


The Challenges of Datadog Pricing
Datadog was built more than a decade ago, when businesses were generating significantly smaller volumes of telemetry data and running simpler cloud-based infrastructures. For modern organizations leveraging cloud-native and distributed environments — especially those generating hundreds of terabytes (TB) or even petabytes (PBs) of telemetry data daily — Datadog is becoming a serious financial burden and risk. Not only is their pricing structure expensive, it’s unnecessarily complex, leaving you with significant overage charges if you exceed your pre-set ingestion limits.
Take, for example, a large Kubernetes environment that is running several computationally intensive workflows, generating log data in the region of hundreds of TBs per day in total. If you were to ship all 200 TBs of data directly into Datadog, and keep it there for even just a few weeks before discarding it, you could easily rack up a seven-figure bill at the end of the year. The problem is compounded by the dynamic nature of Kubernetes environments; when workflows become more computationally intensive, Kubernetes automatically scales in response, resulting in massive spikes of telemetry data generation. This can also quickly push you past your set budget limits, adding overage fees on top of the already costly bill.
For most organizations running systems in the cloud at scale, going all-in with Datadog is entirely unsustainable financially — especially as telemetry data volumes continue to grow year over year. The good news is that if you (or your teams) love Datadog, but want to keep the costs within budget, there’s a different strategy.
Cut Datadog Costs with Edge Delta
The best way to reduce your Datadog bill is to send less data to Datadog. Most organizations do this by filtering out entire portions of their telemetry data completely. But how do you know what to filter out? What if a problem occurs, and that removed data was exactly what you needed for troubleshooting?
Edge Delta’s Telemetry Pipelines were designed to help address this exact issue. Our Telemetry Pipelines give you full control over your telemetry data by shifting processing left, allowing you to:
- Intelligently optimize the data you’re sending into Datadog
- Reduce the amount of data you’re sending into Datadog, and route it instead to other more cost-optimized downstream destinations, like Edge Delta and Elastic
Here’s how that might work in our Kubernetes example:
First, we can deploy an Edge Delta agent fleet directly into your Kubernetes cluster. Once configured, we can now begin processing, filtering, and enriching that data as it’s created at the source.
Instead of immediately shipping everything into Datadog, let’s optimize our data streams and send only the most important data for ingestion.
To start, we’ll capture all error-level logs and convert them into Edge Delta Patterns. This will intelligently compress our log data and retain relevant high-level information, which we can send into Datadog for monitoring and further analysis.
We’re also going to send all error-level logs into Edge Delta’s Log Platform, which is far more cost-effective. Finally, we’ll be sure to send a full copy of all raw data into S3 archival storage, for compliance purposes:
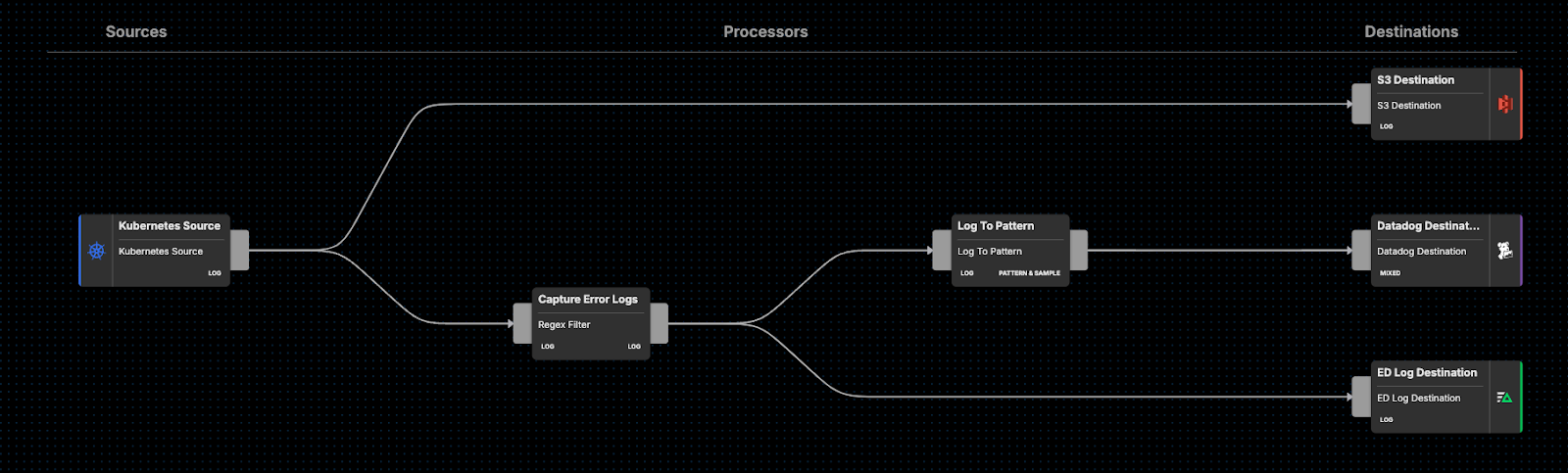
Let’s imagine that error logs constitute 20% of our total Kubernetes logs. By compressing 20% of our 200 TB per day logs into Patterns, we’ve compressed 40 TB of data into ~10 megabytes (MB)!
By sending all 200 TB per day of log data through Edge Delta’s Telemetry Pipelines, and keeping it tiered across these destinations, we’ve significantly reduced your Datadog bill while enabling you to leverage their tools to ensure your environments are running smoothly. For a more cost-effective solution with comparable capabilities, you can instead use Edge Delta’s Log Management platform for the majority of your logs.
This example is similar to the route that one of our customers, Fama, took. Fama had been working to streamline its infrastructure and operations by adopting a serverless architecture hosted by AWS. To free their engineering team from the maintenance and overhead of hosting their own log management platform, they integrated Datadog into their observability stack.
As Fama grew, so did their team’s Datadog bill. Eventually it became clear they needed to find a solution to help reduce the volumes of data they were indexing into Datadog. The team explored a variety of options, but as Fama CTO Brendten Eickstaedt explained, “On the surface, the options sounded great. But when we did the cost analysis, these solutions ended up being just as expensive, if not more expensive, than Datadog.”
Eventually the Fama team landed on Edge Delta, as our intelligent Telemetry Pipelines have the ability to reduce costs by beginning to process data at the source. Instead of streaming entire datasets into Datadog directly, Eickstaedt’s team utilized our pipelines to first optimize data into insights and statistics, and send those values instead. Using Edge Delta, they were able to maintain high quality insights while cutting their Datadog monthly bill by 80%.
“Edge Delta really gave us the confidence that we could index less data in Datadog, but still have that full observability that we’re looking for,” Eickstaedt said, after Fama had integrated Edge Delta into their stack.
Looking Ahead
Datadog is a useful platform for monitoring your environments and analyzing your telemetry data. However, it’s not built to handle data at modern-day scale, from both a performance and a cost perspective.
Instead of trying to discard data, or find another legacy platform to replace Datadog, you can implement a fundamentally different approach to your observability practices. With Edge Delta’s Telemetry Pipelines, not only will you reduce your Datadog costs, you’ll also gain back full control over your telemetry data.
Want to try it out? Get hands-on with our telemetry pipelines in our Playground, or start a free trial.



