


Sentiment analysis is widely used in 2025, yet its behavior in production often surprises teams. Expectations are shaped by polished demos and clean dashboards, while real results are shaped by ambiguous language, shifting context, and operational constraints.
Many organizations discover that high reported accuracy does not translate into dependable business outcomes. This gap rarely stems from broken models. More often, it comes from unrealistic assumptions about what sentiment systems can deliver in messy, real-world conditions.
Accuracy alone is the wrong lens. In practice, sentiment analysis is constrained by context, system design, cost, and tolerance for error far more than by benchmark scores. These systems function as probabilistic signals, not definitive judgments, and should be treated accordingly.
This article outlines what sentiment analysis can reliably deliver in 2025, where it breaks down, and how different approaches perform in production. It also examines cost at scale and offers guidance on deciding whether sentiment analysis belongs in your stack at all.
Key Takeaways
• Sentiment analysis is reliable for broad signals, not precise judgments. In production, outputs behave more like probabilities than definitive “truth.”
• Accuracy isn’t the main metric that matters. What matters more is how errors impact real decisions, especially when a mistake has consequences.
• Models don’t understand emotion or intent. They classify text based on learned patterns, which limits how well they handle nuance and context.
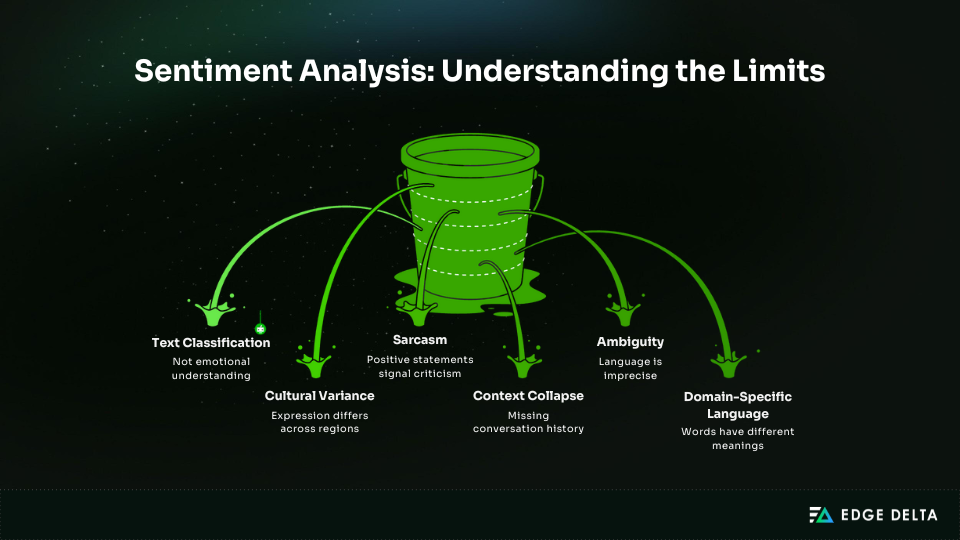
• Language ambiguity creates predictable failure modes. Sarcasm, mixed sentiment, cultural tone differences, and domain slang regularly break clean classification.
• Strong benchmark scores don’t guarantee real-world performance. Production inputs are noisy, labels are inconsistent, and language shifts over time.
• Transformers are the current standard, but not “set and forget.” Fine-tuning helps, but monitoring, retraining, and drift control are ongoing requirements.
• Sentiment pays off most when used for aggregation and trend detection. It’s strongest for high-volume feedback, early warning signals, and prioritization.
Introduction: Why Sentiment Analysis Is Still Misunderstood
Sentiment analysis seems simple until it meets real operational data. Teams often expect strong evaluation scores to translate into dependable results, but performance commonly drops once inputs become noisy, ambiguous, or inconsistent.
Production language rarely matches training data. Sarcasm, partial statements, domain-specific terms, and shifting intent are the norm, not the exception. These conditions stress even well-built models and reveal the gap between benchmark performance and operational reliability.
Accuracy alone is an incomplete measure of success. A model can score well in tests and still fail in production when context shifts or error tolerance is low. What matters most is how the system behaves under real constraints—not how it performs in isolation.
What Is Sentiment Analysis Really Doing Under the Hood?
Sentiment analysis systems are often described as interpreting intent, but in practice they perform a much narrower task. Understanding what these models actually do helps set realistic expectations around accuracy, failure modes, and business value.
Most production issues do not come from poor models. They come from misunderstanding the problem sentiment systems are designed to solve—and the limits imposed by language itself.
The Core Task Sentiment Models Are Solving
At a fundamental level, sentiment analysis is a text classification problem. Models assign labels based on learned statistical patterns rather than interpreting intent or meaning. Most systems classify polarity — positive, negative, or neutral. Some extend this to emotion categories like frustration or satisfaction. More advanced approaches use aspect-based sentiment, associating sentiment with specific topics within the same text. None of these approaches implies comprehension. The outputs are probability estimates derived from training data, not interpretations of human intent.
Ambiguity is unavoidable. Language is inherently imprecise and shaped by context, culture, and motivation. A single sentence can express praise and criticism at once, or change meaning depending on who says it and why. Sentiment models do not resolve this ambiguity. They estimate the most likely label given limited signals. In production, sentiment outputs should be treated as directional guidance rather than definitive judgment.
