


Data is the new gold, but only if we know how to store it, access it, and scale it. That’s where S3 storage comes in.
Amazon S3 was built as a highly scalable object storage solution, and it quickly became the backbone of modern apps. With its durability, flexible storage tiers, smooth API integration, and ability to handle everything from AI training to static websites, it set the bar high for cloud storage.
Let’s explore what S3 storage is, why many teams rely on it, and where it shines. If you’re new to cloud storage or just brushing up, there’s a lot to unpack. So let’s get into it!
Key Takeaways
• Amazon S3 is designed for scalable and durable storage that can handle any data, from small files to multi-petabyte workloads.
• Choosing the right storage class is important for cost efficiency.
• S3 provides encryption by default and access control through IAM and policies.
• Amazon S3 integrates with numerous AWS services. It acts as a central storage layer that connects to services like Athena, Redshift, and more.
• Retrieval charges, data transfer fees, latency, and pricing complexity can affect performance and budgeting if not properly managed.
What is S3 Storage?
Amazon S3 (Simple Storage Service) is cloud storage at an industrial scale. It is built to handle everything from personal backups to multi-petabyte data lakes.
When it launched in 2006, S3 didn’t just offer storage in the cloud. It redefined how storage worked. As AWS’s first service, it quickly became the foundation of modern cloud infrastructure.
Unlike traditional file systems, Amazon S3 uses a flat namespace. It stores data as objects, each wrapped with metadata and a unique key inside a bucket. Though it can appear like folders, it’s a high-performance key-value store that’s built for massive scalability and rapid access.
Why it matters? This model powers everything from real-time retrieval to multi-petabyte data lakes, all without the overhead of legacy file systems.
How It Works
S3 storage is engineered for resilience at scale. The moment you upload an object, S3 silently copies it across multiple Availability Zones, each one physically isolated. This architecture is why S3 delivers 11 nines of durability. Hardware fails. Regions go down. Your data stays up.
What does 11 nines mean?
11 nines of durability refers to the 99.999999999% probability that your data will not be lost. With 11 nines, you can store 10 million objects and statistically lose just one every 10,000 years. It’s engineered to almost never fail.
By design, all interaction is API-driven. Whether you’re moving petabytes or a single log file, it happens via REST endpoints, AWS SDKs, or the CLI.
And S3 doesn’t just sit there. It triggers events. Upload a file? It can fire off a Lambda function. Delete an object? Launch a downstream process. Real-time automation is baked in.
S3 Storage** Classes**
AWS offers six storage classes, and each one is tailored for different access patterns and cost considerations.
Here’s a quick overview:
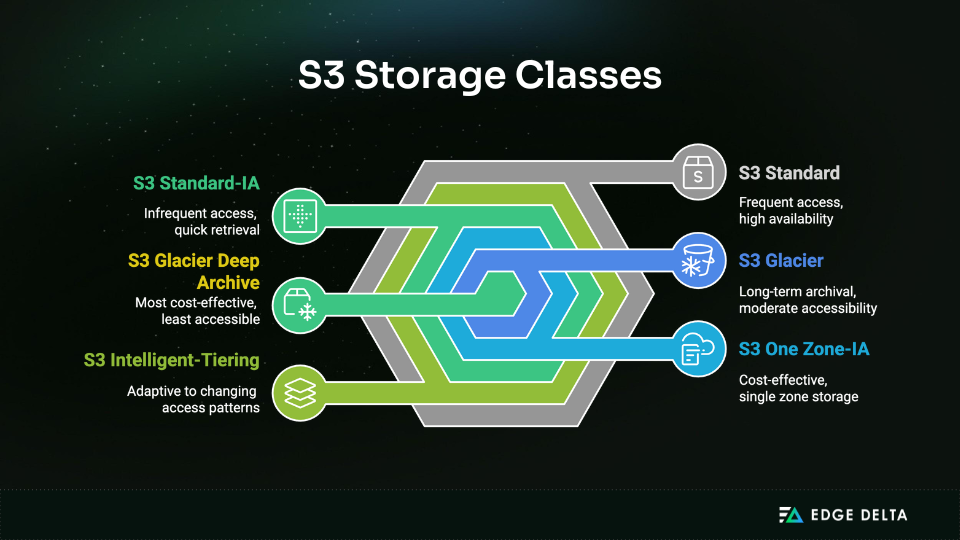
- S3 Standard: The go-to for frequently accessed data. Fast, highly available, and ideal for active content like websites, applications, and streaming assets.
- S3 Standard-IA (Infrequent Access): For files you need quickly but don’t touch often — like monthly reports or backup snapshots. Same speed as Standard, but has cheaper storage and higher retrieval costs.
