


Scaling infrastructure is essential for maintaining performance, availability, and cost efficiency as demand fluctuates. With cloud-native platforms like AWS, Azure, and Google Cloud, scaling is dynamic and often automated, but the wrong approach can lead to high costs, downtime, or both. For example, a Google study shows that a one-second mobile delay can cut conversions by 20%. For this reason, successful scaling is driven by important metrics like error rate and latency, per Google’s SRE Handbook.
The challenge is that scaling decisions are often made without complete visibility. Teams may attribute latency to CPU constraints or assume that adding nodes will resolve performance bottlenecks, but without accurate observability data, these are educated guesses at best. Log analytics can provide the evidence needed to validate assumptions, identify true bottlenecks, and guide scaling strategies.
This article examines the advantages, challenges, and limitations of horizontal and vertical scaling. We also show how tools such as Edge Delta’s log analytics enable teams to align scaling decisions with real-world data, ensuring more reliable, cost-effective infrastructure management across monolithic and microservice environments.
Key Takeaways
• Scaling is about tweaking a system’s capacity to keep up with demand. Doing so blindly can lead to wasted resources.
• Vertical scaling adds more resources (CPU, memory, or storage) to a single machine. It’s straightforward to implement and often provides immediate performance gains, but costs rise quickly, and scalability is ultimately capped by the physical limits of the hardware.
• Horizontal scaling distributes workloads across multiple machines or nodes. It allows systems to handle larger and more variable workloads and avoids single-node limits, but it introduces the complexity of managing distributed systems, networking, and data consistency.
• Observability is non-negotiable — without logs, metrics, and traces, scaling decisions become guesswork.
• Edge Delta brings intelligence to scaling, enabling users to surface real-time log insights, detect problems early, and optimize resource use.
What Is Scaling in Cloud Architecture?
Scaling is the process of adjusting system capacity to match demand — whether serving 1,000 users or 10 million. When infrastructure falls behind, performance drops and users churn.
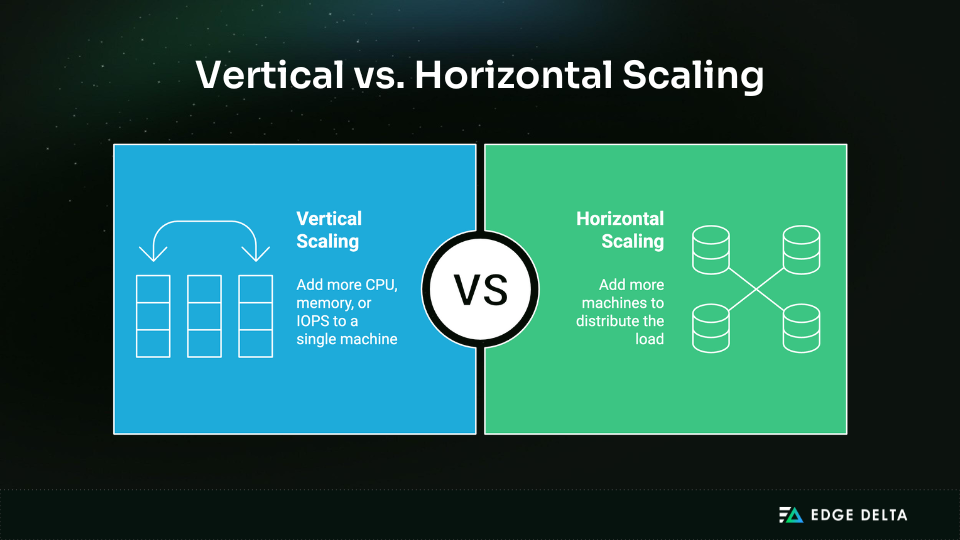
Organizations generally choose between two strategies: vertical scaling, which adds more resources to a single machine, and horizontal scaling, which distributes workloads across multiple nodes. Each approach offers advantages but also introduces trade-offs in reliability, cost, and operational complexity.
