


Today’s IT infrastructure generates far more telemetry data than operations teams can realistically manage. Hybrid cloud environments, microservices architectures, and dynamic scaling have made it impossible for any team to operate complex systems manually.
Traditional monitoring relies on static thresholds, reactive alerts, and siloed tools. As environments grow more distributed and dynamic, these approaches struggle to keep pace, often creating alert fatigue instead of actionable insight.
AIOps, or Artificial Intelligence for IT Operations, applies machine learning and automation to help teams detect anomalies, correlate events, and accelerate response. Mature AIOps deployments report 30–40% faster mean time to resolution and 50–80% reductions in operational costs.
Market momentum reflects this shift. The AIOps market is projected to grow from an estimated 14 to 17 billion dollars today to more than 36 billion dollars by 2030. However, these results are not automatic. Meaningful gains typically emerge at scale, most often in environments processing 10TB or more of telemetry data per month.
This guide breaks down what AIOps is, its core benefits, real-world use cases, and practical steps for successful implementation.
Key Takeaways
∙ AIOps delivers the greatest impact at scale. The most meaningful gains appear when telemetry data volume and system complexity exceed what teams can manage manually.
∙ Its primary value is noise reduction. Event correlation and anomaly detection reduce false positives and accelerate incident resolution.
∙ Cost efficiency is a major driver. Filtering telemetry data before ingestion can significantly reduce observability and SIEM spend.
∙ AIOps shifts teams from reactive to proactive. Predictive insights help prevent incidents instead of responding after impact.
∙ Success depends on readiness, not tools. Structured data, clear ownership, and organizational buy-in are essential.
What Is AIOps?
Modern IT operations face a scale problem that traditional monitoring cannot solve. Distributed systems generate massive telemetry volumes, while cloud-native architectures change continuously. Human-driven workflows struggle to keep pace with this complexity.
AIOps was created to address this challenge by using intelligence and automation on a broad scale. Instead of relying on human analysis and reactive response, AIOps helps teams uncover patterns, cut down on noise, and act faster.
This section explains what AIOps is, what it replaces, and how it works in practice.
Core Definition and Purpose
AIOps stands for Artificial Intelligence for IT Operations. Gartner coined the term because the nature of IT infrastructure had outgrown what could be manually monitored.
Distributed systems generate large volumes of logs, metrics, traces, and events, while cloud-native architectures change continuously. Static thresholds and manual workflows struggle to keep pace, creating noise rather than clarity.
AIOps relies on machine learning and automation to minimize noise in alerts, help relate alerts to each other, and expedite the response to an incident. By examining patterns across systems rather than individual metrics, it highlights key incidents with context and probable causes.
At a functional level, AIOps is designed to:
- Detect anomalies across logs, metrics, traces, and events
- Correlate related signals into a single incident
- Accelerate root cause analysis using system dependencies
- Shift teams from reactive troubleshooting to proactive operations
This shows that monitoring is moving from being based on rules to being based on patterns. When fixed thresholds are crossed, traditional tools send out notifications. This happens a lot during typical activities like deployments or scaling events. AIOps learns how things normally behave and changes on the fly as systems change.
What AIOps is not:
- A replacement for engineers, but an augmentation tool
- A single product, but a platform combining multiple capabilities
- Plug-and-play, requiring sufficient data and tuning
- Perfectly deterministic, operating probabilistically
In practice, AIOps helps teams focus on resolution instead of triage by surfacing critical signals from noise.