- S3 Intelligent-Tiering: For unpredictable workloads. It auto-moves data between frequent and infrequent tiers without performance hits. Perfect for data with changing access patterns.
- S3 One Zone-IA: Like Standard-IA, but stored in a single Availability Zone. Cheaper, but with less redundancy. Best for re-creatable or secondary copies.
- S3 Glacier: Long-term archival with retrieval times ranging from minutes to hours. Ideal for compliance archives and data you rarely need.
- S3 Glacier Deep Archive: The cheapest option, built for cold storage. Retrieval can take up to 12 hours. Use it for data you might need someday but probably won’t.
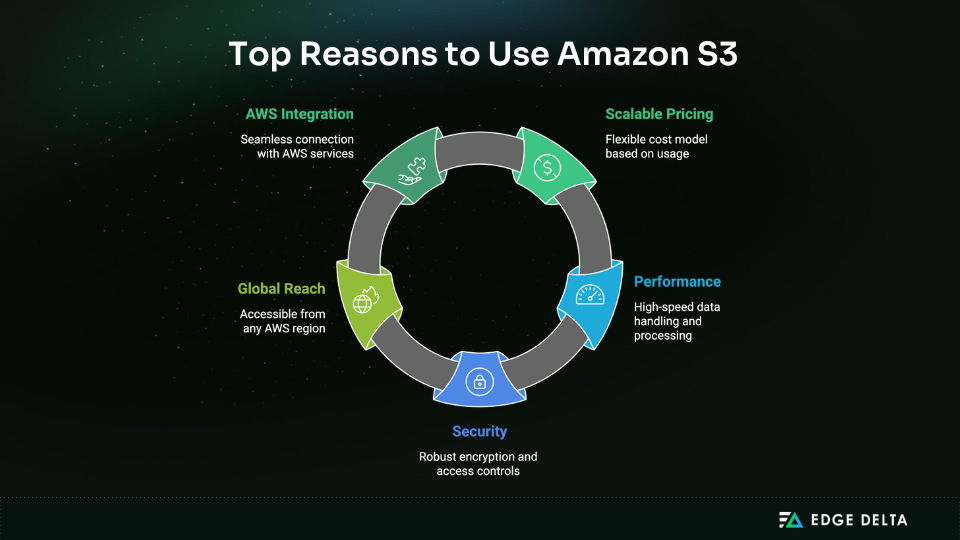
Why Use Amazon S3?
Over a hundred trillion objects are stored in S3 today, and for good reason: it hits the sweet spot between scale, performance, and cost. Find out why S3 is the default choice for cloud storage below.
Scalable, Tiered Pricing
Ditch the bulky hardware and unnecessary excess. S3 scales with your data, not your budget. From 10 terabytes to 100 petabytes, its pay-as-you-go model means you only shell out for what you use.
If you need fast access, go with Standard. Got cold data? IA and One Zone-IA have you covered. Are you archiving for the long haul? Glacier Deep Archive serves it up for as low as $0.00099 per GB.
Built to Perform at Scale
Amazon S3 is designed to easily handle demanding workloads. It can manage millions of requests per second when set up properly. It serves as the foundation for everything from large-scale real-time analytics to streaming services.
Multi-part uploads and parallel reads supercharge your data flow, while S3 Select lets you pull exactly what you need from huge files. No full downloads are required.
Need global speed? Pair it with Amazon CloudFront to cache content closer to your users and keep performance snappy worldwide. It’s no wonder Netflix leans on S3 to stream content to over 100 million users around the globe.
Enterprise-Grade Security, No Compromises
Amazon S3 fortifies your data. Out of the box, everything is encrypted at rest with AES-256 or AWS KMS-managed keys and protected in transit via TLS. You get fine-grained access control with IAM policies, bucket ACLs, public access blocking, and even multi-factor delete to keep mistakes and breaches in check.
If you even want to take it further, S3 access logs can help you monitor and optimize how data is being used to give you a clear picture of who accessed what and when.
Looking for compliance? S3 got you covered. You can count on it from HIPAA and PCI-DSS to SOC 2 and GDPR. Plus, it seamlessly integrates with heavyweight AWS tools like GuardDuty for real-time threat detection, CloudTrail for thorough auditing, and Config for compliance tracking.
It’s not just secure. It’s enterprise-grade and trusted by 90% of Fortune 100 companies.
Global Reach
The best thing about Amazon S3 is that you can access it from any AWS region. You have nothing to worry about regarding infrastructure. No RAID arrays to monitor, no disks to replace, and no scaling issues.
Thanks to Amazon CloudFront and cross-region replication, your data is always available for your users. Distributing media, backups, and static assets across the globe is made simple.
Seamless Integration Across AWS
Amazon S3 is the backbone of the AWS ecosystem. With deep integration across 200+ AWS services, it transforms into a central hub for everything from analytics to automation.