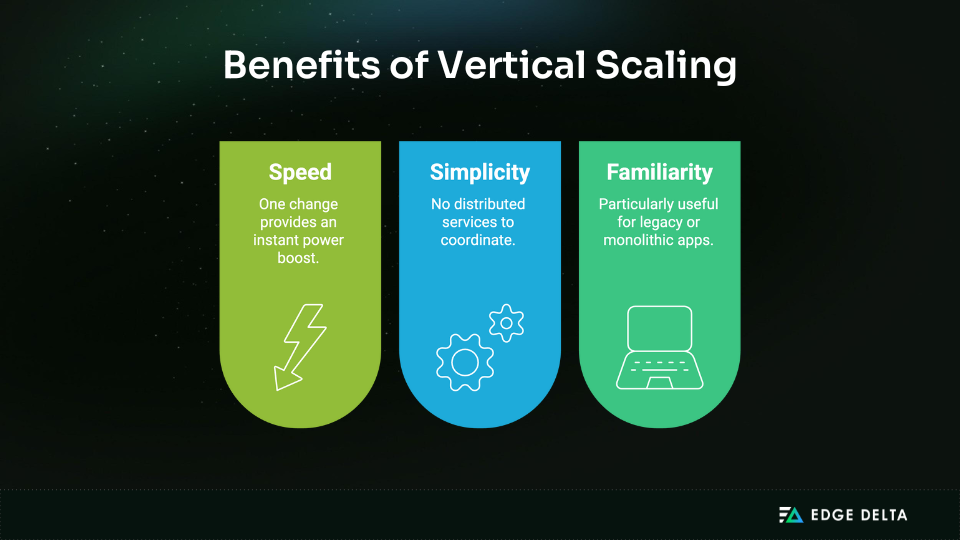
Vertical Scaling (Scale Up)

At first, vertical scaling feels like the most straightforward option: upgrade your existing server or cloud instance, and keep building without the complexity of distributed systems. This makes it a natural fit in the early stages or for applications running on monolithic architectures.
Teams often choose vertical scaling because it involves:
- Simpler architecture: Everything runs on a single system with no need for sharding or inter-node communication.
- Fewer components to manage: Less infrastructure means fewer potential points of failure.
- Lower operational overhead: With one machine, monitoring and troubleshooting remain relatively simple.
But while vertical scaling is efficient and practical at first, its benefits taper off as demand grows. Key risks include:
- Hard limits: Even the largest EC2 or Google Cloud VMs eventually max out, forcing a costly re-architecture.
- Single point of failure: If the main server fails, so does the entire service. High availability helps but undermines the simplicity that drew teams to this model.
- Escalating costs: Bigger machines are disproportionately expensive. For instance, upgrading from an AWS
c6a.4xlargeto ac6a.8xlargemore than doubles the cost without doubling performance.
Vertical scaling remains effective for stateful, legacy, or tightly coupled applications. But once you hit its ceiling, cost and risk quickly outweigh convenience, prompting many teams to consider horizontal scaling instead.
Horizontal Scaling (Scale Out)
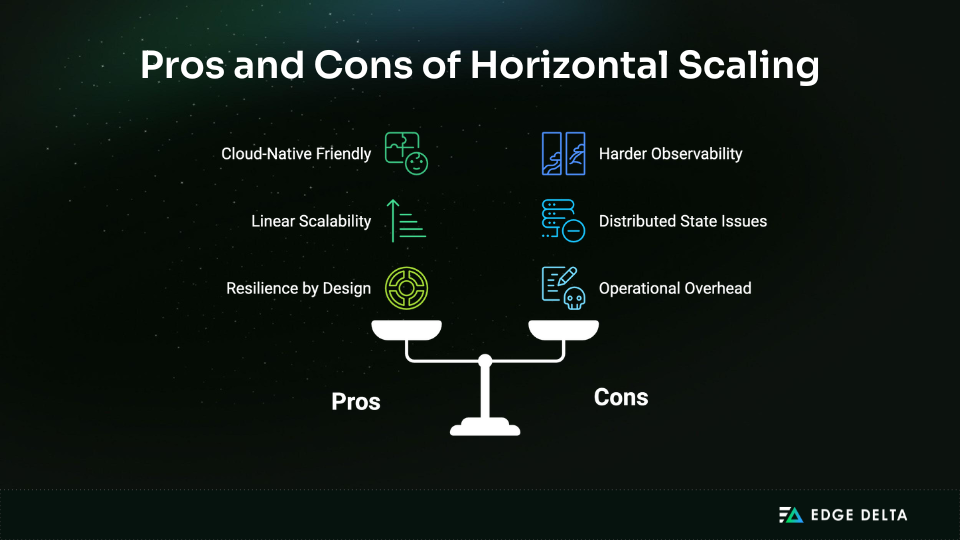
Horizontal scaling expands capacity by adding servers or instances that share the workload in parallel. Rather than building one bigger machine, you distribute traffic across many smaller ones — a model that underpins modern cloud-native systems.