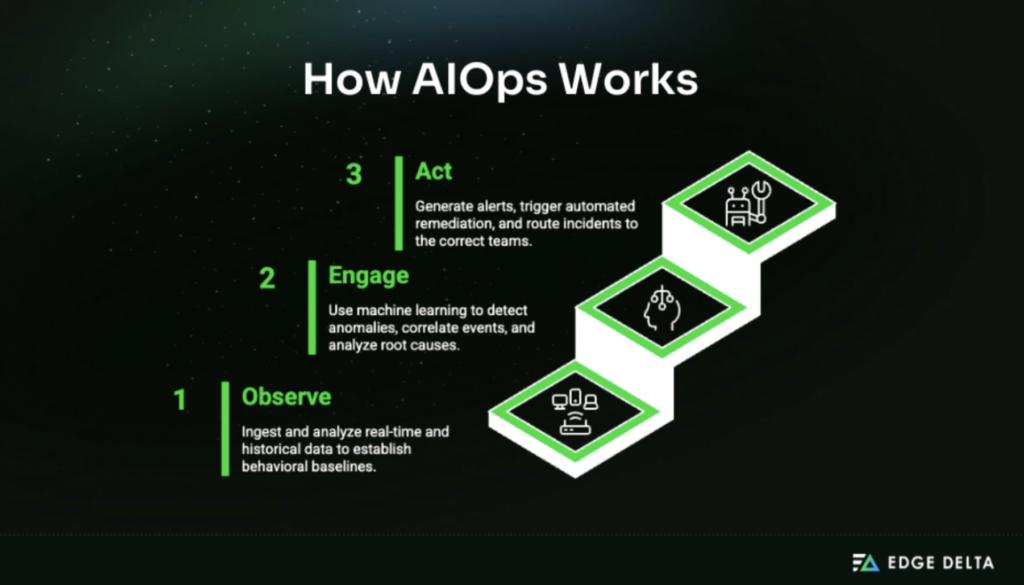
How AIOps Works: Three-Phase Process
AIOps platforms operate through a continuous three-phase cycle that turns telemetry data into action.
Phase 1: Observe
AIOps takes in logs, metrics, traces, events, topology data, and CMDB records from places like Kubernetes, cloud platforms, APM tools, and security systems. Real-time and historical data set behavioral baselines.
Phase 2: Engage
Machine learning searches for patterns across systems. Anomaly detection alerts on deviations from the learned patterns. Event correlation combines relevant events into a single incident. Root cause analysis traces problems based on dependencies.
Predictive analytics forecast risks 24–48 hours ahead. Natural language processing interprets unstructured logs and tickets, as documented by IBM and Dynatrace.
Phase 3: Act
AIOps sends notifications in order of importance, starts automated fixes, and sends incidents to the right teams. Feedback loops increase accuracy over time, and humans stay in the loop for important decisions.
Example: During Black Friday, an e-commerce checkout API slows. AIOps correlates API errors, database timeouts, and customer complaints, identifies a payment gateway DNS issue, and routes the incident with a prior fix attached. Manual troubleshooting takes hours. AIOps resolves it in minutes.
Why AIOps Emerged: The IT Complexity Crisis
AIOps did not emerge because traditional IT practices failed. It emerged because the operating environment evolved faster than human-driven processes could scale. Approaches designed for static infrastructure began to break down in dynamic, distributed systems.
Modern infrastructure has expanded exponentially. Environments that once ran on roughly 100 physical servers now support 10,000 or more ephemeral containers.
Cloud-native architectures scale continuously and automatically. Microservices have replaced monoliths. Serverless platforms operate alongside containers and legacy systems. Hybrid and multi-cloud deployments are now the norm rather than the exception.
Several forces converged to overwhelm traditional operations models:
- Telemetry growth: Data volumes increased roughly fivefold in three years, yet around 80% of collected telemetry data is noise. Making sense of observability data is a core operational challenge.
- Alert fatigue: Research from Sumo Logic shows the top 5% of monitors trigger alerts seven times more often than average.
- Architecture sprawl: Containers, serverless, and legacy systems now run side by side across hybrid and multi-cloud environments.
Speed requirements intensified the pressure. A 99.99% uptime SLA allows only 52 minutes of downtime per year. Exceeding that window leads to financial penalties.
According to Gartner, average enterprise downtime costs $5,400 to $9,000 per minute. Outages also damage customer trust and brand credibility. Amazon-level reliability is now expected across most digital services.
Teams face a growing skills gap. Organizations cannot hire fast enough to manage this complexity manually. Observability spending often reaches $100,000 to over $1 million annually. Volume-based pricing models become unsustainable as telemetry volumes continue to grow.
The market responded to these forces. Gartner predicts that 30% of large companies adopted AIOps in 2024, up from 5% in 2018. Large companies such as Netflix, Uber, and Spotify have adopted AIOps.
This convergence of complexity, data volume, and speed requirements made AI-enhanced operations essential for competitive IT. Five core benefits drive adoption, which we will explore in the next section.