The Three Common Sentiment Outputs
Most sentiment systems in production fall into three output types, each aligned to different sentiment analysis use cases. In practice, these typically show up as the following:
- Polarity classification is the most common. It labels text as positive, negative, or neutral and is widely used for trend analysis and large-scale monitoring. It is fast and scalable, but it often collapses nuance into a single label.
- Emotion detection classifies emotional states such as anger, joy, or frustration. It can be useful, but it tends to be less stable because emotion categories overlap and labeling is often subjective.
- Aspect-based sentiment analysis ties sentiment to specific topics within the same text (for example, pricing vs support). It produces more actionable insights, but it requires cleaner data, stronger models, and higher operational costs.
The right output depends less on sophistication and more on the decisions the system is meant to support.
Why Language Is the Hard Part
Most systems classify polarity as positive, negative, or neutral. Some extend this to emotional categories such as frustration or satisfaction, while more advanced approaches use aspect-based sentiment to link sentiment to specific topics within the same text. None of these methods implies comprehension. Outputs are probability estimates derived from training data, not judgments about human intent.
Ambiguity is inherent to language. Meaning is shaped by context, culture, and motivation, and a single sentence can convey praise and criticism simultaneously or shift meaning depending on who says it and why. Sentiment models do not eliminate this uncertainty. They estimate the most likely label given limited signals. In production, sentiment should be treated as directional input — not a definitive verdict.
Sentiment Analysis Accuracy** in 2025: What the Numbers Actually Look Like**
Sentiment analysis accuracy is often treated as a fixed score, but in reality, it depends heavily on the task, data quality, and deployment context. Public benchmarks often reflect best-case results on clean, controlled datasets, whereas production systems rarely meet those conditions.
Real-world sentiment accuracy is shaped by noisy inputs, shifting language, and imperfect labels. To gauge performance, evaluate it by task and measure it in production, not just during training.
Baseline Accuracy by Task Type (Production Data)
When teams reference sentiment accuracy, they often quote lab benchmarks or vendor claims from AI sentiment analysis tools. Production reality looks different.
On live data, typical ranges look like this:
| Task Type | Typical Accuracy Range |
|---|---|
| Polarity (Positive / Neutral / Negative) | 82–88% |
| Emotion classification | 75–82% |
| Aspect-based sentiment | 78–86% |
| Transformer-based fine-tuned models | 91–95% |
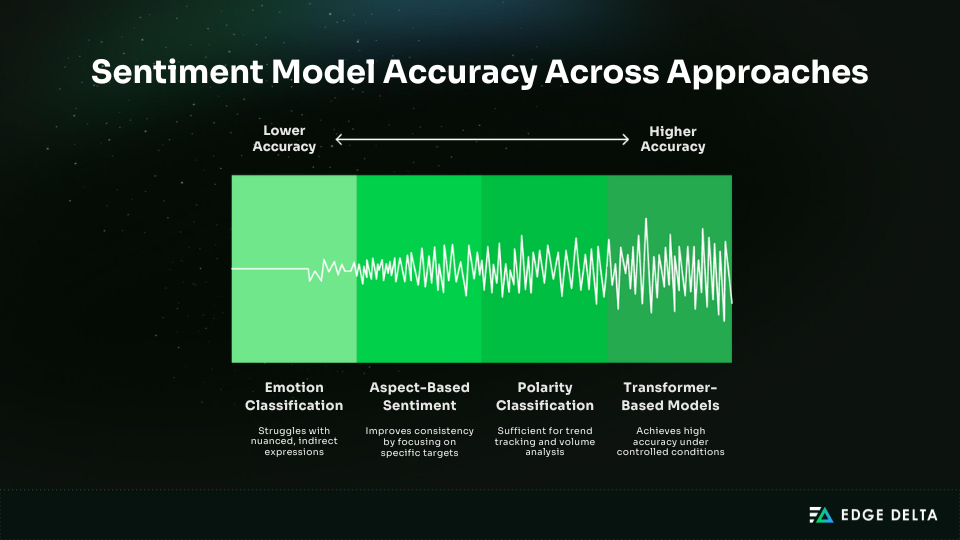
- Polarity classification (82–88%): Good enough for trend tracking and broad categorization. However, at high volume, even small error rates result in a significant number of mistakes.
- Emotion classification (75–82%): Usually lower because emotions overlap, expression is indirect, and cultural context varies. Subtle tone shifts are hard to capture as discrete labels.
- Aspect-based sentiment (78–86%): Often more consistent because sentiment is tied to a target (feature, topic, entity), which reduces ambiguity.
- Fine-tuned transformers (91–95%): Achievable in controlled conditions with stable language patterns and ongoing tuning. These numbers are best-case outcomes, not default expectations.
In reality, these figures reflect post-deployment performance. Without continuous domain tuning, accuracy degrades as language evolves.
Why Accuracy Plateaus in Real Systems
Sentiment accuracy plateaus because human language rarely resolves cleanly, even for people. Ambiguity is constant, and many statements are indirect, polite, incomplete, or open to multiple valid interpretations. Mixed sentiment adds another constraint.
