


AWS Auto Scaling handles your resources automatically based on real-time demand so that your applications can remain responsive and cost-effective. Whether you are working with EC2 instances, containers, or serverless functions, AWS Auto Scaling automatically scales up or down so that you do not have to.
And while this is a powerful capability to have, getting it right is not always straightforward. Teams often struggle with selecting the right policies, tracking the metrics that indicate when a resource scale should occur properly, and understanding the causes behind scaling behavior in the first place.
This is where observability and log analytics can help. With a product like Edge Delta, you can gain deeper visibility into your scaling behavior and detect problems that may go undetected by using performance as a guide with no assumptions.
In this post, we will cover how AWS Auto Scaling works, how it works with your strategies, and how you can tune it for real-world performance.
What Is AWS Auto Scaling?
AWS Auto Scaling is a native service that automatically manages your cloud resources to keep application performance and cost in check. It keeps track of your applications and reacts to demand, adding capacity and removing capacity as needed in response to changes in demand. AWS Auto Scaling helps you avoid overprovisioning during periods of slow demand and underprovisioning during periods of traffic spikes.
You can use Auto Scaling across a wide range of AWS services, including:
- EC2 Auto Scaling Groups: Automatically increase or decrease the number of EC2 instances to handle traffic changes.
- ECS and EKS Cluster Scaling: Add or remove containers based on CPU, memory usage, or custom metrics.
- DynamoDB Auto Scaling: Adjust read and write capacity for your tables and indexes in response to traffic patterns.
- Application Auto Scaling for Custom Resources: Apply the same dynamic scaling to services like Kinesis, Aurora replicas, or custom applications.
To understand how Auto Scaling makes decisions, it’s helpful to know the core components behind it:
- Scaling Policies: Rules that tell AWS when to scale in or out based on specific conditions.
- Target Tracking Policies: Automatically adjust capacity to maintain a chosen metric, like keeping average CPU usage at 50%.
- Step and Simple Scaling Policies: Make fixed or step-based adjustments based on CloudWatch alarms.
- Predictive Scaling (for EC2): Uses historical data to forecast traffic and scale out ahead of time.
Now that you know what AWS Auto Scaling is and where it fits in, let’s look closely at how it works behind the scenes.
How AWS Auto Scaling Works
Auto Scaling runs through a continuous cycle of monitoring, gathering insight, and reactive behavior within AWS to align your resources with demand. Here is how it works, step by step:
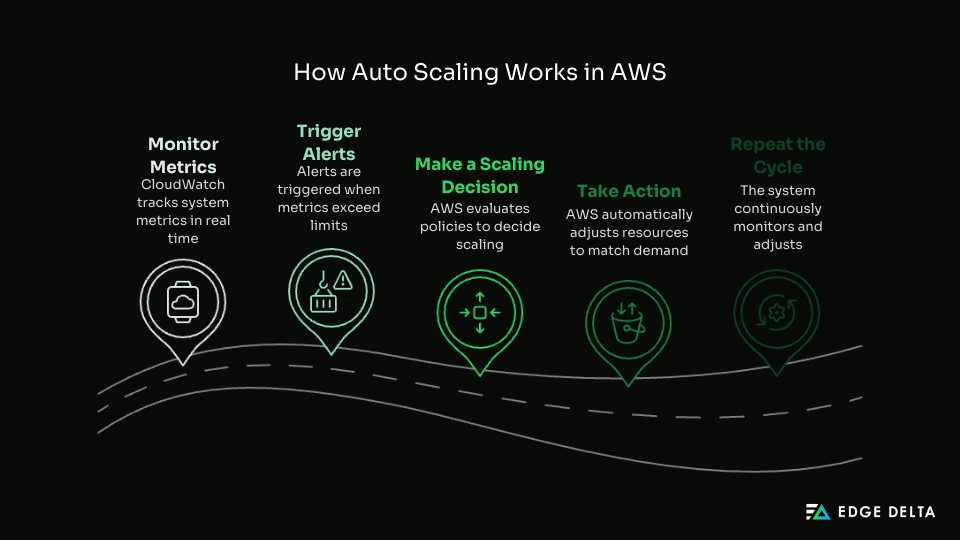
1. Monitoring Metrics via CloudWatch
AWS Auto Scaling monitors certain metrics, such as CPU operations, memory, and custom metrics you’ve set specific to your workloads. All metrics are monitored in real time via Amazon CloudWatch.