The Five Core Benefits of AIOps
AIOps delivers five measurable business outcomes, validated across hundreds of enterprise deployments. The following benefits are supported by research from Gartner, Dynatrace, IBM, and major platform vendors.
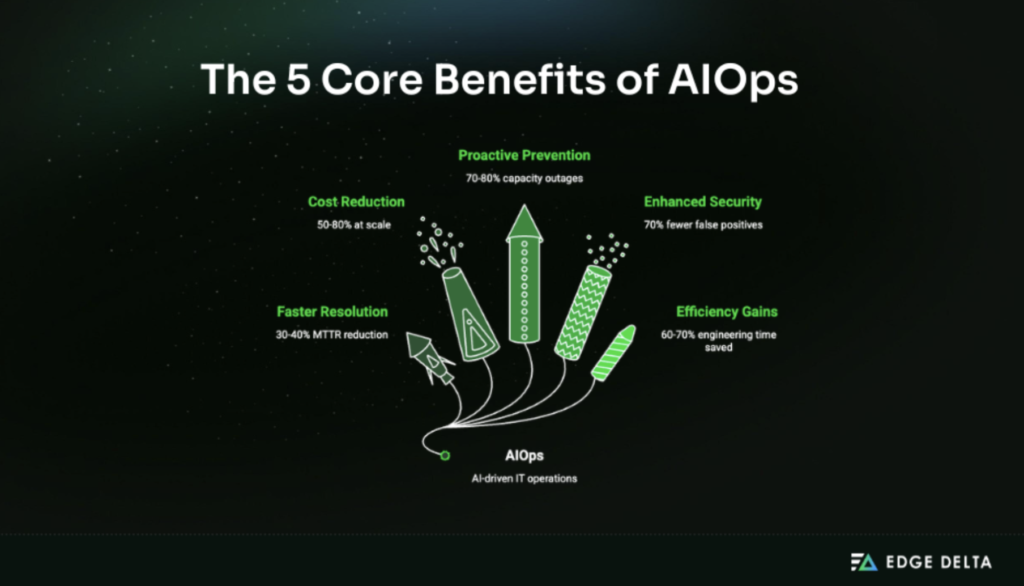
Benefit #1: Faster Incident Resolution (30–40% MTTR Reduction)
Resolving incidents consumes a lot of engineering time in today’s environment. According to research by Dynatrace, teams spend 60-70% of their time on troubleshooting, and it takes 45-90 minutes to resolve critical incidents in distributed systems because the signals are distributed across various tools.
Alert fatigue further slows response. Sumo Logic reports that the top 5% of monitors trigger alerts seven times more frequently than average. Each delay is costly. Gartner estimates enterprise downtime at $5,400 to $9,000 per minute.
AIOps assists by correlating related problems before humans are engaged. Machine learning integrates noisy alerts into a single incident, displays how services relate to each other, and provides possible reasons with context.
Organizations adopting AIOps consistently report:
- 30–40% faster MTTR
- 60–90% fewer false-positive alerts
- Significant alert consolidation
At scale, the impact is material. Fifty incidents per year at 90 minutes each and $7,000 per minute equals $31.5M in downtime. A 40% MTTR reduction lowers that to $18.9M, saving $12.6M annually. Even with a $500K implementation, ROI is typically achieved within weeks.
Benefit #2: Observability Cost Reduction (50–80% at Scale)
The cost of observability increases substantially as more telemetry data is gathered. For mid to large-sized businesses, the annual cost typically ranges between $100,000 and over $1 million, primarily due to the pricing structure of $2-$10 per gigabyte.
Cloud-native architectures exacerbate the issue. Containers and microservices generate 10-100 times more telemetry data than monolithic applications, and 80% of that data is irrelevant to analysis.
AIOps reduces spend by optimizing data before ingestion. Instead of collecting everything, modern platforms like Edge Delta filter, route, and sample telemetry data at the source, preserving high-value signals while eliminating noise. When performed at scale, organizations can expect the following:
- 50–80% reduction in total observability spend
- Up to 80% telemetry volume reduction
- More predictable costs as environments scale
In practice, an environment ingesting 50TB per month at $4 per GB incurs roughly $2.4M annually. Reducing volume by 80% lowers ingestion costs to under $500K, with the remainder archived to low-cost storage. Break-even typically occurs above 10TB of monthly telemetry, after which savings compound quickly.
