

Data pipelines help automate data flow from different sources, such as databases, virtual machines, Kubernetes clusters, APIs, or streaming platforms, to destinations. It ensures data quality is always at its highest. The pipeline processes this raw data into a usable format and sends it to other storage or analytics platforms.
Whether it’s customer behavior data or market trends, data pipelines connect systems and allow businesses to navigate their data systems more efficiently. In this article, learn more about data pipelines, how they work, and the tools used to implement them.
Want Faster, Safer, More Actionable Root Cause Analysis?
With Edge Delta’s out-of-the-box AI agent for SRE, teams get clearer context on the alerts that matter and more confidence in the overall health and performance of their apps.
Learn MoreKey Takeaways:
Data pipelines are vital for businesses to ensure operational efficiency and facilitate faster, more accurate data transfer, processing, and analysis.
Observability pipelines, often called telemetry pipelines, offer a centralized view of a system’s internal state through telemetry data.
Each type of data pipeline provides businesses with options designed for specific use cases and data analysis requirements.
Observability pipeline tools offer various monitoring, orchestration, and visualization features so organizations can streamline data workflows seamlessly and ensure data quality.
Data Pipeline Definition
Data is a vital driving force behind many business decisions nowadays. According to a Fortune 1000 and global data and business leaders survey by Wavestone, 59.5% of business leaders use data to drive business innovation.
Data pipelines help facilitate the smooth flow of data to ensure businesses can transfer, process, and analyze data faster and more accurately. One common type of data pipeline is an observability pipeline.
- Observability Pipeline: Also known as a telemetry pipeline, an observability pipeline collects logs, metrics, and traces from different sources. It then processes the data in real-time, helping users transform, enrich, filter, and analyze data in flight. From there, it routes data to different destinations: archive storage, an observability application, or another tool.
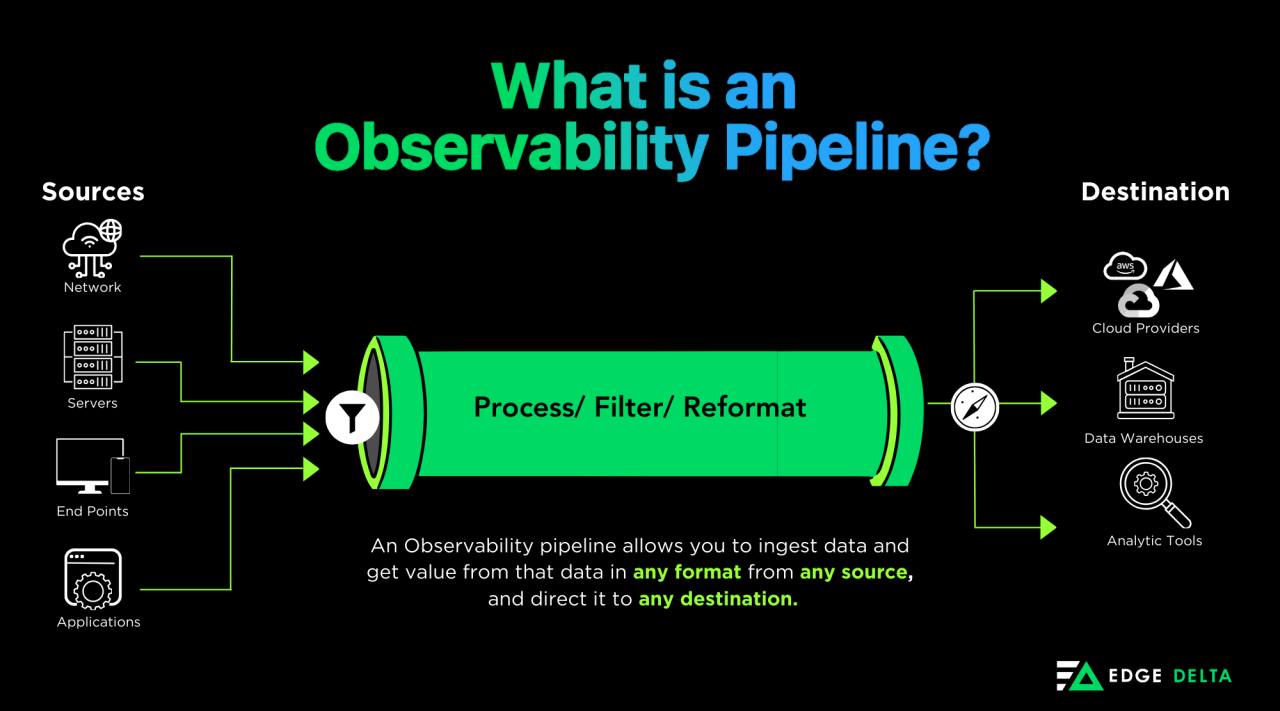
Artificial intelligence (AI) and machine learning (ML) algorithms can run in a pipeline to analyze patterns, detect anomalies, and provide insights that traditional log analysis tools can’t. This ongoing evolution of log analysis with AI and ML can help businesses ensure data pipeline efficiency and develop future tools.