2. Triggering Conditions
When metrics exceed a predefined threshold (for example, CPU usage exceeds 70 percent), a CloudWatch alarm is triggered. The alarm indicates the need to scale.
3. Scaling Decisions
Upon alarm, and based on any policies you’ve defined (like target tracking or step scaling), Auto Scaling decides to scale your workloads either up or down.
4. Scaled Actions
If scaling should take action, AWS will automatically provision a set of instances, change the count of containers, or increase the capacity on services like DynamoDB. Similarly, when demand is low, AWS removes those capacity units that were provisioned.
5. The Feedback Loop
After an Auto Scaling action has taken place, the system will track your metrics. This feedback loop helps the system find the right cost-to-performance ratio. It sounds simple, but real-life variables can affect how Auto Scaling behaves.
Below are some of the more common issues teams face.
Common Challenges with AWS Auto Scaling
Despite its intelligent and automated architecture, AWS Auto Scaling isn’t always flawless right out of the box. It can create more issues than it fixes if not configured properly. The following are some typical problems that teams encounter:
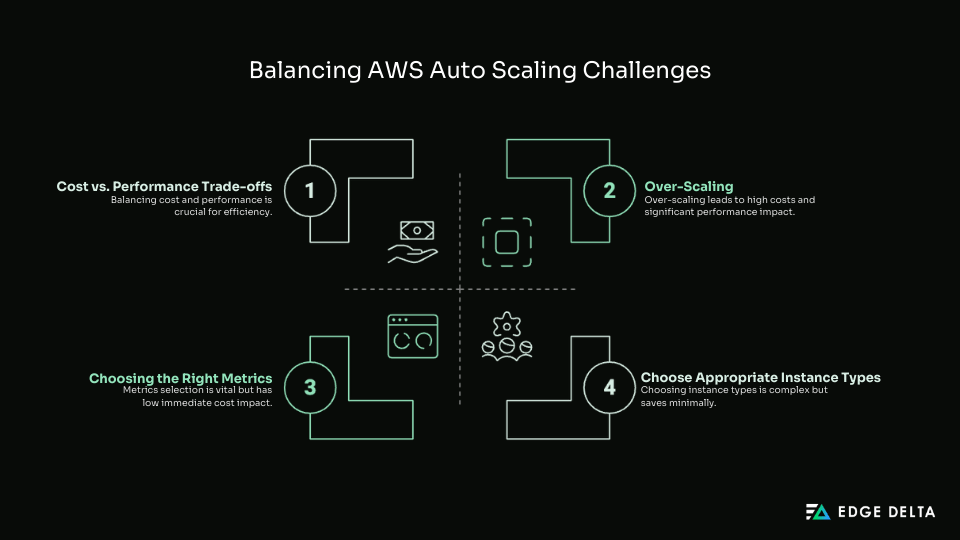
Choosing the Right Metrics
It’s easy to watch basic numbers like CPU usage, but those don’t always give you the complete picture. Your app might still slow down because of long wait times, a slow database, or too many requests at once. To scale the right way, you need to continuously monitor your application.
Over-scaling & Under-Scaling
If your configurations are not set correctly, the Auto Scaling feature could take things a little too far. For instance, it could start adding or removing resources too quickly, resulting in instability in your app, negative customer experience, and lost revenue.
Latency and Lead Time
Scaling takes time. In general, it does not instantly add servers or containers. If the scaling infrastructure waits too long, the users may have slow load times or encounter errors while they wait for more resources to become available.
Cost vs. Performance Trade-offs
You don’t want to spend more than you have to, but you also don’t want your app to struggle. If you add too much, you’re wasting money. If you don’t add enough, users might have a bad experience. The goal is to find a balance that keeps things running well without overspending.
Using Edge Delta’s Log Analytics to Optimize Auto Scaling
System metrics like CPU and memory only tell part of the story. With Edge Delta, you can dig into logs that reflect real application behavior, giving you the context you need to fine-tune scaling policies.
