


Kubernetes has become the backbone of modern applications, powering over 70% of global containerized workloads. Its flexibility and scalability make it the default choice for enterprises, but deployment strategies often determine whether teams deliver reliably or risk downtime.
Studies show that 80% of Kubernetes outages stem from deployment errors, highlighting the need for effective release practices. From rolling updates to advanced methods like blue/green deployment, canary deployment, and A/B testing, each approach offers a different balance of speed, stability, and risk.
Observability is equally critical, as 65% of organizations adopting real-time monitoring report faster incident resolution. This guide explores Kubernetes deployment strategies, their trade-offs, and the role of observability in ensuring zero-downtime releases.
Key Takeaways
• Kubernetes offers multiple release methods, and choosing the right one determines whether updates are safe, scalable, and disruption-free.
• Rolling updates work for simple, stateless workloads, but they fall short when reliability, rollback speed, or user segmentation matter.
• Blue/green deployment enables instant rollback, canary reduces risk through gradual exposure, and A/B testing validates user experience before full rollout.
• Monitoring error rates, latency, and user impact in real time ensures deployment strategies deliver their promise of zero-downtime releases.
• The right choice varies by application risk level, infrastructure resources, and team maturity.
Why Advanced Deployment Strategies Matter
In the world of Kubernetes, the default isn’t always the safest. Many teams still rely solely on basic rolling updates, yet deployment-related downtime remains a common issue. This highlights a dangerous disconnect: teams are shipping code without the strategy or observability needed to prevent failure.
Basic approaches often fail to handle real-world complexity, which is why understanding K8s deployment patterns is essential. Advanced strategies like Kubernetes blue-green deployment offer safer alternatives by allowing teams to shift traffic only after confirming application health in production-like environments.
This section unpacks the limitations of basic rolling updates and explains why modern production environments demand more advanced, risk-aware deployment approaches.
Limitations of Basic Rolling Updates
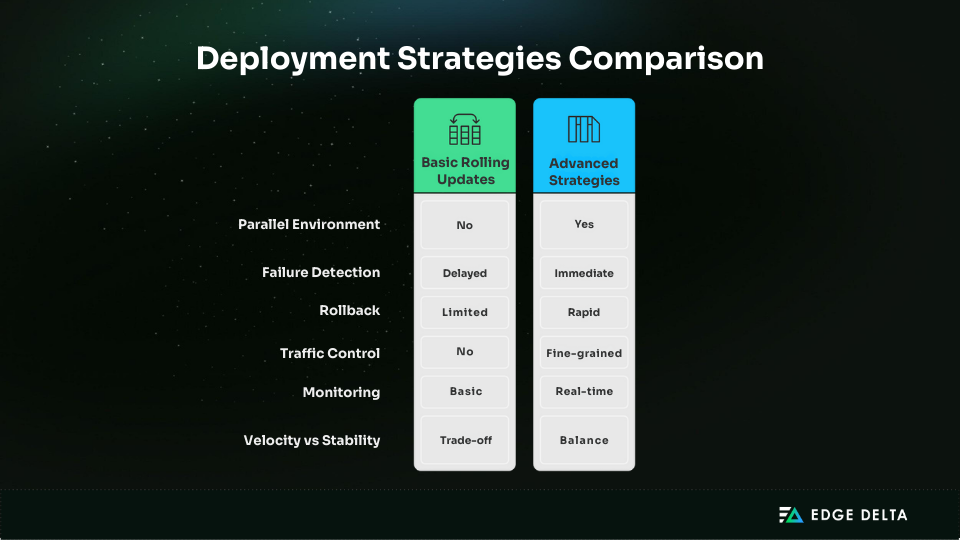
Rolling updates are Kubernetes’ default deployment mechanism. They replace old pods with new ones gradually to maintain availability. While simple and effective for many stateless workloads, rolling updates fall short in several critical ways:
- No parallel environment: There’s no isolated staging environment for validation. Any issue in the new version impacts live users immediately.
- Delayed failure detection: If a problem only appears under load or after prolonged uptime, rolling updates might fully deploy a broken version before it’s caught.
- Rollback limitations: Rolling back is slow and resource-intensive, often requiring manual intervention and lacking fine-grained control.
- No traffic control: All users are gradually exposed to the new version without segmentation or targeting.
These limitations mean rolling updates can lead to widespread user impact, especially in complex, stateful, or latency-sensitive applications.