Run queries with Athena. Launch machine learning pipelines in SageMaker. Trigger Lambda functions. Catalog with Glue. Analyze at scale in Redshift. Whether you’re storing logs for CloudTrail or snapshots for EC2, everything fits together perfectly with S3.
Pro-Tip*: If CloudTrail costs are stacking up, check out the easy steps to* cut CloudTrail costs using Edge Delta without losing fidelity.
S3 Storage** Use Cases**
S3 can handle just about any task you throw at it. Whether you want to back up your data, train AI models, or roll out apps on a large scale, S3 is the storage engine that drives the backend.
Let’s take a look at how different industries and workloads are putting it to use in the real world:
Data Backup and Archiving
When it comes to long-term storage, S3 is built for retention, compliance, and massive scale. Services like S3 Glacier and S3 Glacier Deep Archive offer ultra-low-cost storage, making them ideal for backups that might never be touched but must never be lost.
Lifecycle policies automatically move data between storage classes based on access frequency, so teams don’t have to micromanage usage. S3 Object Lock adds compliance-grade immutability, making it a go-to solution for regulated industries.
Case in point: NASDAQ archives over 70 billion records daily using S3, slashing archival costs by 60% while remaining fully compliant with SEC regulations.
Big Data and Analytics
S3 is the powerhouse behind enterprise-scale analytics. Whether you’re working with structured, semi-structured, or unstructured data, S3 can handle it all.
Now, with tools like Amazon Athena, you can run SQL queries right on your data in S3. No database loading, no waiting around.
Need heavy-duty processing or ETL workflows? S3 plays nice with AWS Glue, EMR, and Redshift, too. Plus, if you’re dealing with large-scale ingestion challenges, building a stateless ingestion layer with S3 and SQS can unlock a ton of scalability without the usual headaches.
Just ask GE Aviation. They crank through over 20 billion sensor events every week using S3. That led to predictive maintenance cutting aircraft downtime by 25%.
Application Hosting and Static Websites
Forget web servers. S3 can host static websites with zero backend infrastructure, and when paired with CloudFront, it delivers global content at blazing speed. It supports custom domains, SSL certificates, and intelligent routing, all while offering 99.99% availability.
Airbnb used this stack to serve assets to millions of users, cutting global asset load times by up to 50%, even during heavy traffic spikes.
Media Storage and Distribution
If you’re working with massive video, audio, or image files, S3 is perfect for you. It delivers blazing throughput and scale, with built-in integrations for AWS tools like MediaConvert for transcoding, Transcribe for speech-to-text, and Rekognition for powerful visual analysis.
Take PBS, for example. They moved over 100,000 hours of HD content to S3, cut delivery times by 30%, slashed on-prem storage costs by 40%, and still supported millions of viewers at once without breaking a sweat.
Machine Learning and AI
S3 is purpose-built for AI workloads that demand massive, accessible datasets. Data scientists can feed training sets directly into SageMaker or spin up custom ML pipelines using EC2 GPU instances, with S3 as the central storage hub.
Every object can be versioned, encrypted, and programmatically accessed. Formula 1 relies on S3 to manage terabytes of real-time telemetry, powering ML models that have increased race strategy accuracy by up to 30%.
Software Delivery and DevOps
S3 is a high-availability vault for deploying assets, logs, and containers as well as building artifacts. It integrates natively with services like AWS CodePipeline, CodeBuild, and CodeDeploy, enabling fully automated CI/CD workflows.
Expedia uses S3 to coordinate deployments across over 300 microservices, cutting release times by 50% and reducing rollback incidents by 35%.
**Challenges and Limitations of **S3 Storage
S3 is powerful, but it comes with sharp edges. Ignoring them will literally cost you.