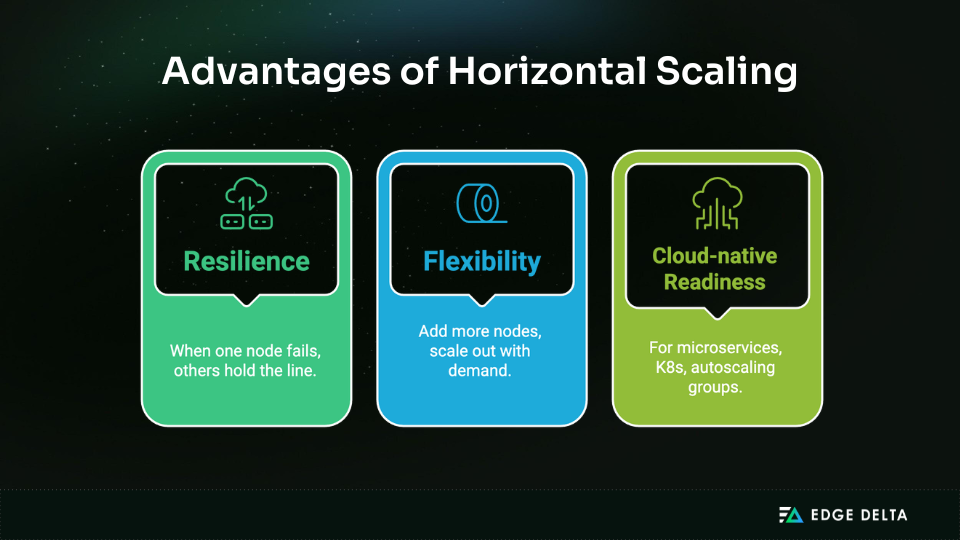
Why it works well today:
- Resilience by design: If one node fails, others stay online, reducing the risk of total outages.
- Predictable growth: Capacity scales linearly as nodes are added, making expansion repeatable.
- Cloud-native alignment: Perfect for microservices, containers, and autoscaling frameworks.
A well-known example is Netflix. Their architecture handles over one billion daily API requests — expanding into billions of internal service calls — by distributing them across thousands of Amazon EC2 instances(Netflix Tech Blog).
But horizontal scaling comes with tradeoffs, including:
- Operational overhead: More machines mean more logs, alerts, and systems to manage.
- State and data challenges: Synchronizing sessions, caches, and consistency across nodes is complex.
- Visibility gaps: Diagnosing issues across dozens — or hundreds — of nodes requires unified observability.
When paired with strong observability, horizontal scaling delivers resilience and flexibility. Without it, complexity itself becomes the bottleneck. The first step in any scaling decision isn’t “add more” — it’s knowing where the system is straining.
Common Challenges in Scaling
The most common mistake teams make is scaling without sufficient insight. Throwing more compute at a problem may buy time, but it won’t fix an issue that has been misdiagnosed. Beyond adding capacity, teams face three persistent hurdles: pinpointing the real bottlenecks, managing the operational complexity that comes with growth, and forecasting the true cost of each choice. Without addressing these head-on, scaling efforts often solve one problem while creating two more.
1. Identifying Bottlenecks
Issues like CPU saturation, memory leaks, disk I/O bottlenecks, or network congestion all look similar on the surface, but treating them without root-cause clarity wastes resources and leaves problems unresolved. Teams recognize this gap. New Relic’s 2023 Observability Forecast found that while 75% of organizations monitor security, only 23% deploy deeper performance capabilities such as synthetic checks. Without comprehensive observability, scaling decisions are little more than educated guesses.
2. Managing Complexity
Horizontal scaling means increased resilience, but it also introduces architectural weight — distributed coordination, cross-service communication, and a surge of log sources and spans in distributed tracing. According to New Relic, the average organization now uses 9–10 observability tools, up from just 6 in 2022. This tool sprawl makes it harder to connect signals and keep monitoring consistent across complex environments. This can result in small issues remaining hidden in fragmented data and later ballooning into major incidents after remaining unchecked.
3. Predicting Cost and Performance Impact
At first glance, vertical scaling looks simple, but it quickly becomes expensive. High-tier instances carry steep price jumps — on AWS, for example, upgrading from a c6a.4xlarge to a c6a.8xlarge more than doubles the hourly cost.
Horizontal scaling, when done well, can stretch budgets further. Autoscaling and tight resource monitoring help you add capacity only when needed, but without fixing underlying inefficiencies, scaling out just multiplies waste across more machines.