Production Reliability Requirements
Modern production systems demand more than just high availability. They require reliability, even in the face of change. In high-stakes environments like fintech, e-commerce, and healthcare, downtime can result in:
- Revenue loss
- Customer churn
- SLA violations
- Security or compliance breaches
Production-ready deployment strategies must support:
- Rapid rollback
- Fine-grained traffic control
- Pre-production validation
- Staged or segmented exposure
Advanced strategies, such as blue/green deployment, canary deployment, and A/B testing, offer these capabilities, making them essential tools for maintaining reliability.
Release Velocity vs Stability Balance
Teams often struggle between shipping quickly and keeping systems safe. Basic rolling updates prioritize speed but risk stability. Advanced strategies solve this trade-off:
- Blue/green deployment delivers zero-downtime releases with instant rollback.
- Canary deployment gradually increases traffic exposure while monitoring impact.
- A/B testing validates user experience before scaling further.
These methods enable teams to move quickly without compromising reliability.
Monitoring and Observability Critical Requirements
Advanced deployment strategies only work if they’re backed by real-time, intelligent monitoring. Without proper observability, gradual rollout or traffic switching is essentially a matter of guesswork.
For every deployment strategy, teams must track:
- Error rates
- Latency and throughput
- User impact and conversion metrics
- Version-specific performance data
Monitoring tools should support version comparison, automatic anomaly detection, and alerts during rollouts. To make this possible, data normalization ensures telemetry stays consistent across environments.
Edge Delta, for example, enables unified observability across environments, allowing teams to confidently deploy, compare, and promote versions based on real metrics, not intuition.
Rolling Deployments: The Foundation
Rolling deployments are Kubernetes’ default strategy, which involves gradually replacing old pods with new ones to maintain availability. This approach is simple and effective for stateless workloads, but it comes with limits: no parallel staging environment, slow rollbacks, and limited traffic control.
A typical rolling update works by creating a new pod, waiting until it’s ready, then terminating an old one. The process is tuned using two key parameters:
maxSurge– how many extra pods can run during the update.maxUnavailable– how many pods can be offline at once.
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1For a stateless web service, this usually ensures smooth upgrades with minimal downtime. But for stateful systems, like databases, rolling updates can cause data mismatches or downtime spikes.
Readiness and liveness probes are critical. Without them, traffic may route to unready containers, leading to outages or false success signals. Key rollback triggers include rising error rates, degraded latency, or pods stuck in crash loops. Unified monitoring platforms detect these anomalies early, enabling safe reversions.
Rolling updates work best when applications are stateless, backwards compatible, and low-risk. For critical systems where regressions aren’t acceptable, blue/green or canary deployment approaches provide stronger guarantees.
Blue/Green Deployments: Zero-Downtime Releases
Blue/green deployments run two identical environments: one live (blue) and one idle (green). The new version is deployed to green, validated, and then traffic is switched in one step. This ensures instant rollback by reverting traffic to blue if issues appear.
A typical Kubernetes setup uses services or ingress controllers to switch traffic:
service:
selector:
app: myapp
version: green| Strengths | Limits |
|---|---|
| • Zero downtime cutover • Simple rollback by pointing traffic back • Clean separation of old and new environments | • Requires double the infrastructure • Database migrations remain tricky • Costly for large-scale systems |
The blue/green strategy shines for high-traffic apps and mission-critical releases where downtime isn’t acceptable. For gradual rollouts and safer validation with real traffic, canary deployments are usually the next step.
Canary Deployments: Gradual Risk Mitigation
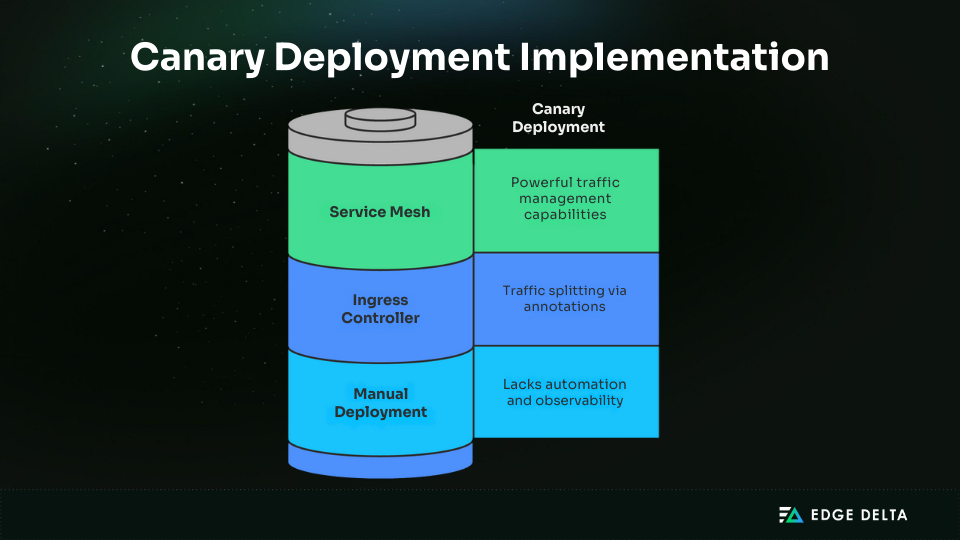
Kubernetes canary deployments release a new version to a small percentage of users before rolling it out to the full audience. This staged rollout limits risk, and ensures issues are surfaced early without affecting everyone.