Benefit #3: Proactive Problem Prevention
Traditional IT operations respond to issues after they occur. Teams take action only once thresholds are breached and users are already impacted.
Capacity planning often relies on historical averages, while gradual performance degradation goes unnoticed. Preventable issues escalate into outages, and emergency remediation can cost 30 to 40% more than planned scaling.
AIOps enables predictive operations by learning normal growth and usage patterns from historical telemetry data. Instead of reacting to fixed limits, it forecasts potential failures and provides early warning, allowing teams to resolve risks during planned maintenance windows rather than active incidents.
Predictive AIOps commonly delivers:
- 24–48 hours of advance warning for capacity exhaustion
- 70–80% fewer capacity-related outages
- Early detection of gradual performance degradation
For example, in a database environment, AIOps identified connection pool utilization rising steadily from 60% to 78% over two weeks. It projected exhaustion within 72 hours. Engineers increased capacity during a scheduled maintenance window, preventing a potential weekend outage and avoiding downstream revenue impact.
Benefit #4: Enhanced Security and Compliance Automation
Security teams face rising data volumes and increasing regulatory exposure. Sensitive information often appears in unexpected log fields, while SIEM platforms typically charge $2–$10 per gigabyte for ingestion.
At the same time, industry research shows roughly 80% of security alerts are false positives, forcing analysts to investigate large volumes of low-signal events. Under regulations such as GDPR, violations can result in fines of up to €20M or 4% of annual revenue.
AIOps addresses risk and expense at ingestion. Machine learning identifies and obfuscates sensitive data before it goes to centralized storage, reducing compliance risk. Context-aware threat scoring calls out high-risk activity and suppresses unnecessary alerts.
Organizations adopting AIOps report:
- Automated PII detection and obfuscation before storage
- 70% or greater reduction in security false positives
- Lower SIEM ingestion volumes without reduced coverage
Benefit #5: Operational Efficiency and Team Productivity
Traditional observability requires a lot of manual effort. Engineers have to spend time tweaking thresholds, maintaining rules, and responding to alerts after every infrastructure change.
In dynamic environments, this work often consumes one to two full-time roles, while alert fatigue drives after-hours pages, burnout, and turnover. Many teams report spending up to 70% of their time firefighting rather than improving systems.
AIOps reduces this load by automating routine operational work. Self-learning baselines adapt as workloads change, while dependency-aware analysis speeds root cause identification. Alert volumes drop as noise is suppressed, allowing engineers to focus on resolution rather than triage.
Teams adopting AIOps typically see:
- 60–70% reduction in troubleshooting time
- Over 70% less configuration overhead
- Fewer after-hours alerts due to reduced noise
This allows teams to scale operations without scaling headcount.
Traditional IT Ops vs AIOps: An Evolution
Many organizations are still using the traditional IT operations approach that has been working for them for years. This approach is based on human expertise, well-crafted rules, and a good understanding of their systems.
AIOps represents an evolution that augments these foundations rather than replacing them with AI-driven capabilities. Understanding this enhancement helps organizations decide whether they need this next step now or should first optimize their existing approaches.
How AIOps Enhances Traditional IT Operations
| Capability | Traditional Approach | AIOps Enhancement | Typical Improvement |
|---|---|---|---|
| Anomaly Detection | Manual threshold configuration for known patterns | ML-driven dynamic baselines that adapt automatically | 60–90% fewer false positives |
| Incident Response | Human-driven correlation using experience | Automated correlation with human validation | 30–40% faster MTTR |
| Alert Management | Rule-based severity set by administrators | ML-based business impact scoring | ~7× daily alerts → <1× daily |
| Root Cause Analysis | Manual investigation across multiple tools | Automated dependency tracing with confirmation | ~2 hours → ~15 minutes |
| Scalability | Linear growth tied to staff increases | AI absorbs growth without added headcount | Headcount avoidance |
| Adaptation | Manual updates after infrastructure changes | Self-optimizing during scaling events | ~75% less configuration effort |
These improvements are supported by research and benchmarks from Dynatrace, Gartner, and IBM.
When Each Approach Works Best
The right approach depends on scale, system dynamics, and operational pressure. Traditional practices and AIOps each work well under different conditions.
When traditional approaches work well:
Traditional IT operations remain effective in environments that are smaller, stable, and well understood. Teams in these situations usually get more value from improving existing processes before adding AI.
- Small-scale environments with fewer than 50 servers and under 5TB of monthly telemetry
- Stable architectures with infrequent infrastructure changes
- Teams with deep domain expertise and sufficient operational capacity
- Predictable workloads with well-known failure patterns
For organizations in this category, focusing on better dashboards, tuned alerts, and automated runbooks typically delivers faster returns than introducing AIOps.
When AIOps provides a clear advantage:
AIOps becomes valuable once scale and change velocity exceed what humans can manage efficiently. At this point, manual approaches struggle to keep up without adding headcount.
- Telemetry volumes exceed 10TB per month
- Dynamic environments using Kubernetes, microservices, or multi-cloud
- High change velocity with 10 or more deployments per day
- Alert fatigue impacts on-call effectiveness, often more than five alerts per engineer daily
- Observability costs growing 30% or more year over year
At this scale, traditional approaches require unsustainable staffing increases, while AIOps enables existing teams to manage far more systems.
Organizations meeting these scale thresholds achieve quantified benefits. The following sections detail evidence for each outcome.
AIOps Use Cases: Where to Start for Maximum ROI
AIOps delivers different ROI profiles depending on where it is applied. Value depends on data volume, cost pressure, operational complexity, and integration effort. Organizations that start with the wrong use case often delay returns.
The following prioritization framework helps identify where to implement AIOps first for the fastest and most measurable value. Match your primary pain points with the highest-impact applications.
AIOps Use Case Prioritization Matrix
| Use Case | ROI Potential | Implementation Difficulty | Time to Value | Priority |
|---|---|---|---|---|
| Security / SIEM Optimization | Very High (50–80% savings) | Low | 2–4 weeks | 🟢 Start Here |
| Cloud-Native / Kubernetes | High (MTTR reduction) | Medium | 4–8 weeks | 🟢 High |
| Multi-Cloud Management | High | High | 8–12 weeks | 🟡 Medium |
| DevOps / CI-CD Pipelines | Medium | Low | 2–4 weeks | 🟢 Quick Win |
| Legacy Infrastructure | Low | Very High | 12+ weeks | 🔴 Deprioritize |
🟢 High Priority: Best ROI-to-effort ratio
🟡 Medium Priority: After quick wins
🔴 Low Priority: Defer until scale improves
Top Three High-ROI Use Cases
Some AIOps use cases deliver faster and more predictable ROI than others. The following three consistently produce the strongest results, combining high impact with relatively short time to value.
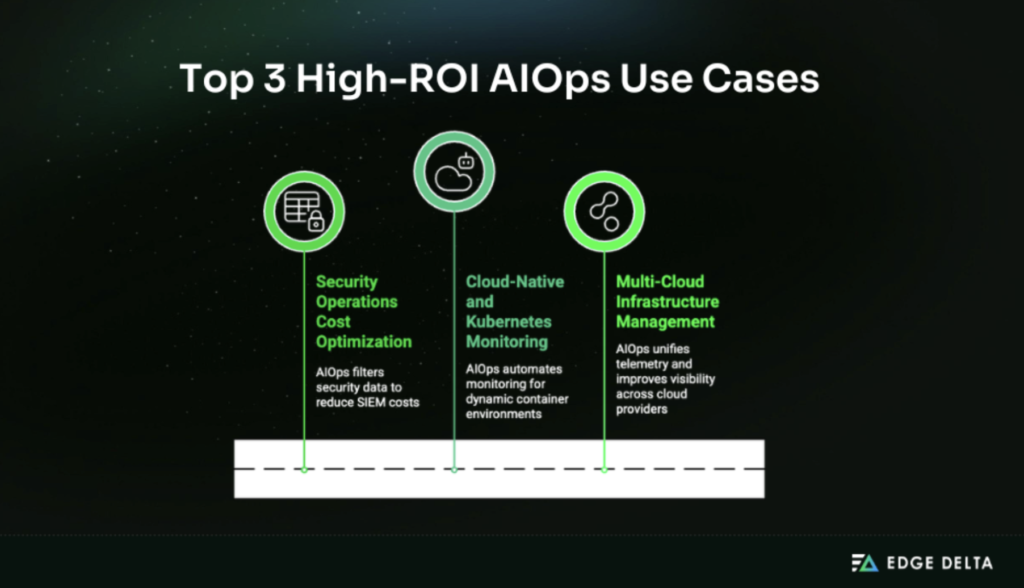
1. Security Operations (SIEM) Cost Optimization
SIEM platforms typically charge $2–10 per GB for ingestion. Most security events are low value, yet billed at full price. Analysts often face hundreds of alerts daily, while compliance requires multi-year retention.
If an organization is ingesting 100 TB per year, SIEM costs can easily exceed $200K-$1M. AIOps filters security data before ingestion, which can be costly. Low-risk security events are discarded, and machine learning threat scoring is based on high-risk activity.
Sensitive fields are masked automatically. Low-priority events are archived to object storage at $0.023 per GB while remaining searchable.
This use case is most relevant for organizations in compliance-heavy industries such as finance, healthcare, and government, where SIEM ingestion costs and long-term retention requirements scale quickly.
Measured outcome:
- Traditional SIEM: $800K annually (100TB)
- AI-enhanced: $300K SIEM (20TB) + $2K archival
- Savings: ~$498K annually (≈62%)
2. Cloud-Native and Kubernetes Monitoring
Containers generate 10-100 times more telemetry data than monoliths. Pods scale rapidly and have a short lifetime. Manual configuration is not feasible for 10-100 deployments per day or for complex microservice dependencies.
AIOps learns to identify services automatically and continues to adapt. Baselines change with dynamic scaling. Distributed tracing correlates requests to numerous downstream services. Notifications provide service impact information and dependency context.
This scenario is most appropriate for organizations that employ multiple cloud providers or a combination of on-premises and cloud infrastructures, where visibility and cost management are divided.
Measured outcome:
- Traditional MTTR: 2–4 hours
- AIOps MTTR: 15–30 minutes
- Impact: ~$15K–$30K avoided per major incident
3. Multi-Cloud Infrastructure Management
Multi-cloud environments fragment visibility across AWS, Azure, GCP, and on-prem tools. Cross-cloud transactions are difficult to trace. Cost allocation and data residency enforcement add complexity.
AIOps unifies telemetry across providers, correlates transactions end-to-end, and enforces regional routing. Cost attribution improves FinOps visibility.
This use case is most applicable to organizations operating across multiple cloud providers or hybrid environments, where visibility and cost attribution are fragmented.
Measured outcome:
- 40–50% faster issue identification
- Up to 60% tooling cost reduction
When to Wait
AIOps should be deprioritized when scale is insufficient. Organizations processing under 10TB monthly often see limited ROI.
If implementation requires 40–80 hours and observability spend is low, optimizing existing tools is more effective. Reassess when data volume doubles or exceeds 10TB.
AIOps also requires structured telemetry. Plain-text logs reduce accuracy. Teams should implement structured logging first, typically over 3–6 months. In environments where decisions are 100% deterministic, AI assists with triage, but humans retain the last word.
Break-even: AIOps becomes cost-effective above 10TB of monthly volume and $50K in annual observability spend.
AIOps Implementation: Quick Readiness Assessment
This two-minute self-assessment will help you determine whether your organization is ready for AIOps and positioned to achieve a return on investment within six months. It can also help you avoid adopting too early by clarifying whether AIOps will deliver value now or after foundational improvements are in place.
Select all statements that apply, then review the assessment results carefully before moving forward.