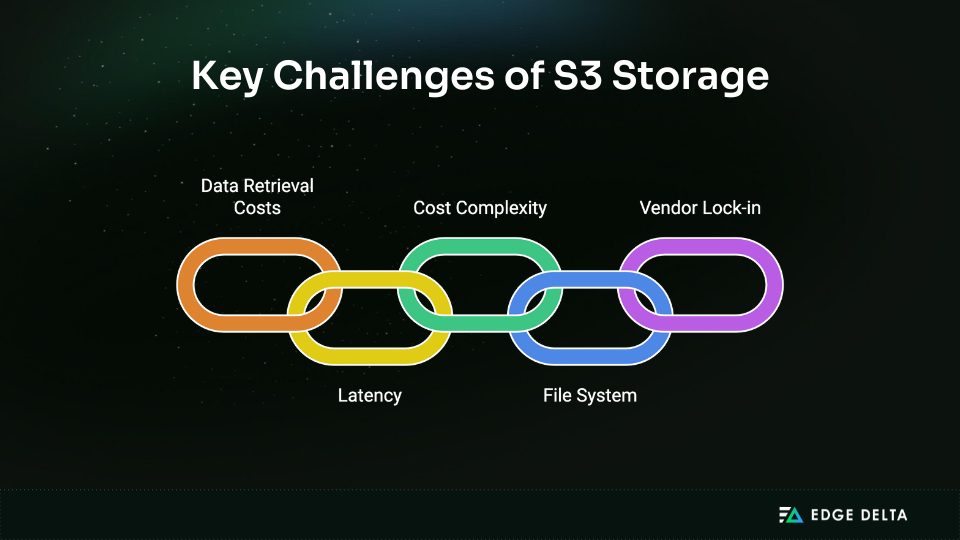
First up: data retrieval costs. Sure, Glacier and Deep Archive look cheap, until you want your data back. That’s when the meter starts running. Retrieval times range from minutes to hours, and each tier has its own pricing rabbit hole.
Be mindful of egress. After the free tier, moving data from S3 to the internet costs $0.09/GB, which quickly mounts up. It’s a silent budget killer.
Then, there’s latency. S3 is built for throughput, not real-time speed. For most apps, a few milliseconds here and there don’t matter. But if you’re in the latency game (live dashboards or algorithmic trading), even one millisecond can feel like hitting a speed bump at 80 mph.
What about cost complexity? S3 pricing looks simple until it isn’t. You’re charged for storage, requests, lifecycle transitions, and data transfer. And if you’ve got millions of small files or a spike in API calls, your costs can skyrocket fast. If you have a few wrong configurations, your bill will read like a phonebook.
S3 also isn’t your typical file system. No folder structure, no POSIX compliance, and no file locking. You can simulate folders using prefixes, but it’s still just a flat object store. Apps built for on-prem filesystems need workarounds.
And yes, vendor lock-in is real. The S3 API is now the cloud storage standard, which is great until you try to leave. Migrating large datasets to another provider, even one with S3-compatible endpoints like Wasabi or MinIO isn’t always seamless. The deeper your integrations go, the more complex the exit.
Best Practices and Optimization Tips
S3 is powerful, but innovative configuration turns it into a high-performance, cost-efficient machine. Here are seven best practices that move the needle:
1. Use the Right Storage Class: Don’t just stick with S3 Standard alone. Use Intelligent-Tiering for unpredictable workloads. It automatically moves cold data to cheaper tiers. Glacier and Deep Archive are ideal for long-term storage at less than $1/TB per month.
2. Set Lifecycle Policies: Keep your buckets lean. Automate transitions to lower-cost classes or delete stale data with lifecycle rules. It’s the easiest way to cut storage costs without lifting a finger.
3. Optimize Large Uploads: Use multi-part uploads for files over 100 MB. It speeds things up, allows recovery if interrupted, and plays nice with large datasets. Add S3 Transfer Acceleration to boost cross-region upload speeds using AWS’s global edge network.
4. Lock Down Security: Encrypt everything. SSE-S3 or SSE-KMS should be your default. Apply strict IAM roles, bucket policies, and block public access by default. For sensitive workloads, use MFA Delete to protect against accidental or unauthorized deletions.
5. Monitor and Alert: Turn on the S3 Storage Lens and set up CloudWatch alerts. Track object counts, access patterns, and cost anomalies before they turn into billing disasters. Insight is your best defense.
6. Don’t Misuse Versioning: Versioning helps recover overwritten or deleted files, but it’s not a backup plan. Combine it with MFA Delete or use Object Lock for regulatory-grade protection with WORM enforcement.
7. Automate: S3 shines when it’s hands-off. Use event notifications to trigger AWS Lambda functions, automate workflows, or kick off processing jobs. Treat your storage like an infrastructure, not a manual to-do list.
Conclusion
Amazon S3 is more than just any other storage. It’s the backbone of the modern cloud. S3 powers backups, data lakes, AI workloads, static sites, and global content delivery. With 11 nines of durability and virtually unlimited scale, it’s built to handle anything.
But raw power needs smart handling. Without optimized storage classes, automated lifecycle rules, and tight access controls, you’re leaving performance on the table and money on the floor.
Build smarter. Scale faster. Spend less. Start by auditing your S3 buckets and putting these best practices into action.
S3 Storage** FAQs**
Is AWS S3 private or public?
Private by default. You choose what goes public. You can lock it down or open it up.
Can I use S3 for free?
Yep! The free tier gives you 5GB, 20,000 GETs, and 2,000 PUTs each month.
How many buckets can I have in S3?
You get 100 buckets per AWS account by default. If you need more, you can file a support request.