A single message can praise one aspect while criticizing another, forcing models to compress nuance into a small label set. This is not a modeling flaw, but a mismatch between how language works and how classification systems are structured.
Label noise creates another ceiling. Training data is often annotated quickly or inconsistently, and borderline cases produce disagreement even among humans. Small shifts in labeling quality can push models toward probabilistic guessing rather than confident decisions.
Human disagreement is the final limit. In many sentiment tasks, humans do not agree much more than models do. Once a system approaches human-level agreement, gains become marginal and costly.
Accuracy vs Business Utility
Accuracy only matters when it supports a real decision. A sentiment model reporting 90% accuracy can still fail in customer experience or compliance use cases. In CX workflows, the remaining misclassified cases often contain the most emotionally intense interactions. Missing those signals leads to poor escalation, frustrated customers, and lost trust.
In compliance or risk monitoring, even small error rates may be unacceptable. A few false negatives can allow harmful or regulated content to pass through unnoticed. In these environments, probabilistic outputs must be paired with human review or additional controls.
In contrast, 80% accuracy is often good enough for trend analysis, product feedback aggregation, and early signal detection. These use cases rely on directional insight over time, not perfect classification of individual messages. Errors average out, and the cost of a single mistake is low.
There are also scenarios where 95% accuracy is still insufficient. Automated enforcement, legal review, and safety-critical systems cannot rely solely on sentiment models. In these cases, sentiment analysis should assist human decision-makers rather than replace them.
The most important question is not how accurate the model is, but what happens when it is wrong. That answer should determine how sentiment analysis is deployed, constrained, or avoided altogether.
Model Types Compared: Rules, ML, Deep Learning, and Transformers
Sentiment analysis models are often described as a linear progression, where newer approaches automatically replace older ones. In practice, enterprise sentiment analysis systems select models based on accuracy, cost, explainability, and operational risk.
Legacy approaches persist because they fit specific constraints rather than because they outperform newer techniques. Understanding real-world trade-offs helps teams avoid unnecessary complexity and unrealistic expectations.
Rule-Based Sentiment Systems
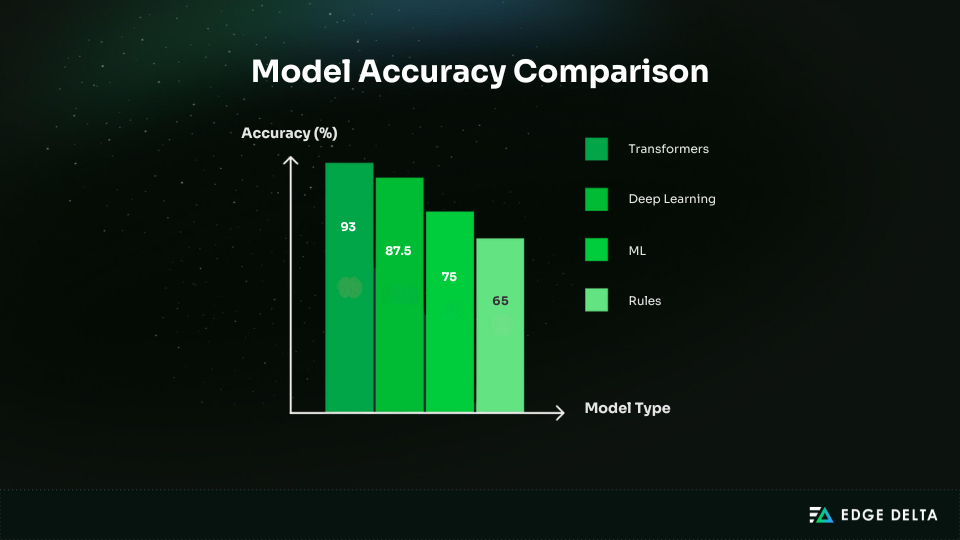
Rule-based systems use predefined keywords, phrase lists, and scoring rules rather than learned language patterns. In production, accuracy typically lands around 60–70%.
| Strengths | Limitations |
|---|---|
| • Predictable and explainable behavior • Easy to adjust without retraining • Low cost and simple deployment (no labeled data required) | • Weak with sarcasm, indirect language, and shifting context • Narrow coverage and poor nuance • Rule sets become harder to maintain as exceptions pile up |
Classical Machine Learning Models
Classical ML models typically reach 70–80% accuracy in production. They rely on engineered features like n-grams, term frequency signals, and lexicons rather than learned representations.
| Strengths | Limitations |
|---|---|
| • Lower compute costs than deep learning • Easier to debug than neural models • Viable in small-data environments | • Requires domain expertise and iterative feature tuning • Feature sets age quickly as language changes • Sensitive to imbalance and labeling noise |
Deep Learning Models****
Deep learning improves accuracy by learning patterns directly from data instead of depending on handcrafted features. When trained and maintained well, production performance often lands around 85–90%.
| Strengths | Limitations |
|---|---|
| • Better generalization than classical models • Less manual feature engineering • Strong performance on messy inputs | • Requires large labeled datasets and more expertise • Higher compute costs • Regular retraining becomes mandatory |
Transformer Models (Current Standard)
Transformers are the current production standard. When fine-tuned on domain data, they often reach 91–95% accuracy, which is why they’ve replaced earlier approaches in many environments.
| Strengths | Limitations |
|---|---|
| • Strong pretrained understanding of context and tone • Faster adaptation with less labeled data • Shorter experimentation and iteration cycles | • Not plug-and-play without tuning • Performance degrades without monitoring and retraining • Ambiguity and sarcasm still remain |
Cost of Sentiment Analysis in Production
Production sentiment analysis costs are driven by scale, operating model, and ongoing maintenance, not accuracy alone. Pilots may look cheap, but costs climb once it becomes a continuous workload in feedback, support, or monitoring systems.
