


The software architecture landscape has been experiencing fundamental changes, especially with the shift toward microservices architectures. This change creates not only exciting possibilities, but also various challenges.
One of the fundamental features of this architecture is the seamless discovery and interaction of services. This article explores the crucial factor of service discovery in a microservices architecture.
Read on to understand the relevance of having a bulletproof service discovery strategy in place.
Key Takeaways:
- Service discovery enables services within a microservices architecture to discover and communicate with each other efficiently, serving as a registry to track service instances.
- Service discovery is essential for managing the complexities of communication paths and service endpoints, preventing errors, and ensuring smooth operations.
- There are two main implementations of service discovery—client-side and server-side—each with advantages and disadvantages, impacting factors like load balancing and management complexity.
- Service registration, registry maintenance, service lookup, load balancing, dynamic updates, and health checking are key processes involved in service discovery, crucial for ensuring robust, scalable, and agile microservices infrastructure.
What Do You Mean By Service Discovery?
Service discovery is a technology that enables services within a microservices architecture to discover and talk to each other. It serves as a registry that tracks all the service instances and facilitates communication between services.
Microservices architecture relies on service discovery because communication between services becomes more complicated to manage as the number of services increases. Without service discovery, managing communication paths and service endpoints can become error-prone.
Service Discovery in microservices manages the dynamically changing locations of service instances and their communication. It ensures that actual service requests are routed to instances working at a given time and helps maintain the architecture’s robust and responsive nature.
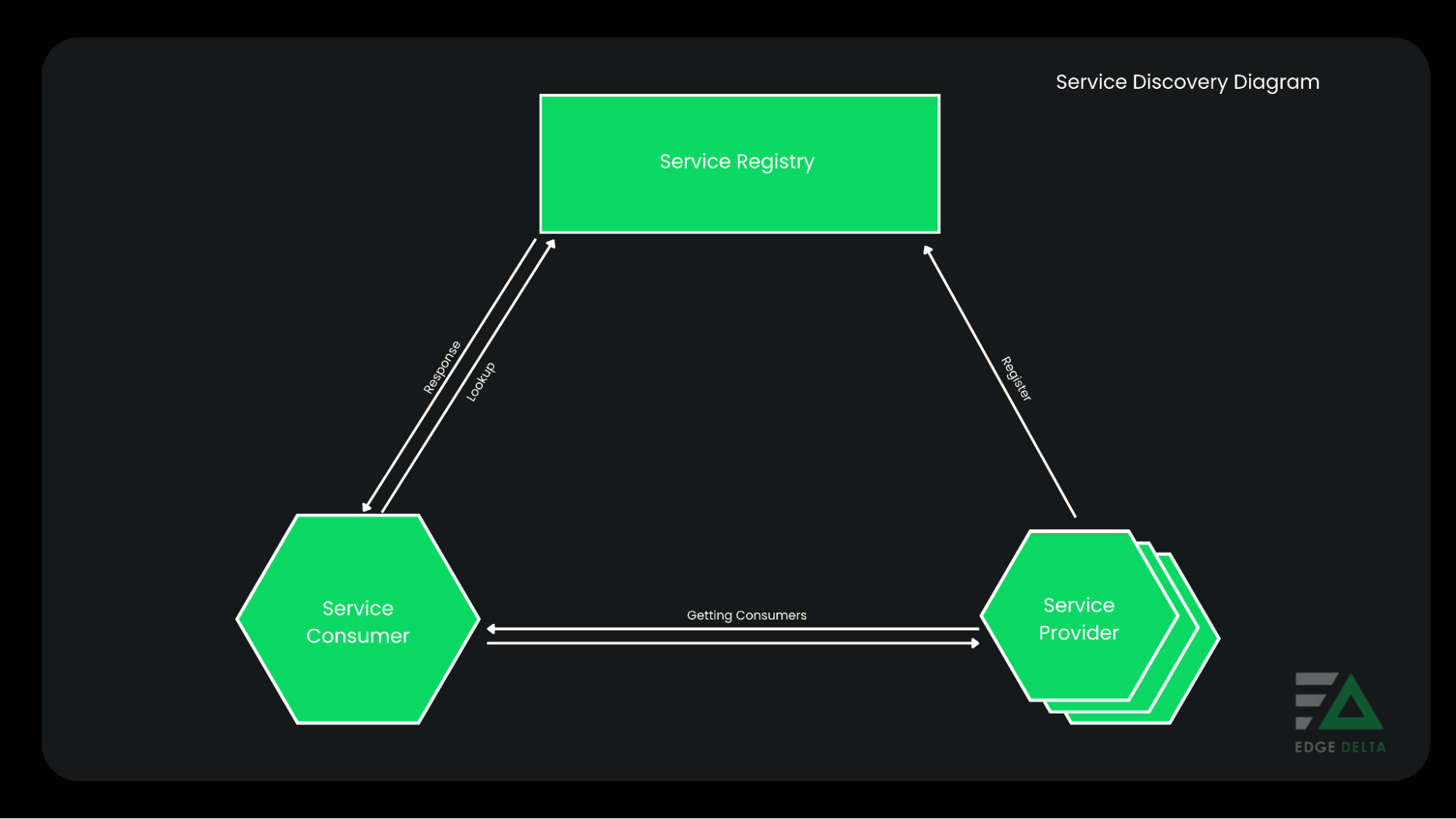
Service Discovery Implementations
There are two main implementations of service discovery: client-side discovery and server-side discovery.