In Kubernetes, canaries are typically managed using services, ingress controllers, or service meshes such as Istio and Linkerd, alongside fleet-based approaches to managing distributed telemetry pipelines.
These tools enable teams to gradually adjust traffic weights. For instance, they can send 5% of requests to the new version before scaling up to 25%, 50%, and eventually 100% once confidence grows.
| Strengths | Limits |
|---|---|
| • Exposes new code to real traffic and users • Limits the blast radius of failures • Rollout speed is fully adjustable | • Needs strong monitoring and alerting pipelines • Configuration is more complex than rolling updates • Database and stateful changes remain tricky to test incrementally |
Key metrics to track include:
- Error rates
- Request latency
- Resource consumption
- User experience signals
When anomalies appear, Kubernetes can instantly shift traffic back to the stable version, minimizing disruption.
Canary deployments are best suited for medium-to-large applications where risk reduction is a priority, but duplicating environments (as in blue/green) would be costly. They offer a balance: more safety than rolling updates, and less overhead than blue/green deployments.
A/B Testing Deployments: Data-Driven Releases
A/B testing extends canary principles by running two or more versions of an application simultaneously and directing user traffic between them. Unlike canaries, the focus is not just on stability. It’s about measuring user behavior, performance, and business impact in real time.
Traffic routing is usually managed through service meshes, feature flags, or API gateways. These tools enable fine-grained splits, such as sending 10% of users to version A and 90% to version B, or testing multiple variants simultaneously.
Metrics go beyond error rates and latency. Teams monitor conversion rates, engagement, and feature adoption to decide which version should become the default. Observability platforms integrate telemetry with business KPIs, ensuring data is actionable.
A/B testing works best when releases introduce significant feature or UX changes. It requires robust monitoring, statistical validation, and rollback automation. Done right, it blends engineering reliability with product experimentation.
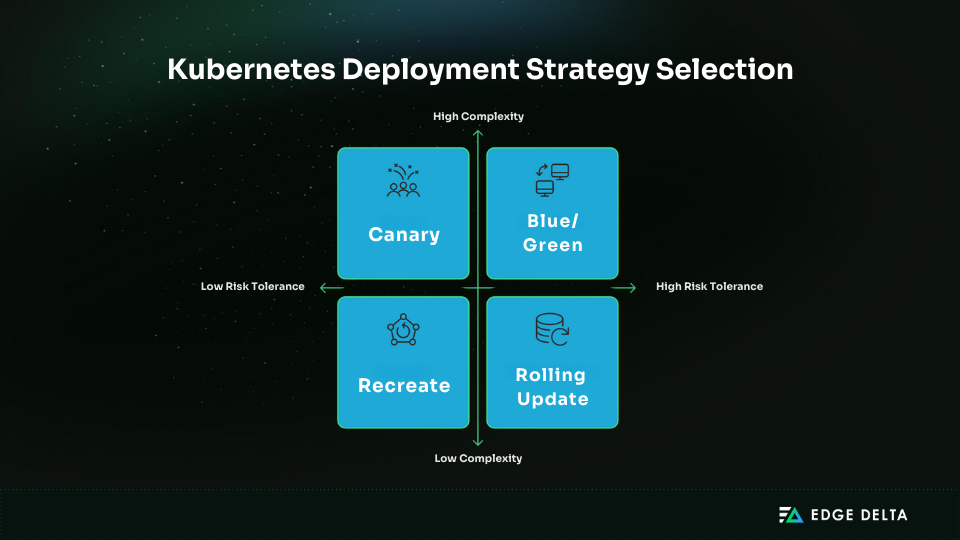
Deployment Strategy Selection Framework
Choosing the right Kubernetes deployment strategy isn’t just about technical feasibility; it’s about aligning with your app’s risk profile, infrastructure limits, and team maturity.
A survey found that nearly 48% of Kubernetes users struggle with tool selection and validation, highlighting the need for structured guidance. There’s no one-size-fits-all approach. Teams must weigh risk tolerance, resource constraints, observability depth, and operational readiness.