Understanding cost requires looking beyond per-query pricing to total operational impact over time.
API-Based Sentiment Analysis Costs
API-based sentiment analysis appears inexpensive at first. Most commercial APIs charge approximately $0.002 to $0.01 per 1,000 tokens, depending on the model and service tier.
At low volumes, these costs are negligible, which makes APIs attractive for pilots, proofs of concept, and low-traffic applications.
As usage increases, costs scale linearly:
- 1 million tokens per month: $2 to $10
- 10 million tokens per month: $20 to $100
- 100 million tokens per month: $200 to $1,000
***Note: ***API rates and billing units change often (and vary by model and volume). Treat these as typical 2024–2025 ranges and revalidate current pricing before finalizing cost estimates.
At moderate usage, costs often stay manageable, but this is also the stage where teams typically expand scope. They start analyzing more sources, reprocessing historical data, or running sentiment multiple times across different pipelines.
At a larger scale, spending becomes a noticeable operational expense, especially once you account for traffic spikes, retries, batch reprocessing, and parallel sentiment passes.
API pricing only covers usage, not engineering time, text preprocessing, validation, or downstream storage and analytics. For teams running continuous sentiment analysis across customer feedback, social media, or support logs, these operational costs can add up over time.
That “downstream” piece becomes real when you’re indexing and querying high-volume text data for dashboards, investigations, and retention. If you’re using Elasticsearch under the hood, it’s worth understanding how to keep it efficient with performance and cost optimization tips.
This cost accumulation is why early cost modeling matters. Sentiment analysis is rarely a one-off query. In production, it behaves more like a recurring service.
Self-Hosted Model Cost
Self-hosting sentiment models replace per-token fees with infrastructure and staffing costs. GPU infrastructure is usually the most visible expense. Even modest transformer workloads need it for training and retraining, along with CPUs and storage for inference, logging, and monitoring.
As requirements grow, costs rise quickly, especially when teams need higher throughput, lower latency, and stronger availability guarantees.
Key ongoing costs tend to fall into three areas:
- Infrastructure spend: GPUs for training and retraining, plus CPU and storage capacity to support inference, logging, and monitoring at scale.
- Training and retraining cycles: Fine-tuning is rarely a one-time event. Language evolves, product terminology changes, and data distributions shift over time. Each retraining cycle consumes compute resources, labeled data, and validation effort.
- Engineering overhead: Teams must maintain deployment pipelines, model versioning, monitoring, fallback logic, and incident response. Sentiment models require observability, alerting, and rollback strategies. The teams that scale these systems smoothly usually distinguish between checking known failure modes and investigating unknown ones.
At very high volumes, self-hosting can be cheaper than APIs in raw compute terms. For most teams, it is only justified when scale, data sensitivity, or customization needs outweigh the operational complexity.
Total Cost of Ownership (TCO) Comparison
Total cost of ownership depends more on scale and operating context than on model architecture.
At a small scale, API-based approaches usually have the lowest TCO. With only a few million tokens per month, APIs are typically the cheapest option because there is no infrastructure to manage and minimal operational overhead.
As volume grows into the tens of millions of tokens per month, costs start to converge. This is where break-even points emerge:
- API costs increase predictably with usage
- Self-hosted costs begin to amortize once setup and infrastructure are reused
- Teams with stable workloads and in-house expertise may find self-hosting viable, especially if models support multiple applications
At a very large scale, self-hosting often becomes cheaper in direct compute terms. These environments also benefit from deeper customization and stronger data ownership. However, savings only appear if engineering and retraining costs are tightly controlled.
There is no universal break-even point. TCO depends on volume, staffing, risk tolerance, and operational maturity. A solution that looks cheaper on paper can become more expensive if it increases maintenance burden or slows delivery.