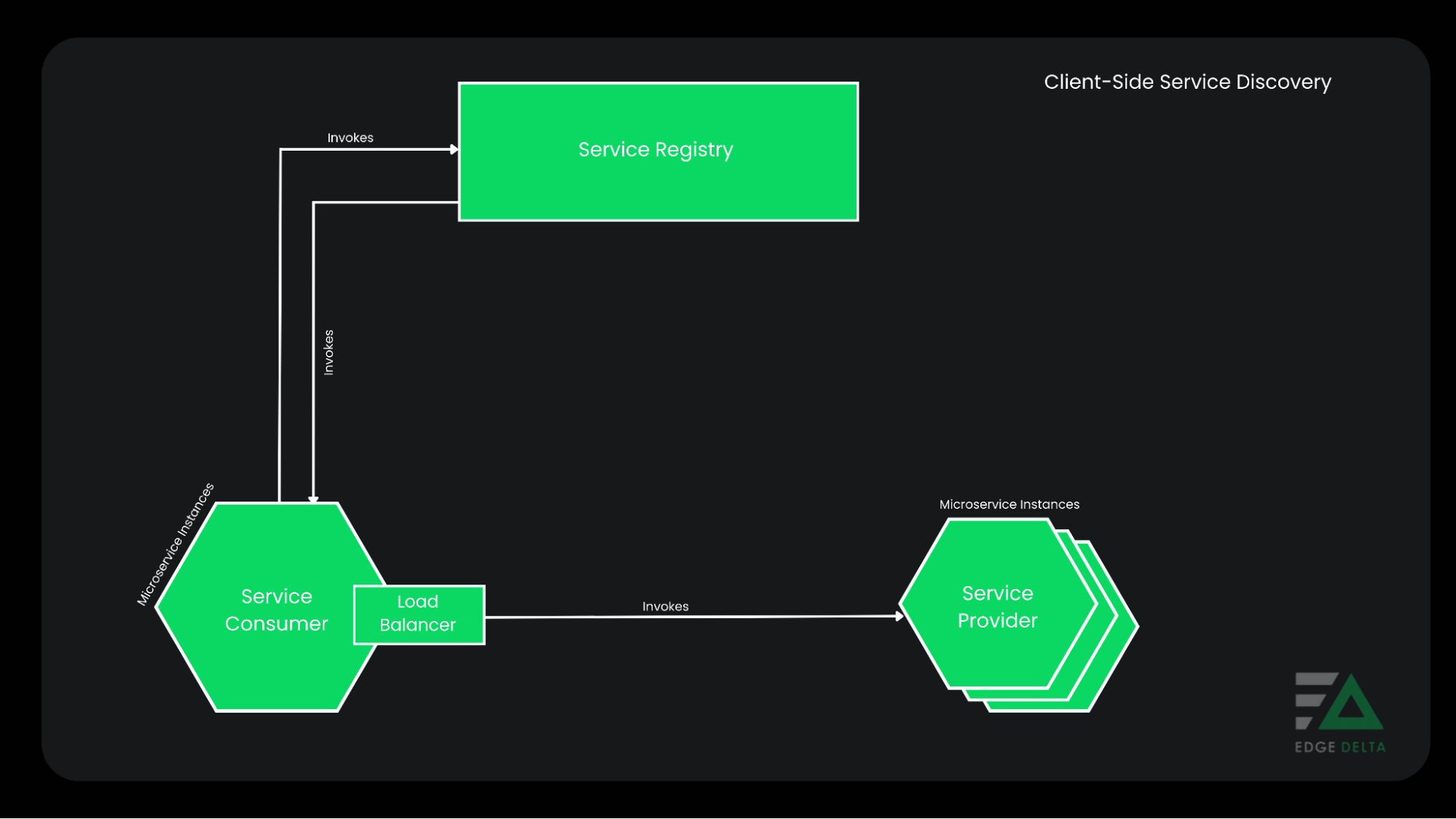
1. Client-side Discovery
The client service is responsible for locating where service instances are available on the network. It distributes load among service instances that are online. In this case, every client will have to possess its service registry, which it will query while in pursuit of discovering services.
Advantages of Client-side Discovery:
- There are no moving parts except the service registry.
- It enables the client be in control of the load-balancing decisions.
- Clients can make informed decisions according to requirements.
- Offers quick turnaround by avoiding extra steps in the middle.
- Load-balancing decisions can be application-specific, such as using hashing.
Disadvantages of Client-Side Service Discovery:
- It makes the application management more complicated.
- Requires client-side discovery logic because it is coupled with the service registry.
- Clients have to make two calls to reach microservice.
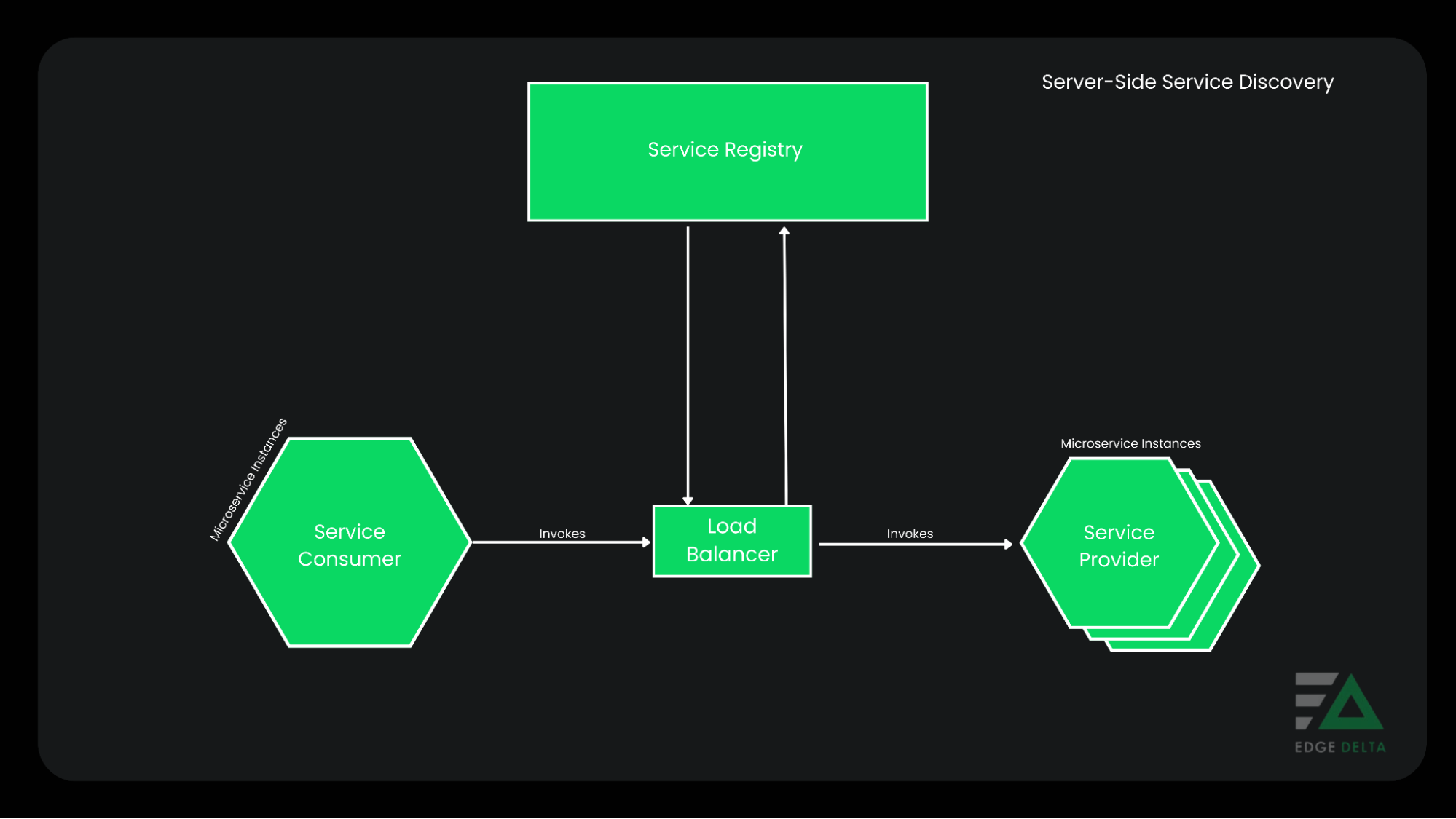
2. Server-side Discovery
Server-side discovery offloads the responsibility for service instance discovery. This process means that the registry doesn’t need to find instances. The service discovery abstracts the location away from the client and allows them to communicate with a known load balancer.
Advantages of the Server-Side Service Discovery
- It helps create an abstract between the server and the client.
- Eliminates the need to implement the discovery logic separately for each language and library.
- Offer for free in some environments.
- Only one call is needed to request services.
Disadvantages of Server-Side Service Discovery
- The user must manage and set up unless the deployment environment provides it.
- The central server requires the implementation of a load-balancing mechanism.
The Service Registry
The service registry is one of service discovery’s most essential building blocks. It contains every available instance’s location, so it must be modified and adequately maintained.
Users can store the network locations as a cache. However, it is essential not to rely on it because the dynamic environment makes the information outdated. The service registry also consists of several servers that re-use the replication protocol for synchronization.