The next section presents a practical decision framework, including a comparison matrix and monitoring prerequisites, to help you select the best-fit strategy.
Risk Assessment and Strategy Matching
Risk tolerance is the primary axis for narrowing deployment strategy choices. Applications that support critical business functions, such as payment gateways or login services, demand strategies with rollback safety and minimal disruption potential.
In contrast, lower-risk workloads, such as internal tools or batch jobs, can tolerate simpler methods.
-
High-Risk Applications (e.g., public-facing APIs, production databases)
- Recommended: Blue/Green, Canary, Shadow
- Justification: Enable full testing, rollback, or non-user-visible validation
-
Moderate-Risk Applications (e.g., internal dashboards, microservices)
- Recommended: Rolling Update, A/B Testing
- Justification: Safe gradual rollout or segmentation-based testing
-
Low-Risk Applications (e.g., background jobs, dev tools)
- Recommended: Recreate, Best-Effort Rollout
- Justification: Tolerant of short downtime or service restarts
Matching risk to strategy helps limit the impact of failed deployments while optimizing rollout velocity and resource usage.
Resource and Monitoring Requirements Analysis
Each deployment strategy comes with unique infrastructure and observability demands.
Strategies like blue/green and shadow deployments need duplicate environments, doubling compute use. In contrast, canary deployments and A/B testing rely on fine-grained monitoring to validate behavior under partial traffic.
| Strategy | Resource Cost | Monitoring Requirements |
|---|---|---|
| Recreate | Low | Minimal (basic readiness checks) |
| Rolling Update | Medium | Health probes + service metrics |
| Blue/Green | High | Full-stack monitoring on both versions |
| Canary | High | Fine-grained metrics, latency, errors |
| A/B Testing | Medium–High | Business metrics + behavior analytics |
| Shadow | High | Request mirroring + backend tracing |
| Controlled Rollout | Medium | Automated anomaly detection |
Teams should evaluate whether their clusters can support duplicated environments and whether their observability stack can detect performance regressions in near real time.
Organizational Maturity Considerations
Beyond tooling, team maturity plays a central role. Simpler strategies like recreate or rolling updates can be managed by teams with basic Kubernetes skills, while advanced patterns like canary or shadow deployments often require experience with service meshes, ingress controllers, and automation tools.
| Maturity Level | Recommended Strategies |
|---|---|
| Beginner | Recreate, Rolling Update |
| Intermediate | A/B Testing, Controlled Rollout |
| Advanced | Blue/Green, Canary, Shadow |
Mature teams also implement CI/CD pipelines integrated with observability and rollback triggers. Without this level of integration, attempting complex deployments can introduce unnecessary risk and slow down release velocity.
Strategy Comparison and Selection Matrix
To simplify decision-making, the following matrix compares common strategies based on key criteria:
| Strategy | Risk Mitigation | Downtime | Complexity | Rollback Speed | Observability Needs |
|---|---|---|---|---|---|
| Recreate | Low | High | Low | Slow | Low |
| Rolling Update | Moderate | Low | Low | Medium | Medium |
| Blue/Green | High | None | Medium | Instant | High |
| Canary | High | None | High | Gradual | Very High |
| A/B Testing | Medium–High | None | High | Granular | High + Analytics |
| Shadow | Very High | None | High | Not applicable | Very High |
Use this comparison to select the most appropriate strategy based on your goals:
- Prioritize rolling updates for simple, zero-downtime releases.
- Use blue/green for instant cutovers with minimal risk.
- Apply canary when gradual exposure and automated rollback are needed.
- Opt for A/B testing when validating user behavior differences.
- Use shadow deployment for validation without user impact.
Selecting a Kubernetes deployment strategy is a multi-dimensional decision. Risk appetite, observability tooling, resource constraints, and team capabilities all factor into the right choice.
Many organizations begin with rolling updates and progressively adopt advanced techniques like canary or blue/green deployment as they mature. There’s no one-size-fits-all answer; adopting a flexible framework ensures you deploy safely, efficiently, and with confidence.
Monitoring and Observability for Deployments
Effective Kubernetes deployment observability rests on five pillars: essential metrics and KPIs, real-time monitoring and alerting, CI/CD pipeline integration, unified platforms, and automated decision-making. Together, these ensure that rollout decisions are based on live data.
Why does this matter? Modern Kubernetes deployments are only as reliable as the monitoring behind them. Real-time observability reduces risk, speeds recovery, and ensures that strategies like blue/green or canary deliver safely.
Every rollout should be measured against three categories of metrics:
- Application health: error rates (4xx/5xx), latency (p95/p99), throughput (RPS/QPS).