Architecture Patterns for Sentiment Analysis Systems
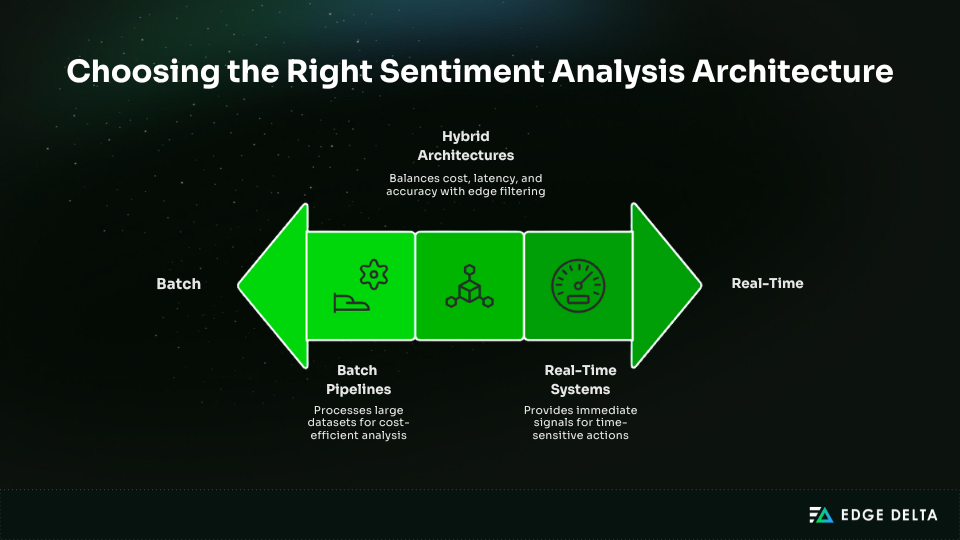
Sentiment analysis isn’t one-size-fits-all. The right architecture depends on latency needs, data volume, risk tolerance, and how insights drive decisions. Some teams optimize for low-cost batch analysis, while others need real-time signals for immediate action.
Many teams operate somewhere in between. The architecture patterns below reflect the most common production approaches, each optimized for different trade-offs between latency, accuracy, scalability, and operational complexity.
Batch Sentiment Analysis Pipelines
Batch sentiment analysis pipelines are designed for high volumes of text that do not require immediate response. Batch workflows can also benefit from pipeline discipline around parsing, enrichment, and downstream reliability, especially when multiple sources feed the same reports.
Common use cases include product reviews, customer surveys, and market research datasets. In these workflows, data is collected over time and processed on a schedule rather than in real time, letting teams prioritize cost and throughput over low latency.
Batch pipelines typically follow a standard flow:
- Ingest text from storage systems
- Normalize and clean inputs
- Run sentiment models in bulk
- Store aggregated results for analytics and reporting
Because timing is flexible, teams can often use larger, more accurate models without affecting user experience. Errors are also easier to manage. Misclassifications tend to impact trends rather than individual decisions, which lowers risk.
Batch processing works well for longitudinal insight, such as tracking sentiment shifts after product changes or campaigns. It also pairs naturally with periodic retraining, since historical data can be reprocessed when models improve.
For many organizations, this architecture delivers the best balance of accuracy, cost control, and operational simplicity.
Real-Time Sentiment Analysis Systems
Real-time sentiment analysis systems prioritize low latency for use cases where sentiment needs to trigger immediate action. It’s commonly used for things like live chat support, social listening and monitoring, and content moderation workflows.
In these environments, sentiment signals drive rapid decisions like escalation, issue flagging, prioritization, and routing. Tight latency constraints often require millisecond-scale responses at scale, limiting model complexity and raising infrastructure costs.
Once sentiment triggers escalation, the hard part is quickly understanding what changed and why it spiked. That’s where AI-assisted troubleshooting can speed up response and reduce the manual digging teams do during incidents.
How real-time sentiment is typically used:
- Live chat: detects frustration or disengagement early so agents can intervene
- Social monitoring: identifies negative spikes or emerging trends as they happen
- Moderation: acts as one signal among many to prioritize human review, not make final decisions
Real-time systems carry a higher risk profile because errors affect individual users and public-facing interactions. As a result, these deployments require guardrails, fallback logic, and continuous monitoring.
In practice, real-time sentiment is most effective as a supporting signal rather than a single source of truth. Speed enables responsiveness, but it can also amplify mistakes if context and error tolerance are not carefully managed.
Hybrid Architectures
Hybrid sentiment analysis architectures combine multiple processing layers to balance cost, latency, and accuracy. They are common in systems that need both scale and responsiveness without fully committing to either batch or real-time extremes.
How hybrid systems are typically structured:
- Edge filtering: lightweight rules or simple models run close to the source to remove obvious noise, reduce volume, and prioritize high-risk or high-value text
- Centralized inference: larger, more accurate models run in shared environments where compute can be pooled, updated, and monitored consistently
- Feedback loops: human review and downstream outcomes are routed back into evaluation and training workflows
This structure reduces downstream cost while preserving accuracy. Edge filtering prevents low-signal data from overwhelming central systems, while centralized inference simplifies governance, logging, and version control.
Over time, feedback loops are what make hybrid systems effective. They surface blind spots, detect domain shifts, and expose labeling gaps that offline testing often misses.
Hybrid architectures work well at scale because they reflect how sentiment systems actually behave in production. Sentiment analysis is not a one-shot prediction problem. It is an evolving system that improves only when the architecture supports learning, correction, and adaptation.