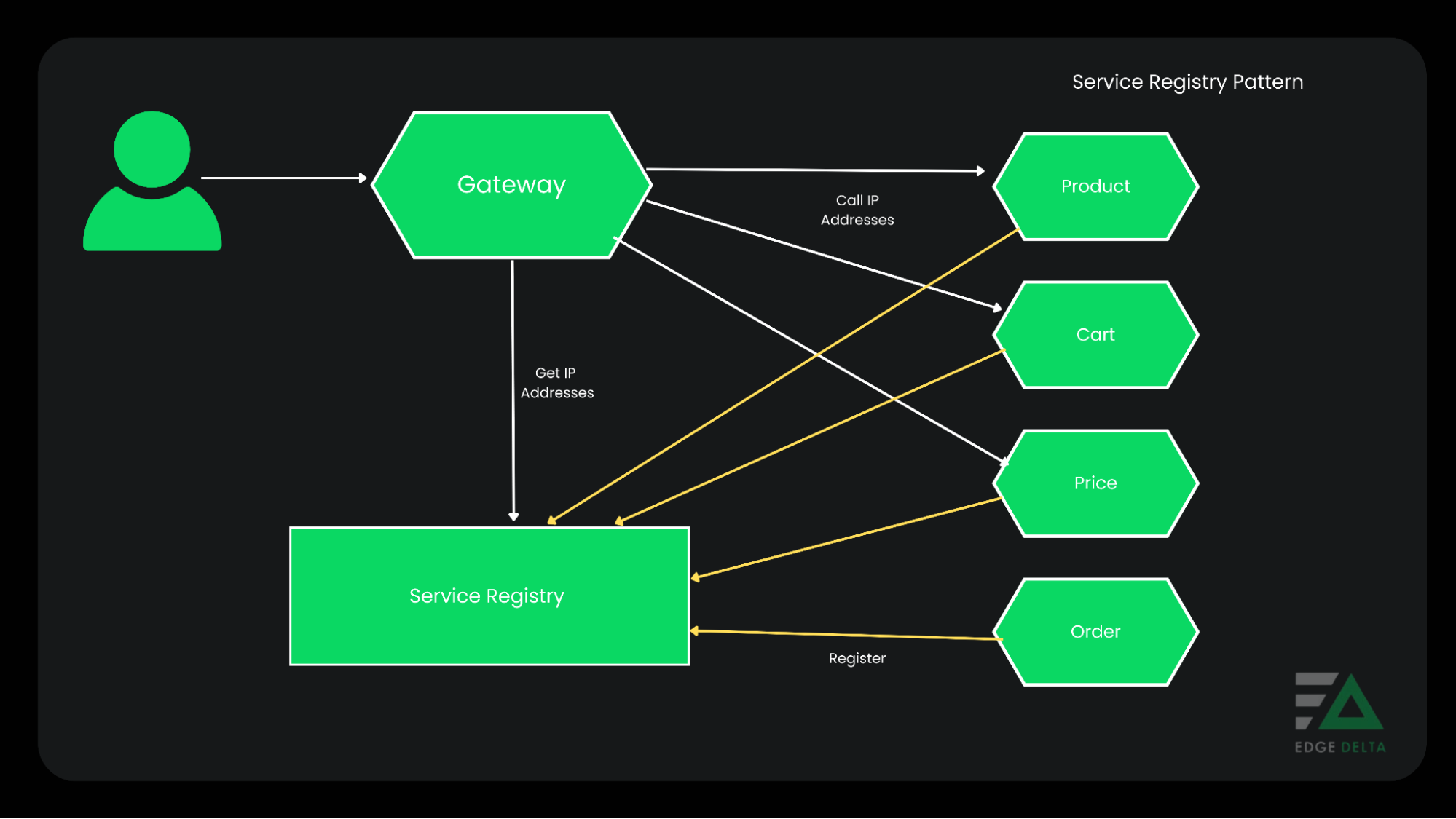
Service Registration Options
In any service discovery, instances must be registered and deregistered in the service registry. There are two ways to do this: self-registration and third-party registration. The names of these strategies are precise expressions of how methodologies are performed.