Horizontal vs. Vertical Scaling**: No One-Size-Fits-All Approach**
Vertical scaling offers simplicity—you increase CPU, memory, or storage on a single machine, keeping the architecture straightforward. But growth eventually runs into hardware limits, escalating costs, and the inflexibility of tightly coupled systems.
Horizontal scaling distributes workloads across multiple machines, bringing resilience and near-linear expansion. Yet this approach comes with trade-offs: higher operational overhead, distributed state management, and more complex observability requirements.
The challenge is that scaling out often obscures what’s happening inside the system. According to New Relic’s 2023 report, only 33% of organizations achieved full-stack observability, despite a 58% increase in adoption year over year.
That’s why observability — especially log analytics — becomes a game-changer. With platforms like Edge Delta, you move beyond gut calls and incomplete dashboards to get real-time, distributed visibility that shows:
- Where latency spikes originate (e.g., CPU, memory, I/O, or downstream)
- Whether vertical scaling has reached diminishing returns
- How horizontal scaling is performing beyond just node counts
The best strategy isn’t about choosing “up” or “out,” but knowing your system well enough to decide when to do either — or both.
Why Observability Matters for Scaling
Organizations can allocate additional hardware or provision more instances, but without visibility into the underlying system behavior, these actions amount to guesswork rather than strategy. Effective scaling requires understanding where latency originates, what is driving resource contention, and which services are most vulnerable under stress.
As environments expand, complexity increases. Additional infrastructure introduces more components, dependencies, and potential points of failure. Importantly, these failures are not always evident in high-level CPU or memory dashboards. They often surface first in logs, traces, and anomaly patterns. This is why observability is a prerequisite for sustainable scaling.
Evidence supports this: according to New Relic’s 2023 Observability Forecast, 53 percent of organizations with full-stack observability reported improved uptime and reliability, and nearly half observed a reduction in security vulnerabilities.
Comprehensive observability enables organizations to:
- Gain end-to-end visibility across the entire request path, from the user interface to the database.
- Diagnose issues in real time, such as latency spikes, error bursts, or memory leaks.
- Correlate context across logs, metrics, and traces, providing clarity on both the root cause and the downstream impact of performance issues.
Perhaps most importantly, observability allows for benchmarking and comparison — before and after scaling, during load testing, and under production traffic. Scaling decisions can then be grounded in empirical evidence rather than assumptions.
The next section will examine how Edge Delta operationalizes this principle, enabling teams to translate observability into actionable insights for scaling at speed and with confidence.
Using EdgeDelta’s Log Analytics to Inform Scaling Strategy
Edge Delta addresses the challenges involved in scaling by shifting observability closer to where infrastructure operates. Rather than relying on delayed dashboards or static metrics, Edge Delta delivers real-time, distributed log intelligence at the source.
This approach ensures that whether an organization is scaling vertically, horizontally, or adopting a hybrid model, decisions are guided by accurate, timely insights rather than assumptions. The result is a scaling strategy executed with clarity and precision.
Unified Log Collection Across Architectures
Edge Delta provides a single, consistent way to manage log data regardless of system design. Whether scaling up a monolithic application or scaling out a microservices environment, its distributed architecture can ingest and analyze millions of log lines per second. By leveraging stateless ingestion at scale, Edge Delta ensures high-volume data flows are processed without performance degradation, helping teams stay ahead of data growth while controlling costs.
For example, an e-commerce platform experiencing seasonal sales spikes can rely on Edge Delta to capture and analyze surging checkout and API logs in real time. This enables engineering teams to identify bottlenecks immediately, ensure system reliability, and avoid overspending on infrastructure during peak demand.
Real-Time Anomaly Detection
Edge Delta uses AI-driven anomaly detection to surface issues the moment they occur, allowing teams to address problems before they escalate. This proactive approach is especially valuable during scaling, when even small deviations can cascade into outages.
For example, Edge Delta can detect a spike in authentication failures less than a minute after a new login service image is deployed. By correlating anomalies directly with deployment events, teams can quickly identify the faulty image, perform a rapid rollback, and minimized downtime. This kind of real-time, distributed intelligence ensures scaling decisions are guided by evidence.
Comparative Analysis of Scaling Efforts
Edge Delta enables teams to benchmark system performance before and after scaling, making it clear whether changes actually improve reliability and efficiency. By analyzing log patterns and metrics in real time, teams can measure the impact of scaling on request latency, concurrency, and throughput. Edge Delta’s Kubernetes HTTP Traffic Load Testing Tool offers a concrete benchmark you can trust. It enables teams to to perform performance regression and capacity-planning workflows. For example, a team could run progressive load tests in Kubernetes environments, capturing detailed resource usage (CPU, memory, etc.) alongside traffic patterns, then correlate latency spikes and resource utilization to uncover bottlenecks before deploying changes to production.