Where Sentiment Analysis Fails (And Why)
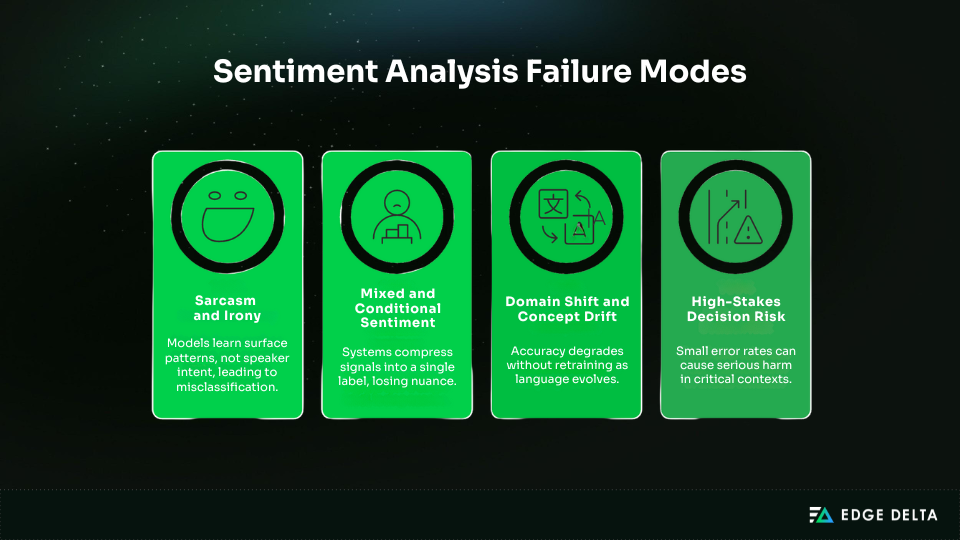
Sentiment analysis performs well in controlled settings, but real-world language introduces failure modes that models still cannot fully resolve. These are not edge cases. They are structural limits tied to how language works and how sentiment systems are designed. Understanding these failures is essential for setting expectations and avoiding misuse in high-impact decisions.
Sarcasm and Irony
Sarcasm and irony are difficult because they rely on shared context and intent rather than literal wording. A sentence may appear positive while meaning the opposite. Most models learn surface patterns, not speaker intent.
Without tone, conversation history, or cultural cues, systems default to literal interpretation. Subtle or domain-specific sarcasm is especially challenging, leading to systematic misclassification in reviews, social media, and support chats. As a result, sarcasm-heavy domains often perform worse than benchmarks suggest.
Mixed and Conditional Sentiment
Mixed sentiment is common. A message may praise one aspect while criticizing another. Conditional sentiment adds complexity, where approval depends on future outcomes.
Most systems compress these signals into a single label, losing nuance. Aspect-based approaches help but do not fully solve the problem. Mixed sentiment increases disagreement even among human annotators, making consistent labeling difficult.
Domain Shift and Concept Drift
Language changes continuously. New terminology, products, and behaviors reshape how sentiment is expressed. Without retraining, accuracy degrades gradually and often goes unnoticed.
Periodic retraining is required to maintain relevance. Teams that treat sentiment models as static assets risk silent failure rather than a visible breakdown.
High-Stakes Decision Risk
Using sentiment analysis as a sole decision input is risky in compliance, safety, legal, or enforcement contexts. Even small error rates can cause serious harm.
Sentiment outputs are probabilistic signals, not judgments. They work best as supporting inputs combined with rules, metadata, or human review. In high-risk scenarios, sentiment should inform decisions, not make them.
When Sentiment Analysis Actually Delivers ROI
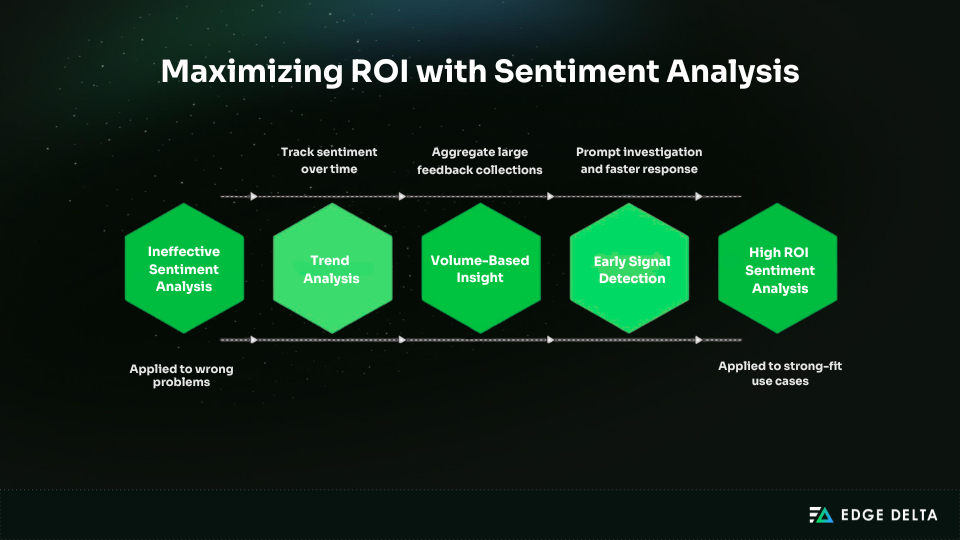
Sentiment analysis creates value only when it is applied to the right problems. ROI depends less on model accuracy and more on how sentiment outputs are used, aggregated, and acted upon.
This section outlines where sentiment analysis reliably pays off and where it tends to underperform.
Strong-Fit Use Cases
Sentiment analysis delivers the strongest return when it is used to identify patterns rather than evaluate individual statements.