- Infrastructure health: pod status (CrashLoopBackOff, Pending), node utilization (CPU, memory, disk I/O), replica availability.
- Deployment events: rollout completion time, rollback triggers, and version performance.
Real-time visibility is critical. A delay in detecting latency spikes or rising error rates during a canary can escalate into widespread outages. That’s one reason many teams choose to leverage Telemetry Pipelines, which surface concerning patterns and trends in Kubernetes clusters while the data is still in flight.
When observability is done right, the benefits are clear. According to surveys, centralized monitoring cuts MTTR by 40% and saves 15 engineer hours per incident, while CI/CD visibility reduces disruption response time by 25%.
In short, a strong observability strategy makes Kubernetes deployment safer and more predictable, no matter which approach you choose.
Implementation Best Practices
Adopting advanced deployment strategies requires more than configuration. It demands planning, testing, and operational readiness.
- Planning and Testing: Define rollout goals, success criteria, and rollback triggers before release. Use readiness and liveness probes, automated integration tests, and smoke tests to validate updates.
- Rollback and Recovery: Always keep a known-good version available. Automate rollback with Argo Rollouts, and maintain backups for etcd and persistent volumes. In mission-critical systems, unplanned downtime can cost enterprises up to $300,000 per hour, making disaster recovery (multi-region clusters, failover) non-negotiable.
- Team and Continuous Improvement: Train teams on rollback procedures, document deployment ownership, and run game days to practice failure scenarios. Postmortems and metrics analysis reduce future failure rates. Teams that adopt continuous feedback loops improve MTTR by up to 50%.
With these practices in place, deployment strategies like canary or blue/green become not only safer but also repeatable and scalable.
Automated Deployment Strategies
Automation changes how teams release software, but its value depends on visibility. At the lowest maturity level, basic manual deployments lack both automation and observability, leaving teams blind to risks.
Observability addresses this problem, but rollouts are still slow and prone to human error. On the other end, automated deployments without observability create a false sense of speed.
Issues can scale just as fast as releases. The ideal model combines GitOps with real-time monitoring, where every change is version-controlled, auditable, and validated against live telemetry.
This pairing reduces human intervention, enforces consistency, and ensures rollouts advance or roll back based on actual performance data. In short, automation only reaches its full potential when it’s tightly integrated with observability.
Enterprise Deployment Strategy Patterns
At enterprise scale, deployment strategies must address additional layers of complexity such as multi-cluster rollouts, compliance requirements, and disaster recovery planning.
Large organizations often operate across regions or cloud providers, requiring consistent GitOps workflows and unified observability to avoid drift. Regulatory standards also make auditability and policy enforcement non-negotiable.
While this guide focuses on the fundamentals (rolling, blue/green, canary, and A/B testing), teams operating at a global scale should factor in governance and resilience patterns tailored to their environments.
Conclusion
Advanced Kubernetes deployment strategies are critical for modern Kubernetes environments. They minimize downtime, enable rapid rollbacks, and ensure that releases meet production reliability standards.
Still, these methods only deliver their full value when backed by strong observability. Monitoring error rates, latency, and user impact in real time turns each rollout into a controlled, low-risk process.
Without visibility, even the most sophisticated strategies introduce uncertainty. That’s where platforms like Edge Delta come in. By analyzing metrics, logs, and traces at the source, Edge Delta detects anomalies instantly. This gives teams the confidence to advance or roll back based on real data, not assumptions.
The path forward is clear: choose the deployment approach that fits your risk profile, and let tools like Edge Delta strengthen your observability strategy.
FAQs on Kubernetes Deployment Strategies
How do I choose the right deployment strategy for my application?
Match the strategy to your risk level and resources. Critical apps often need blue/green or canary for safe rollback, while lower-risk apps can rely on rolling updates or recreate.
When should I use blue/green vs canary deployments?
Use blue/green when you need instant rollback and zero downtime, but can afford duplicate environments. Use canary when you want gradual exposure of new code to real users, with strong monitoring in place to catch issues early.
How do I monitor Kubernetes deployments effectively?
Monitor error rates, latency, throughput, and resource usage in real time. A unified observability platform helps detect anomalies quickly and supports safe rollouts.
How do I implement canary deployments with proper monitoring?
Start with a small share of traffic on the new version, track performance and errors, and only increase traffic if metrics remain stable. Roll back immediately if issues appear.
What are the rollback procedures for different deployment strategies?
Rolling updates require redeploying the old version, which is slower. Blue/green deployment allows instant rollback by shifting traffic back. Canary rollbacks stop canary traffic, while A/B testing retires the weaker variant.
References