Identify Hidden Bottlenecks
Logs from services, load balancers, and apps reveal slow requests, retry storms, or other issues that raw system stats miss. Edge Delta ties these signals to scaling events so you can pinpoint the root cause.
Correlate Scaling Events with Application Changes
By comparing logs before and after a scaling event, you can identify faults or traffic patterns that triggered resource strain — helping you adjust both the timing and method of scaling.
Improve Anomaly Detection and Preemptive Scaling
Edge Delta’s anomaly detection flags unusual log activity, like sudden spikes in error codes, before CPU or memory metrics react. That early warning lets you scale proactively or tweak policies to stay ahead of demand.
Validate the Effectiveness of the Scaling Policy
Logs show whether changes to a policy actually work: Are 5xx errors gone? Are requests faster during peak load? With clear feedback, you can iterate with confidence.
Manage Complex Scaling Setups
In multi-service or microservice environments, logs give you a unified view. Edge Delta helps you see how each service scales — and how those scaling patterns impact overall system performance.
Practical Example: Improving EC2 Auto Scaling Decisions
Imagine running a web application on several EC2 instances behind a load balancer. You’ve set up a target tracking policy to keep CPU usage around 50 percent. During peak traffic, users start experiencing slow load times.
How Edge Delta Helps
Edge Delta reveals slowdowns that CPU metrics miss.
Logs surface issues metrics alone can’t — like specific API endpoints hammering the database during peak traffic. Even when CPU looks fine, Edge Delta shows you where the app is actually struggling.
Edge Delta helps you pick better metrics for scaling.
Armed with log insights, you can create custom CloudWatch metrics around request latency or error rates instead of relying on CPU. Edge Delta even pre-processes logs before sending them, cutting CloudWatch costs while giving you sharper signals.
Edge Delta helps your app scale earlier and stay ahead of demand.
With better metrics in place, your scaling policy reacts before users notice slowdowns. New EC2 instances spin up ahead of demand, keeping performance smooth and error rates low, even during traffic surges.
Best Practices for AWS Auto Scaling Optimization
Fine-tuning AWS Auto Scaling isn’t just about setting it and forgetting it. With the right strategies, you can make it more accurate, responsive, and cost-effective. Here are a few best practices to get the most out of your setup:

Combining Metrics and Logs
While metrics like CPU usage or request latency are essential for determining when and how to scale, they are not all-encompassing. Logging provides additional context, can help to surface root causes, and provides a basis for optimizing your scaling policy to the actual behavior of the application.
Implementing Predictive Scaling
If you notice traffic spikes at certain times, such as weekday mornings or during product launches, it’s a good idea to turn on predictive scaling. This lets AWS add resources ahead of time so you’re prepared before the traffic hits instead of trying to catch up afterward.
Setting Appropriate Cooldowns
Cooldown periods stop the system from scaling too often. Use your logs to see how long it takes for new instances to become fully ready. Then, adjust your cooldown settings to avoid unnecessary scale-ins or scale-outs.
Continuously Iterating
Traffic patterns change, and so should your scaling. After you deploy new features or updates, be sure to examine your logs. It is the simplest way to know if your scaling is continuing to reflect your application’s needs.
Conclusion
AWS Auto Scaling helps you manage changes in demand without constantly watching over your setup. It keeps your apps fast, reliable, and cost-effective. But to get the most out of it, you need more than just a few basic limits.
Adding log analytics from Edge Delta gives you a better look at what’s really happening behind the scenes. This makes it easier to choose the right metrics, fine-tune your scaling rules, and support your decisions with real data.
Whether you’re using EC2 instances, containers, or serverless services, logs help you stay ahead. They keep things running smoothly and give your users a better experience.
FAQs on AWS Auto Scaling
What is Auto Scaling in AWS?
It automatically adjusts compute resources based on demand to maintain performance and control costs.
Is Auto Scaling free in AWS?
Yes, the service is free. You only pay for the resources it manages, like EC2 or DynamoDB.
How do I set up Auto Scaling for EC2?
Create an Auto Scaling Group, define a launch template, and set scaling policies using the AWS Console or CLI.
Can Auto Scaling work with non-EC2 services?
Yes. It also supports ECS, EKS, DynamoDB, Lambda, and more.