Self-Registration
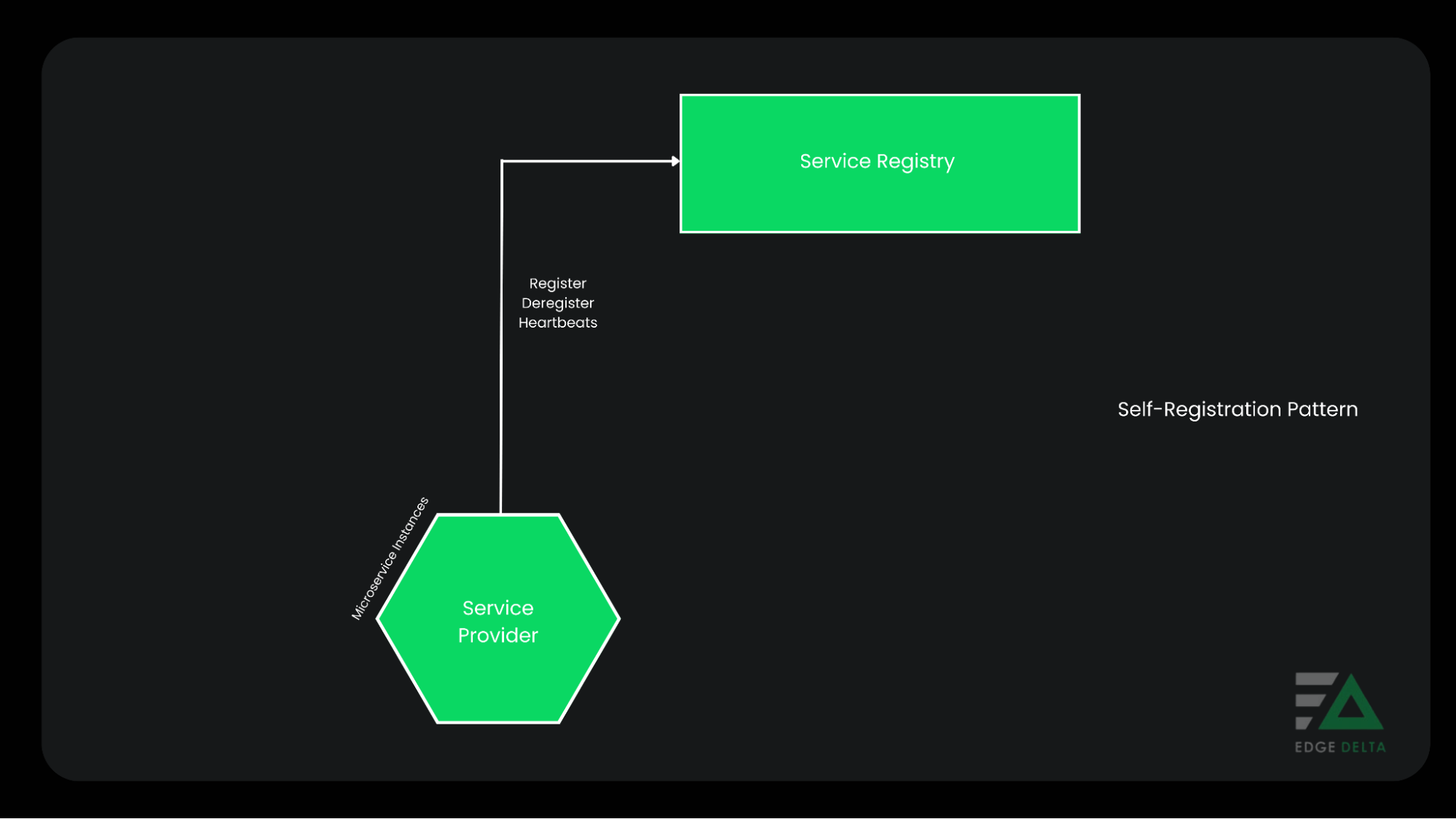
A service instance is responsible for its registration and deregistration from the service registry in this form of registration. It also sends out regular heartbeats so the registration doesn’t expire while it is still used.