- Trend analysis is a natural fit. When sentiment is measured consistently over time, small classification errors matter less than overall direction. Teams can track how perception shifts after launches, pricing changes, incidents, or support improvements. The real value is in comparing periods, not labeling every sentence perfectly.
- Volume-based insight is another strong use case. Large sets of reviews, surveys, tickets, or social posts contain more feedback than teams can read manually. Sentiment analysis turns that volume into signals for prioritization. Aggregation reduces individual errors and surfaces recurring pain points and positive drivers.
- Early signal detection often delivers the fastest ROI. Language often shifts before hard metrics: complaints show up before churn, and frustration rises before ticket volume spikes. Sentiment can flag issues early, prompting quicker investigation and response.
In practice, teams rarely need perfect sentiment classification to see value. What matters more is spotting unusual shifts in tone or volume quickly, then routing the right issue to the right owner. This is where pairing sentiment with anomaly detection can be a big unlock.
Weak-Fit Use Cases
Sentiment analysis performs poorly when decisions require certainty at the individual level. Misclassifying a single customer message or employee interaction affects real people directly, with no aggregation to absorb error.
- Legal and medical decisions are especially weak fits. These domains demand precision, transparency, and accountability that sentiment models can’t reliably deliver. Sentiment can support triage, but outcomes should always require human oversight.
- Low-volume datasets also limit ROI. Small samples produce unstable results, and fine-tuning is rarely cost-effective. In these cases, manual or qualitative analysis often delivers better insight at lower risk.
Production Readiness Checklist
Sentiment analysis often performs well in demos but fails quietly in production. The gap is rarely the model itself. It is whether the system is ready to operate under real data, real costs, and real consequences.
This checklist defines the minimum requirements for sentiment analysis to deliver ongoing value rather than become shelfware.
| Area | What “ready” looks like |
|---|---|
| Data quality | • Inputs reflect real usage (misspellings, emojis, abbreviations, incomplete sentences) • Text normalization is consistent across ingestion sources • Data quality is measured and monitored so accuracy metrics stay meaningful |
| Domain labeling | • Labels are defined in domain terms, not generic polarity assumptions • Annotation guidelines match how sentiment is interpreted in practice • Label definitions are reviewed as the domain evolves |
| Accuracy thresholds | • Minimum thresholds are defined per use case and risk level • Evaluation includes error analysis, not just a single aggregate score • Downstream use is aligned with the cost of being wrong |
| Cost monitoring | • Per-request and monthly costs are tracked and reviewed • Usage growth is monitored to prevent silent cost escalation • Retries, reprocessing, and parallel passes are accounted for |
| Human-in-the-loop review | • Review targets low-confidence or high-impact predictions • Feedback is captured and routed back into evaluation workflows • Human review is for risk control and learning, not random sampling |
| Retraining cadence | • Retraining follows a defined schedule tied to drift indicators • Training data, labels, and thresholds are periodically revalidated • Model degradation is treated as an operational risk, not a surprise |
Editor’s note*: This checklist determines whether sentiment analysis succeeds or becomes shelfware. Models rarely fail in isolation. Systems fail when production readiness is assumed instead of enforced.*
How to Decide If You Should Deploy Sentiment Analysis
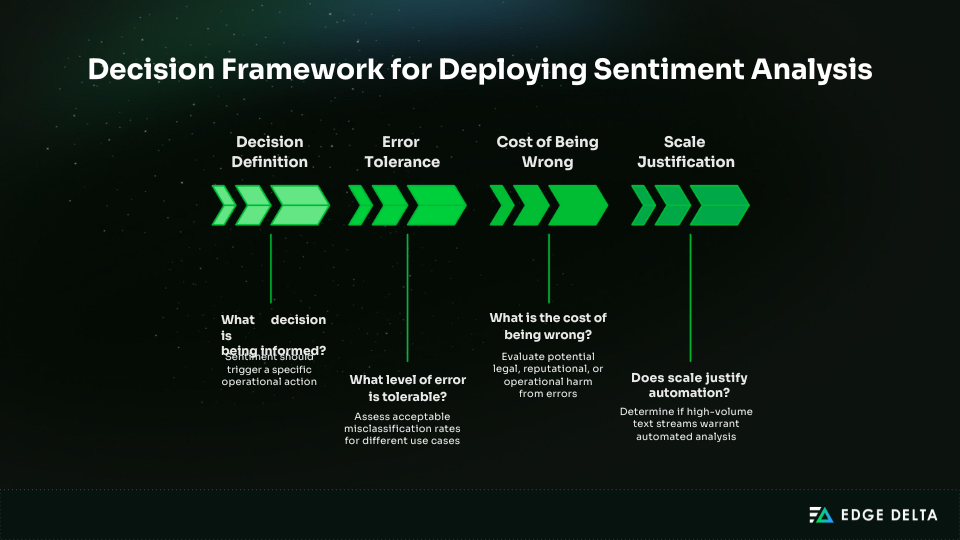
Not every workflow benefits from sentiment analysis. Before selecting models or architectures, teams must decide whether sentiment is the right tool for the problem. This framework helps evaluate whether deployment will deliver value or introduce unnecessary complexity.
Decision Framework
Sentiment analysis should inform a clear operational decision. If the output does not change behavior or prioritization, it becomes a passive metric.
Consider the following questions:
- What decision is being informed? – Sentiment should trigger a specific action, such as ticket prioritization, risk escalation, or trend detection.
- What level of error is tolerable? – Aggregate trend analysis can absorb noise. Individual-level actions, such as moderation or enforcement, cannot tolerate frequent misclassification.
- What is the cost of being wrong? – False positives may cause minor disruption. False negatives in compliance or safety workflows can lead to legal or reputational harm. Risk determines whether guardrails or human review are required.
- Does scale justify automation? – Sentiment analysis delivers the most value on high-volume text streams that humans cannot review efficiently. Low-volume decisions often benefit more from manual analysis.
When these questions are answered clearly, the deployment decision becomes straightforward. Sentiment analysis is a conditional tool that works best when decisions are defined, risk is managed, and scale demands automation. When such conditions are not met, it adds cost and false confidence without a meaningful return.
The Future of Sentiment Analysis (2025–2027)
The future of sentiment analysis from 2025 to 2027 is less about major leaps in accuracy and more about practical refinement. Teams are prioritizing reliability, reduced ambiguity, and governance-ready systems. Progress is driven by operational needs rather than attempts to model human emotion.
Key developments shaping sentiment analysis include:
- Multimodal sentiment analysis combines text with voice and video cues like tone, pacing, pauses, and facial expressions to add context. It’s especially useful for customer support, sales calls, and moderation. While still complex, improving tools are making adoption easier.
- Domain-adaptive transformers are moving from one-time fine-tuning to continuous, domain-specific adaptation. This helps models learn industry language and stay accurate as terminology evolves, but teams still need to watch for drift and bias.
- Explainable sentiment models are increasingly important as sentiment scores drive decisions. Methods like phrase attribution, confidence scoring, and uncertainty indicators help with auditing and trust. They don’t eliminate errors, but they make them easier to spot.
- Regulation and transparency are becoming bigger pressures as sentiment analysis impacts moderation, hiring, and customer treatment. Expectations are rising for accountability and clear documentation, including how models work, what data they use, and their limits.
Overall, the future of sentiment analysis is disciplined rather than optimistic. Success will come from governance, explainability, and careful integration into workflows.
Conclusion: Sentiment Analysis Is a Tool, Not a Truth Engine
Sentiment analysis is often treated as a window into how people truly feel, but it’s more limited than that. It produces probabilistic signals from language patterns that can inform decisions, not deliver the truth. Most failures happen when teams treat those outputs as definitive.
Accuracy alone is an incomplete metric. A model that performs well in testing can still break down in production when context shifts, data quality declines, or error tolerance is misunderstood.
What matters is how accuracy aligns with the decision being made and the consequences of being wrong. In many workflows, directional insight is sufficient. In others, even small error rates are unacceptable.
Return on investment depends on scale and intent. Sentiment analysis creates value when it summarizes large volumes of language, surfaces trends, or detects early signals humans would miss. It delivers little value for individual judgments or low-volume data.
Finally, architecture and cost matter as much as model choice. APIs, infrastructure, retraining, and engineering effort compound over time. Successful sentiment systems are disciplined pipelines, not one-off features.
Used carefully, sentiment analysis can yield insights. Used carelessly, it creates false confidence. The same discipline applies across AI-powered tooling. Edge Delta’s AI Teammates are built around this principle — automating specific, well-defined tasks like incident triage and security monitoring rather than attempting to replace human judgment wholesale.
Frequently Asked Questions
How accurate is sentiment analysis in 2025?
Sentiment accuracy varies in real-world settings because nuance, sarcasm, and mixed emotions are still hard to interpret. Even strong models remain context-dependent, and accuracy is usually measured against human labels that are inconsistent. Since annotators agree only about 80% of the time, systems should be judged by use-case fit and not by benchmarks alone.
Is sentiment analysis reliable for customer support decisions?
Sentiment analysis can help customer service by tracking customer mood, spotting negative trends, prioritizing tickets, and monitoring overall experience. However, it’s less reliable for individual messages, since context, sarcasm, and domain language are easy to misread. It works best alongside human review and other analytics, not as a standalone decision-maker.
Do I need to train my own sentiment model?
You don’t always need to train from scratch. Pretrained models often perform well for broad tasks, but fine-tuning on domain data helps when language is specialized or nuanced. The choice depends on your domain, data, and error tolerance, and fine-tuning usually improves accuracy for domain-specific decision support.
How much data is required for acceptable accuracy?
There’s no single data threshold for “good” accuracy. Performance depends on task complexity, language variation, and domain specificity, but larger, well-labeled datasets usually improve generalization. General tasks often benefit from thousands of examples, while nuanced domain work may need tens of thousands. Smaller datasets can still work with the right model choices and human-in-the-loop review.
Is sentiment analysis worth the cost for small teams?
Sentiment analysis can be worth it for small teams when it helps spot patterns in large or growing text volumes like reviews or surveys. The cost (API fees or maintenance) should match the volume and impact. If volume is low or nuance matters, manual review is often better. It works best as trend detection that supports human judgment, not a replacement for it.
References