| Readiness Area | Diagnostic Questions |
|---|---|
| 1. Scale | ▢ We process 10TB or more of monthly telemetry data across logs, metrics, and traces ▢ Our annual observability spend exceeds $50K ▢ Telemetry volume is growing 20% or more year over year |
| 2. Operational Pain | ▢ Observability costs increased 30% or more in the past year ▢ Average incident MTTR exceeds 45 minutes ▢ Teams spend 60% or more of time on alert triage and firefighting ▢ A small set of monitors triggers repeatedly each day (alert fatigue) ▢ Kubernetes or microservices adoption significantly increased complexity |
| 3. Implementation Capacity | ▢ 0.5–1 FTE platform engineering capacity is available ▢ The organization can commit 3–6 months to deployment and ROI realization ▢ Executive sponsorship is secured with budget approval ▢ Logs use structured formats such as JSON or key-value pairs |
How to interpret your results:
| Boxes Checked | Readiness Level | Recommended Next Step |
|---|---|---|
| 5 or more | Strong AIOps fit | Proceed with vendor evaluation. Expected ROI in 3–6 months |
| 3–4 | Moderate fit | Start with a pilot use case (SIEM optimization or Kubernetes monitoring). Expected ROI in 6–9 months |
| 0–2 | Not ready yet | Focus on structured logging, baseline metrics, and team capacity. Reassess in 6–12 months |
Minimum Viable Deployment Checklist
Phase 1: Before Starting (Non-Negotiables)
| Requirement | Ready |
|---|---|
| Monthly telemetry volume exceeds 10TB | ▢ |
| Logs use structured formats (JSON or key-value) | ▢ |
| 0.5+ FTE platform engineering capacity allocated | ▢ |
| Executive sponsorship secured with a 3–6 month ROI agreement | ▢ |
Organizations that meet these requirements consistently see a good return on investment. Teams that don’t have a hard time getting past pilots.
Phase 2: First 90 Days (ROI Accelerators)
| Success Enabler | Ready |
|---|---|
| 30+ days of historical telemetry available for ML training | ▢ |
| Existing observability tools and integrations documented | ▢ |
| Baseline MTTR, alert volume, and costs captured | ▢ |
| One high-value application or service selected as pilot | ▢ |
These steps reduce tuning time and make ROI measurable instead of anecdotal.
Phase 3: By Month 6 (Optimization)
| Outcome | Complete |
|---|---|
| ROI validated using cost and MTTR improvements | ▢ |
| Stakeholder review completed | ▢ |
| Expansion roadmap defined for next use cases | ▢ |
Organizations that meet MVP requirements usually get 50% to 80% of the return on investment they expect. Teams that skip foundational steps often only get 20% to 40% of the way there or give up on implementation completely.
Conclusion: Is AIOps Right for Your Organization?
AIOps is not a universal solution, but it delivers measurable impact at the right scale. Organizations processing 10TB or more of monthly telemetry and spending $50K or more annually on observability consistently report faster incident resolution, reduced alert noise, and meaningful cost reductions.
The key is readiness. Teams with structured logging, executive sponsorship, and dedicated platform ownership see results within three to six months. Those without these foundations often struggle to move beyond pilots.
AIOps works best when introduced deliberately. Start with a high-impact use case such as SIEM optimization or Kubernetes monitoring. Prove value quickly, measure results, and expand incrementally.
Used correctly, AIOps augments human expertise rather than replacing it. It helps teams manage growing system complexity without scaling headcount at the same rate.
The question is not whether AIOps works. It’s whether your organization is ready to benefit from it now.ward readiness and reassess in 6–12 months.
Frequently Asked Questions
What is AIOps in simple terms?
AIOps uses machine learning to help IT teams monitor systems, detect issues, and resolve incidents faster. It analyzes large volumes of logs, metrics, and events to reduce alert noise, identify root causes, and predict problems before users are affected.
How much does AIOps cost to implement?
AIOps typically costs $50K–$150K in the first year for managed platforms, depending on scale and use case. Organizations already spending $50K+ annually on observability often recover costs within six months through reduced downtime and lower data ingestion spend.
What’s the difference between AIOps and observability?
Observability provides visibility into systems by collecting logs, metrics, and traces. AIOps adds intelligence on top of that data, using machine learning to correlate signals, detect anomalies, and prioritize incidents automatically.
How long does it take to see AIOps ROI?
Most organizations see measurable AIOps ROI within three to six months. Initial setup and learning typically take one to two months, followed by reduced alert noise, faster incident resolution, and observable cost savings.
Do I need data scientists to use AIOps?
No. Most AIOps platforms use pre-trained models that retrain automatically. Teams usually need platform engineering skills, not data scientists, unless building custom or self-hosted machine learning systems.
Is AIOps accurate enough for production?
Yes. In production environments, AIOps platforms typically achieve 91–95% accuracy for tasks like anomaly detection and alert triage. Best practice is to automate analysis while keeping humans involved in high-risk decisions.
Sources:

