


Modern delivery pipelines rarely break because of one-off mistakes. Most CI/CD challenges stem from systemic friction inside scalable automation systems that must preserve predictability and trust. The real risks sit at the architectural level, not in individual developer actions.
Degradation usually begins long before an outright failure. Pipeline complexity can outpace the maturity of the delivery process, while performance, security, and governance concerns remain tightly intertwined. Even pipelines that consistently report a “green” status can conceal significant operational costs and hidden inefficiencies.
This article explores the most common CI/CD pipeline challenges that emerge at scale, with a focus on the factors that shape delivery speed, reliability, and organizational trust.
Key Takeaways
• Challenges emerge from the interactions between CI/CD pipeline components, not simply from individual failures or misconfigurations.
• As pipelines scale, coordination costs often rise faster than delivery maturity. Even highly reliable pipelines can contain systemic friction that slows integration.
• Test reliability is essential to signal quality, directly shaping confidence, rerun frequency, and developer decision making.
• Artifact consistency and strong environmental control limit drift and reduce long term operational risk.
What Are the Essential Components of a CI/CD Pipeline?

Each CI/CD pipeline is built from layered systems that manage integration, validation, and delivery. These layers address critical concerns such as performance, security, and governance.
Viewing these components as foundational building blocks clarifies why delivery issues arise. Friction typically emerges within and between these layers, rather than from a single isolated failure.
Source Control and Change Orchestration
Source control is more than a code repository. It serves as the coordination layer that determines:
- when pipelines run
- how frequently they are triggered
- the load they place on the system
Decisions made at this layer ripple through the entire pipeline, shaping execution patterns, resource consumption, and the predictability of delivery outcomes.
Version Control Systems Act as the Authoritative Trigger Source for CI/CD Execution
Branching strategies, merge frequency, and trigger scope define how and when pipelines activate. These elements govern both execution and feedback loops, directly influencing integration flow.
Even when every build succeeds, poorly designed trigger patterns can introduce systemic friction that slows integration and delivery.
| Factor | Impact on Pipeline Behavior |
|---|---|
| Branching model | Influences the number of concurrent triggers and integration points |
| Merge frequency | Determines the cadence of pipeline execution and queue length |
| Trigger scope | Controls which changes initiate builds and testing workloads |
Build and Artifact Creation Layers
Build stages transform source code into deployable artifacts under constraints such as compute capacity, time, and dependency management. The artifacts produced during these stages must be consistent and reproducible to ensure that downstream stages function correctly. Failures in this layer can be costly, often compounding across later stages of the pipeline and increasing long term operational risk.
Below are the stages that rely on building artifacts:
- Testing: Validates changes and detects errors early.
- Promotion: Moves artifacts across environments with traceability.
- Deployment: Releases deliverables to production or staging.
Dependency Resolution and Artifact Creation Dominate CI Execution Time
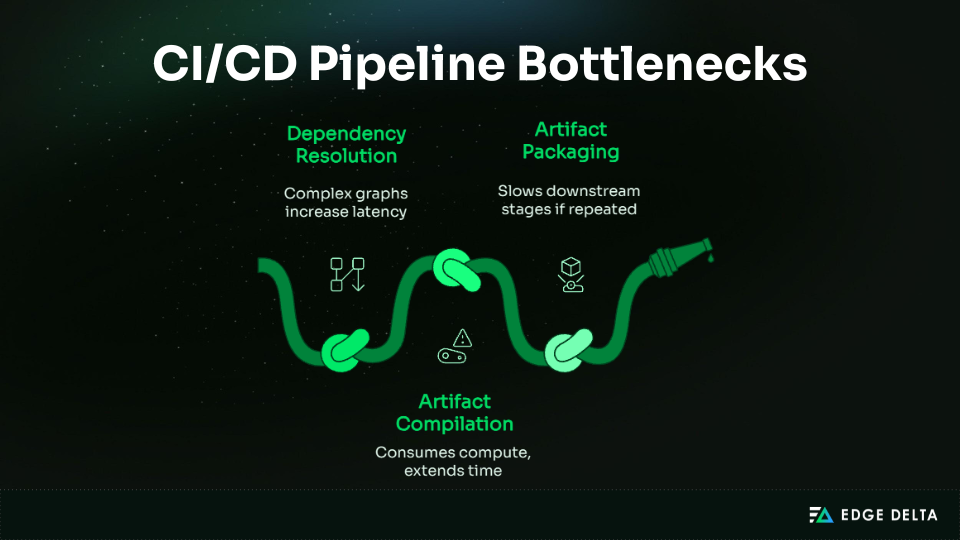
As pipelines grow, dependency resolution and artifact production take longer to complete. This challenge intensifies as build intervals shorten, especially in environments with large and complex dependency graphs.
Key impacts include:
- Longer pipeline duration and delayed feedback
- Higher use of compute resources and contentions
- Risk of inconsistencies when artifacts are rebuilt for multiple environments
Automated Testing and Validation Layers
Automated testing serves as a risk filter, not a correctness guarantee. It works to shrink uncertainty as changes progress stage-by-stage through the pipeline.
Test placement is as important as test coverage; timely feedback affects delivery speed and developer behavior. When validation is slow or late, it causes friction in the pipeline, even if all checks pass.
Unit Tests Provide Faster Feedback and Lower Maintenance Costs than Higher-Level Tests
Test speed shapes the pipeline flow and the developer’s response. Slower tests extend feedback loops and increase queue time, creating drag across teams even when runs are successful.
| Test characteristic | System-level effect |
|---|---|
| Fast feedback | Earlier integration decisions |
| Slow execution | Increased latency and queuing |
| High maintenance | Reduced trust in automation |
As pipelines get longer, this friction gets worse, making validation a delivery problem instead of a safety measure.
Artifact Storage and Promotion Mechanisms
Artifacts establish the boundary between continuous integration and continuous delivery. They capture the exact output of the build process and ensure reproducibility and traceability in subsequent stages.
When this boundary is weak, small inconsistencies can build up as changes progress, even if earlier stages indicate success.
Build-Once, Promote-Many Models Reduce Environment-Induced Variability
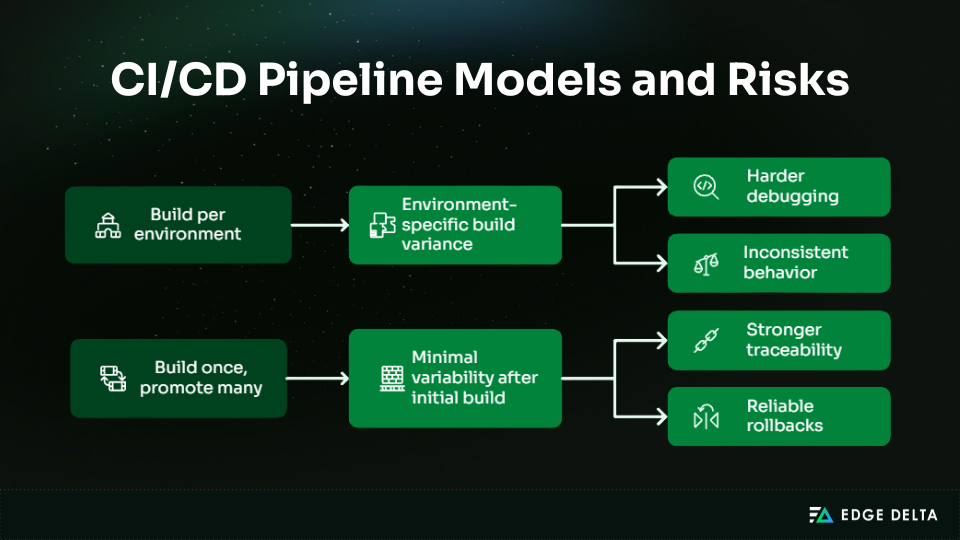
When you rebuild artifacts for each environment, it alters how packages are made and how dependencies are resolved. These differences can make the program run differently, even if the code itself doesn’t change.
In contrast, deploying a single artifact across all environments helps minimize uncertainty with regard to delivery behavior.
Deployment and Release Execution
Deployment is an execution layer defined by infrastructure, not simply the final phase of a pipeline. It is where validated artifacts encounter real world constraints and operational variability.
Weak deployment models can reintroduce risk through unmanaged state changes, manual interventions, or hidden dependencies, even when upstream controls are strong.
This is where deployment risk actually comes from:
| Infrastructure factor | Risk introduced |
|---|---|
| Stateful servers | Configuration drift and irreproducible behavior |
| Manual interventions | Undocumented changes and inconsistent rollbacks |
| Implicit dependencies | Environment-specific failures |
| Long-lived hosts | Risk accumulation over time |
Immutable Deployment Strategies Reduce Configuration Drift over Time
Long-lived environments tend to drift over time due to hotfixes, manual adjustments, and partial updates. This divergence can be reduced through immutable deployment strategies that replace the entire environment rather than modifying it in place.
This is why immutability matters:
- Drift grows even when deployments “succeed.”
- Debugging spans history, not just code changes.
- Rollbacks become state-dependent and unreliable.
What Are the Most Common CI/CD Pipeline Challenges?
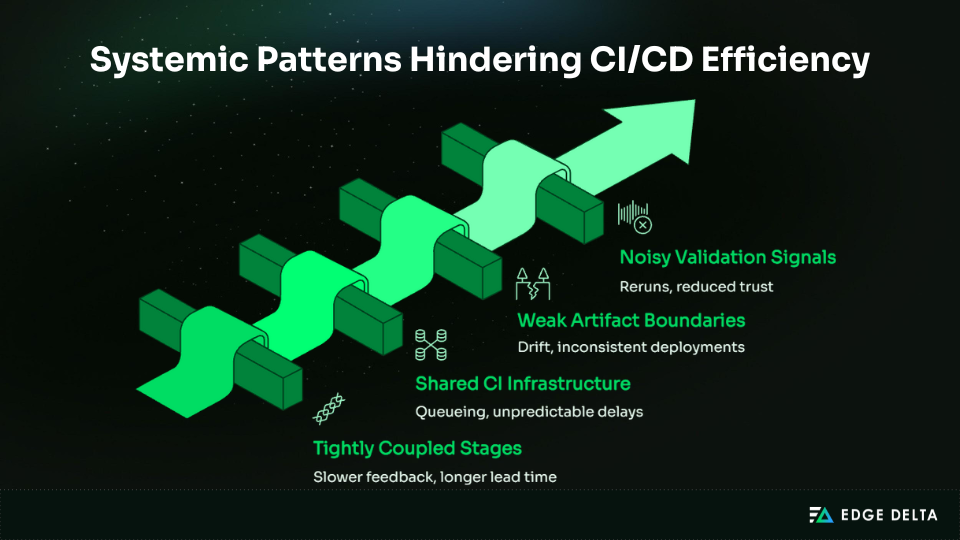
System design creates more CI/CD pain points than isolated build failures or simple misconfigurations. As pipelines scale, interactions between their components introduce challenges such as:
- Friction
- Slow feedback loops
- Poor signal quality
- Operational risks
These issues can persist even when each stage appears to function correctly. In other words, structural complexity can generate systemic problems independent of individual errors.
Pipeline Performance and Feedback Latency
Even a reliable pipeline can stall and become a bottleneck when feedback is delayed. Developers depend on fast validation to move forward with confidence.
When feedback loops slow down, work accumulates, integration decisions are deferred, and overall delivery velocity declines.
Long-Running Pipelines Increase Lead Time for Changes
Long-running pipelines also make developers wait to merge their code or deploy it, leading to inefficient operations. The impact compounds in environments with multiple teams and services, where delays ripple outward and undermine predictability across the delivery process.
| Pipeline Duration | System Impact |
|---|---|
| Fast (<10 min) | Immediate validation, high confidence |
| Moderate (10–30 min) | Delayed integration, minor batching |
| Long (>30 min) | Increased risk, postponed merges, slower delivery |
Test Reliability and Signal Dilution
Unreliable tests are primarily a signal quality problem, not simply a flaw in tooling or code. They reduce the clarity of feedback on changes and make it harder to determine whether those changes are safe to release.
Issues often emerge from interactions within the system, such as intermittent failures caused by shared dependencies, common environments, or timing conditions.
Over time, even if overall outcomes appear positive, degraded signal quality creates friction and gradually erodes trust in automation.
Flaky Tests Are a Leading Contributor to Repeated CI Reruns
Flaky tests affect CI/CD pipelines in multiple ways:
- Challenge: Inconsistent test results obscure the safety of changes.
- Impact: Pipelines rerun unnecessarily, increasing lead time and creating bottlenecks.
- Effect: Teams resort to manual checks or temporary workarounds, adding operational friction and reducing delivery predictability.
Environment and Configuration Drift
Configuration drift occurs when environment settings gradually diverge over time as small differences accumulate. Subtle changes such as updated dependencies, manual adjustments, or infrastructure variations all contribute to this slow shift.
These discrepancies introduce instability into the system. Artifacts that pass validation in one environment may behave differently in another, even when the pipeline reports success.
Configuration Drift Increases Deployment Risk over Time
As environments gradually diverge, delivery becomes more complex and less predictable. What once behaved consistently can begin to vary across stages, increasing operational uncertainty.
- Challenge: Divergent environments make deployments less predictable.
- Impact: Failures become harder to diagnose, increasing debugging and integration time.
- Effect: Teams implement manual interventions or temporary fixes, adding friction and slowing delivery.
Why Do CI/CD Challenges Persist as Pipelines Scale?
CI/CD challenges become more pronounced in mature systems as scale introduces new forms of complexity. As pipelines expand to support more services, interdependent components, and multiple teams, shared infrastructure and resource contention create bottlenecks and delays.
Stable processes alone do not eliminate friction. These challenges persist because they stem from the interaction between architectural design and organizational structure as pipelines grow.
Pipeline Complexity Grows Faster than Delivery Maturity
As systems scale, pipeline complexity grows with the number of services, teams, and dependencies, not simply because of tooling.
Each additional element increases coordination demands that process maturity alone cannot absorb. Pipelines must support more integration paths, shared validation stages, and interdependent changes, allowing structural complexity to outpace delivery capacity.
Key drivers of this complexity include:
- More services: Larger integration and validation scope
- More teams: Increased coordination and shared pipeline usage
- Deeper dependencies: Wider impact from small changes
Pipeline Complexity Increases Faster than Delivery Throughput as Systems Scale
As pipelines grow more complex, a greater share of time is spent on coordination rather than execution. Feedback loops lengthen, shared stages become bottlenecks, and overall throughput improves only marginally even when individual stages remain stable.
As coordination demands rise, even reliable pipelines struggle to deliver changes quickly and predictably.
Shared Infrastructure and Resource Contention
Shared CI infrastructure introduces hidden coupling between pipelines. Pooled execution capacity links pipeline performance to overall system demand rather than to the specific change being validated. As teams and services expand, this shared model introduces persistent unpredictability that can affect even well designed pipelines.
| System condition | Delivery effect |
|---|---|
| Increased parallel pipelines | Higher and variable queue times |
| Shared execution capacity | Unpredictable feedback latency |
| Uneven workload distribution | Inconsistent lead time |
Shared CI Infrastructure Increases Queue Time Under Parallel Workloads
As parallel workloads increase, pipeline queue times grow longer. Fluctuating wait times and slower feedback extend overall lead time for changes. These unpredictable delays erode trust in automation and amplify delivery friction.
How Do Architectural Solutions Address CI/CD Pipeline Challenges?
Architectural solutions help to solve the challenges of CI/CD by changing the way pipeline design is approached. Design patterns for CI/CD, such as separation of concerns and execution patterns, help to minimize the friction associated with pipelines as they scale.
When viewed as systems of intentions rather than ad hoc automation, pipeline systems can address complexity, preserve feedback quality, and improve delivery predictability without reliance on tooling or procedural workarounds.
Designing for Fast, Layered Feedback
Distinguishing between fast and slow validation reduces cost without sacrificing confidence. Fast validation provides immediate or near real time verification, keeping delays short and enabling rapid iteration.
Key aspects include:
- Immediate feedback: Unit tests detect small issues quickly
- Deferred checks: Integration and end-to-end tests validate broader interactions without blocking development
- Layered feedback: Early detection prevents bottlenecks and supports higher throughput
Tiered Testing Strategies Improve Feedback Speed While Preserving Coverage
Organizing tests into tiers balances speed with coverage and risk. The faster tiers are devoted to quick, high-frequency checks of details, while the slower tiers validate the interactions between elements and the system’s behavior as a whole.
This helps to avoid hotspots, protects confidence, and ensures scalability for large codebases or sets of interacting services.
| Test tier | Purpose | Feedback time |
|---|---|---|
| Unit | Validate individual components | Seconds to minutes |
| Integration | Verify component interactions | Minutes |
| End-to-end | Confirm system behavior | Longer, non-blocking |
Standardizing Artifact Promotion and Deployment Paths
Standardizing artifact promotion and deployment reduces variability and uncertainty. A consistent promotion model ensures that the same validated artifact moves from development to staging to production, eliminating environment specific discrepancies.
This approach strengthens reproducibility, simplifies debugging, and avoids hidden costs caused by repeated rebuilds or environmental drift.
Artifact Promotion Reduces Variability Across Environments
A clear promotion strategy establishes a single trusted source for all deployable artifacts. Key advantages include:
- Consistency: The same artifact is deployed across all environments.
- Traceability: Changes and versions are easily tracked and audited.
- Predictable behavior: Reduced environmental variability lowers the chance of unexpected failures.
By providing standardized promotion and deployment, confidence is maintained in the results generated through pipelines.
Treating CI/CD Pipelines as Production Systems
CI/CD pipelines must be treated as critical infrastructure components with the same operational expectations as intelligent, context-aware pipelines for monitoring and analysis that catch issues before they affect production workflows.
When a pipeline is slow or unreliable, delivery velocity, trust, and overall reliability suffer immediately. Treating CI/CD as a production system requires resilience, observability, and predictability, even under heavy load or continued growth.
Industry Guidance Recommends Managing CI Systems with Production-Level Reliability Expectations

Production-level reliability demands a practice that fosters trust and minimizes friction.
- Monitoring: Continuously track pipeline performance and failures to detect issues early
- Redundancy: Utilize the idle capacity during peak days when the demand is relatively higher
- Incident response: Embed on-call and escalation procedures similar to those used in runtime systems
Why CI/CD Pipeline Design Directly Impacts Delivery Outcomes
The design of a CI/CD pipeline directly shapes delivery efficiency. It influences how work gets done, how teams collaborate, and how risk is managed. Core design decisions affect release planning, governance, and day to day team behavior.
Consistent, well structured pipelines reinforce disciplined delivery. Fragile ones push teams toward workarounds and informal processes. Delivery outcomes depend not only on pipeline speed, but also on how teams adapt to and operate within the system.
Impact on Delivery Velocity and Predictability
In scaled systems, predictability is much more important than raw speed. Teams can go fast collectively, even if individual runs are not optimized for high throughput.
For example, volatile pipelines make the development plan less clear, raise coordination costs, and force teams to employ reactive delivery methods.
Stable Pipelines Correlate with Improved Deployment Frequency and Lower Change Failure Rates
Stable pipelines improve delivery by reducing variability in execution, feedback, and failure handling. When the pipeline operates consistently, teams spend less time buffering against uncertainty and less effort on coordination overhead.
Key stability characteristics and their effects include:
| Pipeline characteristic | Delivery outcome |
|---|---|
| Consistent execution time | Reliable release planning |
| Deterministic feedback | Fewer last-minute fixes |
| Controlled failure modes | Lower rollback frequency |
These characteristics make it easier to deploy smaller changes more frequently. Velocity becomes steady instead of random, which improves both throughput and reliability.
Impact on Developer Trust and Behavior
Pipeline friction shapes developer behavior over time. Trust erodes when automation produces noisy or unreliable signals, even if failures are infrequent.
The more significantly developer behavior shifts in response to pipeline instability, the greater the gains from reducing friction and restoring confidence in the system.
Low-Confidence Automation Increases Manual Bypass Behavior
When pipelines are slow or unreliable, developers stop trusting their signals. Behavior shifts from reducing risk to minimizing friction.
Common responses include:
- Bypassing or repeatedly rerunning tests to meet deadlines
- Favoring local validation over shared pipeline feedback
- Delaying merges to avoid long or unpredictable wait times
These adaptations weaken the effectiveness of CI/CD and reintroduce human error. Fast, consistent feedback is essential to sustaining trust and reinforcing disciplined behavior.
Conclusion: Why CI/CD Pipeline Challenges Are Architectural, Not Tooling Problems
CI/CD challenges persist because pipeline architecture shapes behavior long before tooling choices or process maturity come into play. Design decisions determine how changes flow, where risk accumulates, and how teams respond under pressure.
The pattern is consistent:
- Systemic constraints exist within core pipeline components
- Those constraints accumulate into operational drag rather than obvious failure
- Teams compensate with reruns, manual checks, and workarounds
- Delivery declines in predictability, speed, and trust
These outcomes emerge even in stable, well maintained pipelines. Reliable tasks do not guarantee a reliable system.
An architecture first perspective clarifies the causal chain. When CI/CD pipelines are treated as systems for reproducible software delivery, performance is driven by structural design rather than individual effort. Success depends on how well tools and processes align with the realities of building, validating, and releasing software.
Common Questions About CI/CD Pipeline Challenges
What are the core components of a CI/CD pipeline?
Core components include source control triggers, automated testing, artifact storage and promotion, and deployment. Together, these layers move changes through validation and into production.
Why do CI/CD pipelines slow down as systems scale?
Pipelines slow as the number of services, dependencies, and teams grows. Coordination overhead, queue time, and validation scope all expand, increasing lead time even when individual stages function correctly.
Are CI/CD challenges caused by tools or architecture?
Most CI/CD challenges are architectural rather than tool based. Tools execute an existing design, but the structure of the pipeline determines coupling, latency, and variability far more than any specific technology choice.
How do testing strategies affect pipeline performance?
Testing strategy directly influences feedback speed and lead time. Fast, reliable tests shorten iteration cycles, while long running test suites extend lead time even if they are consistently accurate.
Why does CI/CD design matter for delivery reliability?
CI/CD design governs predictability and flow into production. Poor design increases drift, reruns, and manual intervention. A well designed system treats the pipeline as a production grade system, where reliability is an outcome of structure and discipline.
Source List:

