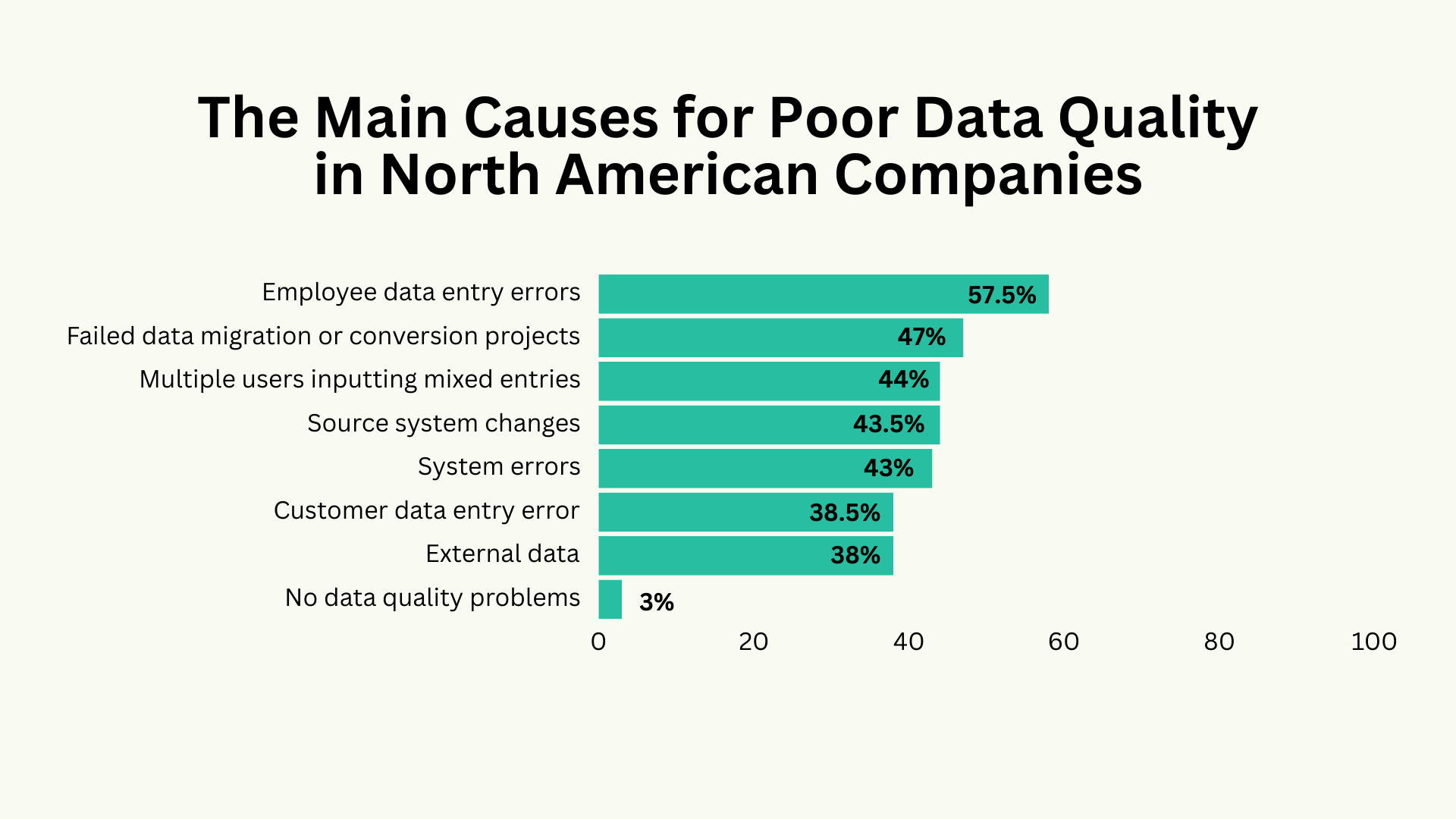
Data Entry Errors Result in Incorrect, Incomplete, and Duplicate Data
IBM describes a data entry error as a dialog that occurs when you enter an invalid value or do not enter a value for a required field.
Data entry errors could cause various types of bad data in your ecosystem, mainly:
- Incorrect data is inaccurate information in the database. One incorrect character in a code or one minor detail in information makes inaccurate data.
- Incomplete data refers to data with missing values or inadequate attributes.
- Duplicate data describes multiple unnecessary copies of information in a single database.
Human error is the most common cause of data entry mistakes. Experts estimate the manual data entry error rate is between 1% and 4%. Although that might seem insignificant, that rate could already cause colossal damage to your database.
When it happens IRL:
In 2018, a manual data entry error incident, often called the Samsung Securities “Fat Finger” blunder, shook the technology industry. Someone from the firm paid the employees using the wrong unit. Supposedly, they paid employees 1,000 won (KRW) per dividend share. They gave them 1,000 Samsung Securities shares instead.
That day, Samsung Securities gave out 2.83 billion shares worth 112.6 billion won (KRW) or $85 million, 30 times bigger than the company’s market value.
What started as a manual data entry error led to the following events:
- 16 employees sold 5 million shares worth $187 million in 30 minutes.
- Loss of trust from major investors and customers.
- Samsung Securities was barred from taking new clients for 6 months.
- CEO Koo Sung-hoon resigned.
Data Decay Leads to Outdated and Irrelevant Data
Data is dynamic. It changes with every acquisition, employee decision, customer preference, industry trends, etc. Due to the constant changes in data, companies must update their database to make timely and relevant decisions.
Data decay or degradation occurs when the database is not updated on time. It creates outdated or expired data, which describes data that no longer serves its purpose.
When outdated, data becomes irrelevant and has no practical value in the database as it does not contribute to company decisions and processes. Outdated and irrelevant data are a liability.
When it happens IRL:
Companies are constantly pressured to make accurate decisions based on present data, which may change at any time. The problem is some systems have long query run times.
Based on a survey by Exasol, 75% of its respondents wait between 2 and 24 hours for a query to return, while only 15% have query times of 15 to 60 minutes. These are considered long query return times, making 56% of the respondents believe they can’t make proper decisions based on their company’s data timeliness.
Unsuccessful Data Migration Causes Inconsistent and Non-compliant Data
Data Migration involves extracting and transferring data from one computer to another. It’s a common activity in the IT industry to replace servers or storage devices.
It might sound simple on paper, but it’s a complex process. Workload type, data volume, and speed to completion are among the many things to consider before data migration. Improper preparation could affect its outcome.
Data migration could fail and lead to bad data in many ways. An Experian study discovered only 70% of data migration projects were successful in 2017. Those who failed their data migration projects might have given out to the following risks:
- Missing data is the data lost during the migration process due to hardware and software failures, format incompatibilities, new validation settings, data corruption, etc.
- Inconsistent data could appear after data migration if the old and new systems have database differences and store values differently.
- Non-compliant data is data that does not follow policies and government permissions due to exposure of sensitive company information and personal data.
When it happens IRL:
After five years of investigation, TSB, a British bank, was fined over £48 million due to a failed IT migration. In 2018, TSB moved its customers to a new IT system but locked millions of people out of their accounts in the process.
The technical failures that this incident has seen were due to poor data migration preparation.
Flawed Data Integration Causes Fragmented Data Dependencies
Data Integration merges data from disparate sources into a new, unified system. Companies perform data integration to enable efficient data management, analysis, access, and insights.
Like data migration, data integration is a complex process. A 2016 study shows large data integration projects have a 50% higher failure rate than small projects. More recent research revealed that successful data integration projects are rare, as almost 80% fail and lead to:
- Fragmented data dependencies refer to broken program statements that must be sequential. Data dependency creates an instruction dependent on the result of earlier instruction. When fragmented, both instructions become obsolete.
A data integration failure can also create data inconsistencies and misaligned requirements. Data loss is also imminent when data integration fails, causing significant setbacks for affected companies.
When it happens IRL:
LMN Software Solutions failed a large-scale enterprise software implementation. Without proper project integration management, the company struggled to maintain data consistency, keep data dependencies together, and align requirements.
The process went wrong and resulted in an unreliable software system, which created disorder in the company’s operations and left customers unsatisfied.
Limited Representation Option Creates Ambiguous Data
Although data is arbitrary, it could be limited depending on its representation. Data is represented in a computer system through a fixed, finite number of bytes.
Software must use a coding scheme to create clever and working representations, making room for large data sets. Otherwise, ambiguous data may appear, or two separate data may be represented similarly under one computer system.
When it happens IRL:
An example of ambiguous data is when information about two people, whose names are John Miller, enter the same database. In this system, names are represented in the code Lastname;Firstname, appearing both as Miller;John in the database.
It’s a terrible example of a representation, but it’s a simple way to understand how ambiguous data appears. If only the code added numerical or other values, the system could distinguish both John Miller’s.
Other Types of Bad Data To Watch Out For
More types of bad data could affect a company’s backbone and alter its overall functions.
- Poorly Formatted Data refers to a dataset with constant errors such as typos, misspellings, spelling variations, or contradictory abbreviations and representations.
- Hoarded Data describes collecting and storing large amounts of information in a database. More often than not, hoarded data is unnecessary and not useful. Regardless, it remains in the database due to fears of losing valuable data, archiving for future use, or bad data storage habits. Hoarded data is often poorly organized and takes up too much storage.
- Biased Data refers to overrepresented data in the ecosystem, causing skewed outcomes, low data accuracy, and prejudice. Data bias in ML and AI often results in discrimination towards a specific group.
{{newsletter}}
When it happens IRL:
Amazon used to recruit employees by running their CVs through experimental machine learning software in 2014. The AI analyzed historical patterns from the candidates’ CVs.
It seemed effective initially, but after a year, Amazon realized the AI developed a gender preference, handing developer and other technical jobs to men while not considering women at all.
AI learned, from the 10-year data available, that most resumes submitted to Amazon were from men, concluding that it’s a male-dominated industry. That’s why it started scrapping resumes that included the word “woman” and its variation. Amazon scrapped the AI tool afterward.
The Key Warning Signs of Bad Data
Affected companies continue their operations with bad data under their nose for a long time. Some companies like Samsung discovered the “fat finger” blunder and fixed it within 37 minutes. Other companies like Amazon found out about its AI recruiting tool bias after a year.
Whether it takes 30 minutes or a year to discover bad data, companies suffer massive setbacks. Learning the warning signs of bad data is crucial to avoid damage from poor data quality.
Noticing There’s Too Much Time Spent On Manual Tasks
Bad data on your database will have you running around doing manual tasks. Missing data will have you looking for information to fill the missing gaps, while wrong data needs manual correction.
If your company hoards data, someone must dig through so much unnecessary information, likely unorganized, to look for an important dataset or information.
Did You Know?
A 2022 report showed that 51% of workers worldwide spend at least 2 hours on manual, repetitive tasks daily. That time spent on such unnecessary work could increase with bad data.
Automation tools like AI are set out to help reduce time spent on manual tasks. However, when dealing with data, even tools won’t cut the need for manual tasks among your employees.
Receiving Delayed and Unactionable Insights
Companies must have high-quality data to come up with actionable insights, which are data that draw the proper response and outcome. Actionable insights must also be aligned with the organization’s initial plans and goals.
When irrelevant, inconsistent, and incomplete data is in your company’s database, you’ll receive unactionable insights instead. Outdated data could also delay any conclusions you’re supposed to draw from your database, affecting your company’s pace.
Having Difficulties With Data Analysis and Processing
You’ll notice complications in conducting data analysis when you have poor-quality data. Your database is riddled with poorly formatted, inconsistent, incorrect, duplicate data, etc.
Starting to Question Data Credibility
Often, the first sign of bad data is its ability to spark a debate among your team. If someone questions the credibility of the data because it differs from their expectations or department records, it’s time to double-check both databases.
Did You Know?
A survey shows less than 50% of executives consider their organization’s data reliability “very good.” This survey result is bad news since credible data is essential for decision-makers.
Lacking Confidence in Data, Leading to Missed Opportunities
Bad data could make you think more than twice; the more you do, the more you lose confidence in it. Decision-makers who lack confidence in their data will hesitate to use it, turning to the old ways of making decisions based on informed guesses or even gut feelings.
Catching Organizational Inconsistencies
Bad data creates a divide in your organization. Ask two members of the team the same question about data. You’ll notice the inconsistency when they have slightly or entirely different answers. When data is missing or irregular, it opens up more than one interpretation, creating organizational inconsistencies.
Frequent Customer Complaints
With all the delays, indecisiveness, and pressure from bad data, everything will reflect on the company’s performance, affecting customer interactions.
Customers will make the same complaints due to the bad data until your team discovers its source. The longer they wait for it to get resolved, the more likely your company will develop poor customer relationships.
Note:
Customers can also be the source of bad data. Wrong information from them, or even just a simple typo on a document, could lead to a misunderstanding. Some customers leave the right information in the wrong field. It’s one of the most common data quality issues that could affect your organization’s customer satisfaction.
When this happens, your organization is responsible for communicating and fixing it with the customer.
Understanding the Critical Impacts of Poor Data
No company is virtually immune from bad data and its consequences. Its impacts depend on the type of poor data, how it occurred, and how long it took the company to discover.
Bad Data Leads to Loss of Income and Time
The number one concern when dealing with bad data is how much it will cost, referring to the monetary worth of the damages, how much it takes to fix it, and the amount of effort it requires to deal with it.
How Much Do Companies Lose To Bad Data?
According to Gartner, organizations lose around $13 million yearly from poor data quality. This cost includes the following impacts:
- Revenue loss
- Increased operational costs
- Compliance violations
- Reputation damage
Other projects tied to the bad data may also go to waste. For instance, marketing campaigns for certain products were launched and seemed to be going successfully. When double-checking the data at the end of the campaign, the real numbers revealed to have missed conversions.
With that example, not only did you lose money from the campaign, but you also failed to generate more income from your target customers.
Reduced Work Efficiency and Morale Are Common When Dealing with Poor Data
Bad data is never timely and will slow down your company’s operations, from data consumption to decision-making. Poor data quality reduces efficiency while costing more time and energy, leading to lower work morale.
How Much Time Do Data Scientists Spend on Cleaning and Organizing Data?
One of the many ways organizations ensure high-quality data is by cleaning and organizing their data. Data scientists spend the most time on this task they call “Janitor Work,” using 60% of their time tending and sorting out data, as revealed by a 2023 NY Times survey.
They spend their remaining time on data preparation steps, such as:
- 19% on collecting datasets.
- 9% on mining data for data pattern drawing.
- 3% in training datasets.
- 4% on refining algorithms on the database.
- 5% on other tasks.
Data scientists cannot perform a data analysis unless every data in the database is cleaned up. Janitor Work takes up too much time. If bad data is present, it can eat more of the data scientist’s work and leave barely any time for other steps, which are just as crucial.
Poor Data Quality Leads to Missed Opportunities
Bad data could cost your company many opportunities. It could tarnish business-customer relationships due to inefficient customer service communications that leave customers unsatisfied.
You could also lose customer trust once they learn your company runs on bad data.
How Many Companies Lose Opportunities From Bad Data?
According to a 2019 census, 1 out of 5 companies have experienced losing a customer due to incomplete or inaccurate information. Meanwhile, 15% of previous customers didn’t sign a new contract for the same reason.
Inaccurate Data Analysis Is Inevitable With Bad Data
Data analysis, also called predictive analytics, is crucial for data interpretation and decision-making. A company’s data analysis will come off as inaccurate with poor data, which creates the risk of misinterpretation.
You Will Face Fines for Violating Data Privacy Laws
People interact with data daily, which pushed the creation of global data privacy laws and other regulations for data protection worldwide. Some countries allow sectoral coverage, which means data laws per industry differ.
Your company could face fines for violating data privacy laws since bad data differs from its intended representation and use.
ℹ️ ICYMI:
Data has replaced oil as the most valuable resource in the world. The Economist was the first to point it out when it published the controversial article “The world’s most valuable resource is no longer oil, but data” in 2017. It expressed how few people can live without data-generating tech giants like Google and Amazon.
Forbes published a counter-article citing the many ways data could improve the world. Regardless, it all comes down to one thing: that data is the most vital resource today.
Be Ready For Reputational Damage
For some companies, a damaged reputation seems worse than financial setbacks. Reputational damage is more likely to bring long-term effects. It’s more time-consuming to rectify. Plus, integrity and reliability could be challenging to rebuild.
Unlike financial damage, reputational damage could not be measured on a scale. Either your company has a bad reputation due to poor data or a spotless reputation.
Crucial Ways to Deal With Bad Data
Since bad data costs time, money, and even your customer’s trust, you must have a solid plan to handle it. You’ll also need a data management program and tools to prevent poor-quality data from appearing again.
First, Acknowledge the Bad Data, Investigate, and Assess
You can’t correct a bad data situation if you don’t consider it an issue. That’s why the first step to fixing it is to acknowledge it.
Time is of the essence when dealing with bad data. When you sense something is wrong with your data, start your investigation immediately. You must identify what type of bad data you’re dealing with and where you can find it on your database.
Identifying the issue isn’t enough. You must also assess the magnitude of the bad data by evaluating the following:
- Who it affects
- When and where it started
- What are the damages it inflicted
- If it has spread somewhere else
Did You Know?
Companies without proper data management practices will have difficulty identifying and handling bad data. That fact emphasizes the importance of using proper data management tools and practices in a business, especially since 32% of companies worldwide struggle with managing large amounts of data.
You Must Immediately Amend or Update Bad Data
This part is called data cleansing. As soon as you identify your bad data and its magnitude, you must immediately repair what needs to be fixed.
Types of bad data, like duplicates and inconsistencies, must be revised. Poorly formatted data and limited representations must be amended. Any outdated data needs to be updated right away.
✅ Pro Tip:
You must update your data regularly to avoid dealing with the damage of outdated and irrelevant data. In the long run, updating your data will take less time and cost than having always to tend to bad data.
You Have to Clean up After the Bad Data’s Mess
Poor data quality takes a lot of clean-up work, from correcting the bad data to sorting out the damages it imposes. These damages could be anything from the abovementioned impacts involving significant financial and legal setbacks.
Get a Data Observability Tool to Improve Your Data Quality Management Practices
Your efforts of cleaning up after bad data will be in vain if you don’t take the next step: making sure it does not happen again, or when it does, you must minimize the risks next to nothing.
An effective data observability tool can help make that happen. Edge Delta prides itself on its data observability tool, which ensures quality, dependable, consistent, and accurate data. It allows you to upload, store, and search all your data. Its “log everything” feature enables observability at a scale, regardless of your company’s data size.
The current and evolving trend in data observability is using AI to ensure constant monitoring and observability. AI will automatically detect and alert you, through a notification, of anomalies due to bad data. No more rummaging through data sets to find what’s wrong.
✅ Pro Tip:
Your company could also employ a cloud-native monitoring application to collect and analyze logs and metrics. Cloud-native monitoring is a great tool for defense against bad data that causes issues like organizational inconsistencies.
When a data observability tool spots bad data, it will not leave you hanging after alerting you about it. Expect assisted troubleshooting. Tools like Edge Delta will summarize your log data, where the bad data sits, and what you must do.
Overall, a data management tool will help your company maintain proper and quality data management practices, which is crucial for businesses of any size.
Summary of What is Bad Data
Taking care of data quality is essential for all data-driven organizations. Understanding the types of bad data, their common causes, and their impacts is essential in data quality management. That’s how you can properly acknowledge, address, mend, and remove bad data.
You have to keep bad data out of your system using a data observability tool that allows you to monitor and observe data patterns for quality optimization. Ultimately, eliminating bad data ensures enough opportunities to analyze and use high-quality data.
FAQs on What is Bad Data, Signs, and Ways to Deal With It
What is good data vs. bad data?
Good data refers to the data that serves its intended purpose and leads your company to the right decisions. Meanwhile, bad data could affect decision-making by delaying and skewing results, leading to ultimate failure.
What is the meaning of bad data in bad data out?
Bad data in, bad data out is similar to the old saying “garbage in, garbage out,” which refers to the idea that bad data input will always result in a bad data outcome.
How do you know if data is quality?
You can assess data quality through general standards, such as fitness for purpose, accuracy, relevance, consistency, timeliness, and completeness.