Cost and Complexity Insights
Edge Delta’s Telemetry Pipelines enable you to preprocess data right at the source — filtering, enriching, masking, or converting logs before they ever hit downstream platforms. By doing so, you send only what matters to expensive ingest-oriented systems, greatly reducing both costs and noise.
In one published experiment, Edge Delta compared multiple telemetry pipeline architectures and found that processing closer to data sources (i.e. at the edge) led to significantly lower ingestion and storage costs, especially under workloads generating terabytes of log traffic per day.
Case Example: Evaluating Horizontal Scaling with Edge Delta
Consider this hypothetical example. Say a team using Edge Delta’s stateless ingestion and telemetry pipelines observe sharp spikes in log entries per second under high load, alongside growing CPU/memory use, and increased request latency. Error rates begin to climb. Logs reveal retry storms and throttled services. The anomaly detection engine flags issues before service degradation became user-visible.
Before Scaling
With Edge Delta’s stateless ingestion and telemetry pipelines in place, the team observes sharp spikes in log entries per second under high load, alongside growing CPU and memory use, as well as increased request latency. Error rates also begin to climb. Digging in deeper, the logs reveal retry storms and throttled services. The anomaly detection engine flags issues before service degradation become user-visible
After Horizontal Scaling
The team adds more instances of key services. Immediately, Edge Delta shows resource consumption becoming more balanced across nodes, latency stabilizing, and error rates falling. However, a new signal appears: intermittent service timeouts tied to cross-service calls. Upon further investigation, logs and traces point to a misconfigured internal load balancer. Once the misconfiguration is fixed, the errors subside and throughput improves without latency regression.
The Outcome
What this shows is that horizontal scaling alone isn’t sufficient — you need observability to know if it’s delivering expected results. Edge Delta enabled the team to track metrics before and after scaling, validate performance improvements, and catch previously hidden misconfigurations.
Why It Works
Edge Delta processes telemetry data at the edge — before it ever reaches your storage backend — allowing real-time anomaly detection, which accelerates diagnosis during scaling events, whether you’re validating new infrastructure or stressing autoscaling behavior. Because Edge Delta captures metrics and logs in real time at the source, they are able to isolate the component at fault and begin remediation immediately.
Actionable Tips for Smarter Scaling
Scaling is about anticipating demand and responding with precision. Whether preparing for a migration, planning for a traffic surge, or addressing performance degradation, a disciplined approach is essential. Real-time observability and log analytics provide the foundation for making those decisions with confidence.
1. Benchmark Before You Scale
Establish a clear baseline of current system performance. Historical logs and key metrics help identify normal operating conditions, making it easier to measure the real impact of scaling efforts. Without this baseline, you risk optimizing blindly.
2. Monitor Key Metrics & Logs During Experiments:
As infrastructure changes roll out, track throughput, error rates, latency, and resource usage continuously. Real-time log analytics ensures you see the impact of adjustments immediately, enabling faster validation and course correction.
3. Iterate and Refine Based on Log Insights
Scaling is not a one-time event but an ongoing process. Continuous analysis of logs reveals performance bottlenecks, unexpected anomalies, and optimization opportunities. Embedding observability into the deployment pipeline ensures that data directly informs each iteration.
4. Implement Automated Anomaly Detection
AI-driven detection surfaces deviations as they occur, catching emerging issues before they escalate. Automated alerts provide early warning signals, ensuring that scaling does not introduce hidden risks into production environments.
5. Optimize Log Management for Cost Efficiency
High log volumes can quickly drive up costs. Processing data at the source reduces ingestion overhead and storage requirements while preserving visibility. Smarter log management ensures observability remains sustainable at scale.
Conclusion
Scaling is more than a technical adjustment — it’s a strategic decision that directly impacts performance, resilience, and cost. Vertical scaling may offer simplicity, and horizontal scaling provides elasticity, but only observability delivers the clarity needed to choose wisely.
With platforms like Edge Delta, scaling decisions are guided by data rather than guesswork. Real-time log intelligence transforms scaling from reactive firefighting into proactive strategy. The next time your system comes under pressure, the most important question isn’t “How much more can we add?” but rather “What do the logs tell us?”