Self-registration requires no external components, making the procedure simple and user-friendly. It registers the address in the registry, and once the instance terminates, it deregisters itself immediately.
Third-Party Registration
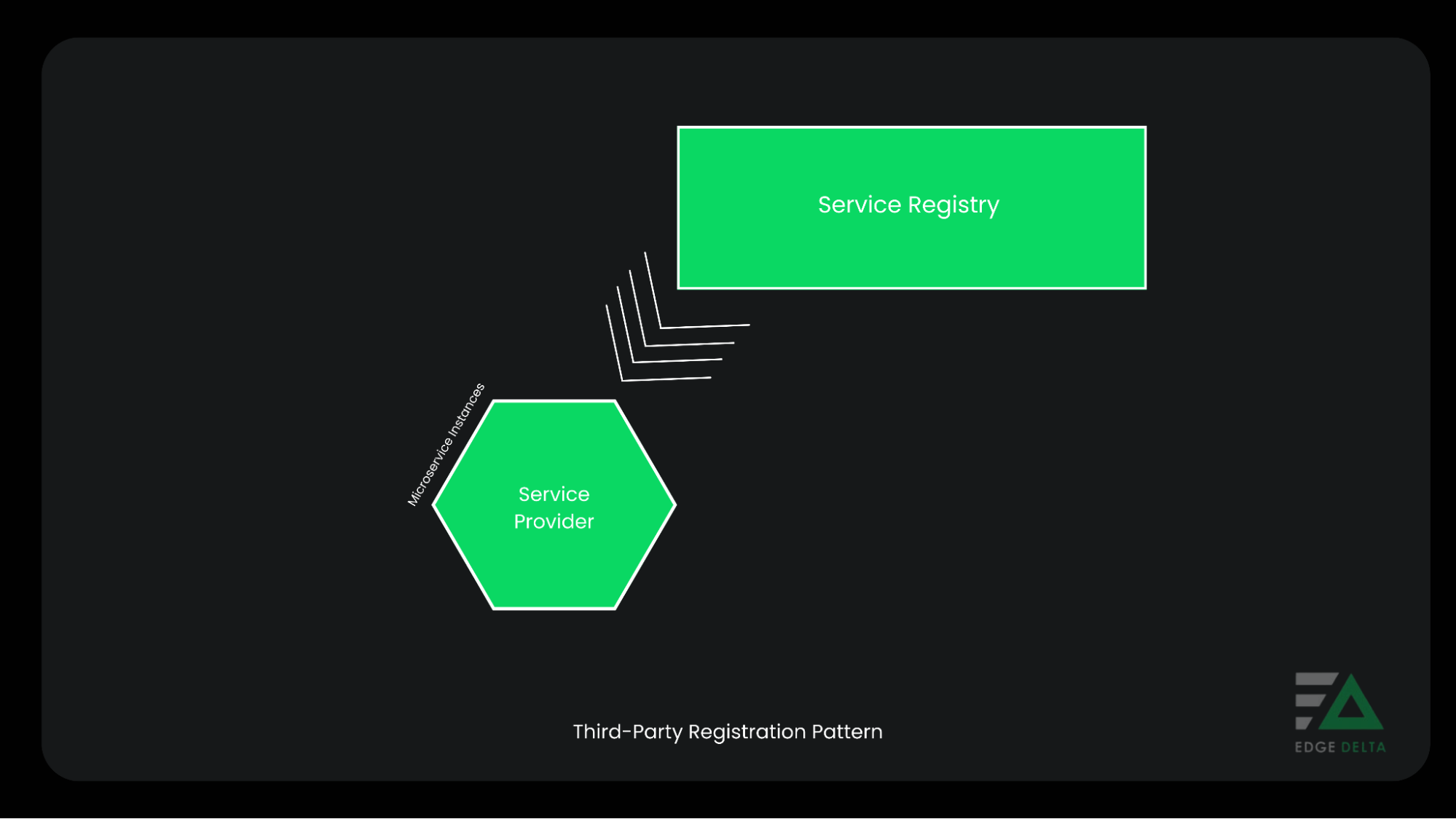
The third-party registration pattern offloads registration duties from service instances to centralized entities. In this pattern, a service registrar handles the registration and deregistration processes.
Whenever the registrar detects a new service instance, it registers it with the service registry and deletes it automatically. A factor that sets the third-party registration pattern apart is its decoupling of services from a service registry. This factor means users won’t need to implement registration logic.
How Service Discovery Works: The Steps Involved
Here’s a step-by-step breakdown of how Service discovery works:
1. Service Registration:
- The moment when a new service process is started, it registers itself in a service registry.
- The registration process includes data such as the service’s network location (IP address, port), name, metadata, and health status.
2. Service Registry:
- The service registry acts like a centralized or distributed database containing information about running services and their locations.
- The service registry acts as a directory where services publish information about the availability, and other services can query this information.
3. Service Lookup:
- Whenever one service needs to communicate with another, it sends a request to the service registry, looking for the location of the particular service.
- This lookup could be done using various methods such as HTTP requests, DNS queries, or specialized protocols.
4. Load Balancing:
- Load balancing helps distribute incoming requests among multiple instances of the same service.
- Load balancers can be utilized with the service registry to provide dynamic routes for traffic to healthy instances.
5. Dynamic Updates:
- Service discovery systems support updates to the registry.
- When components are unavailable (e.g., a crash or maintenance), it deregisters itself from the registry.
6. Health Checking:
- Service discovery systems typically consist of health probes that verify the state of service instances and respond to their health status.
- By default, the registry would remove any sick instance from the list of available services; thus, only healthy instances are seen by clients.
These steps help with service discovery, which enables service interchangeability and communication among the services supporting the distributed system.
Popular Tools and Frameworks For Service Discovery
ETCD
ETCD, developed by CoreOS, is a consistent and distributed key-value store mainly used by databases to maintain critical data and service discovery among distributed systems. ETCD allows services to register together with their endpoints, allowing other services within the system to discover the existing services and communicate with them appropriately.
Kubernetes
Kubernetes is an open-source automation system that enforces the use of an internal DNS system that relies on automatic service registration and discovery. Built-in mechanisms help containers deploy automatically to find and reach each other by DNS names; hence, service discovery within a Kubernetes cluster is straightforward.
Netflix Eureka
Eureka is a service discovery framework and tool fully integrated into Netflix’s microservice architecture. It allows service capabilities like self-registration and helps establish a resilient and scalable system configuration. Eureka is self-healing and seamlessly integrates with load balancers, which assures constant availability and performance in the distributed environment.
Wrapping Up
The role of service discovery in such dynamically changing environments within microservice architectures is hard to overstate. It should be treated as the backbone of inter-service communication, which assures dynamism in a changed environment. Therefore, there is an extreme need for efficient service discovery mechanisms that promise a robust, scalable, and agile infrastructure for microservices.
Frequently Asked Questions About Service Discovery
What is service discovery, and why is it important?
Service discovery is the automatic detection and identification of available computing resources and services within a network. Service discovery simplifies the management of dynamic environments by allowing services to locate and connect dynamically, regardless of changes in network topology or underlying infrastructure.
How does service discovery work in distributed systems?
Service discovery mechanisms typically involve a central registry or decentralized protocols that allow services to register themselves and discover others. In centralized approaches, a service registry maintains a list of available services and their network locations. At the same time, decentralized protocols rely on peer-to-peer communication or broadcast mechanisms to propagate service information across the network.
What are the benefits of using service discovery?
Service discovery offers several benefits for distributed systems, including improved scalability, resilience, and agility. By dynamically locating and connecting services, organizations can scale their infrastructure more efficiently, adapt to changes in demand, and deploy updates without disrupting service availability.