IT Teams, DevOps, Application Developers, and even business analysts often use observability data pipelines to stay on top of their systems. Various tools and technologies are employed in creating observability pipelines, including:
- Apache Kafka
- Apache Spark
- Edge Delta
- Airflow
Designing efficient data pipelines helps organizations maintain data quality and make informed decisions. In the next section, learn more about the architecture of an observability pipeline.
Understanding the Mechanism and Architecture of Data Pipelines
A data pipeline works similarly to a water pipeline, delivering water from a source to an output or storage. It starts with collecting data and then moving it into a data storage, analysis application, or sometimes, a data sink.
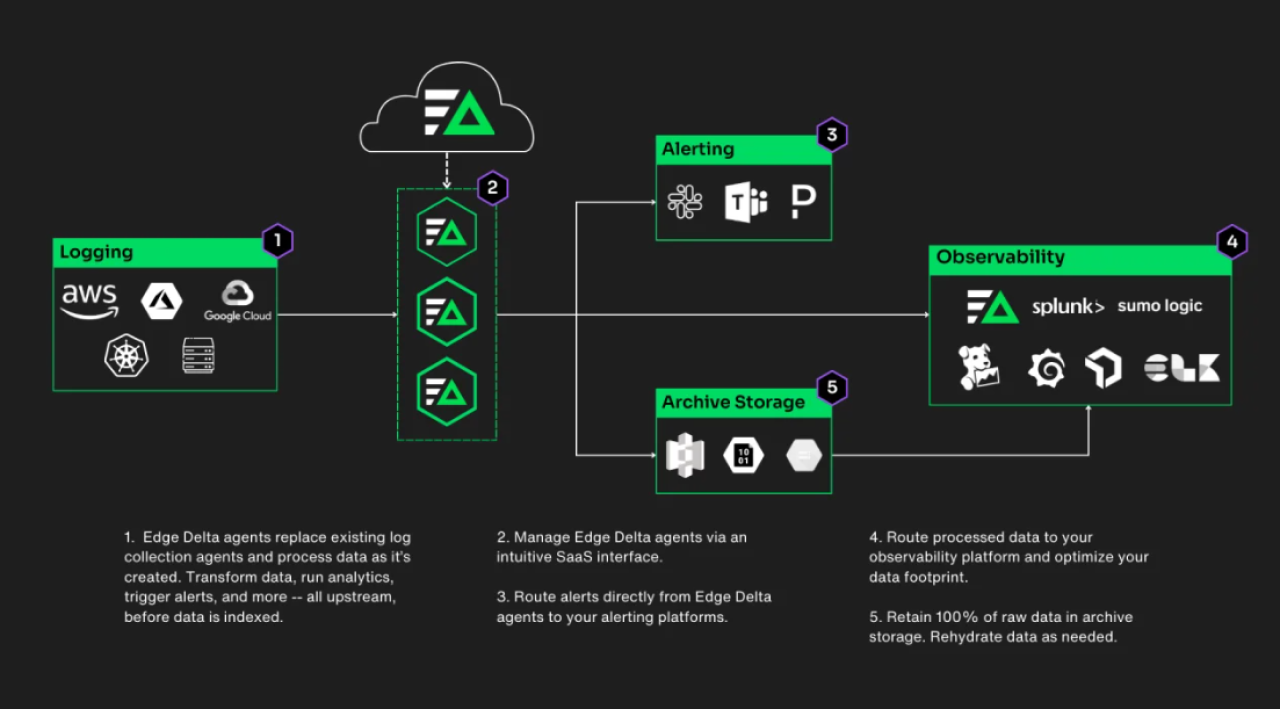
Observability pipelines, such as Edge Delta’s, consist of three parts:
- Data input
- Data processing
- Data output
Here’s an example of an observability pipeline and some of the tools used for each stage:
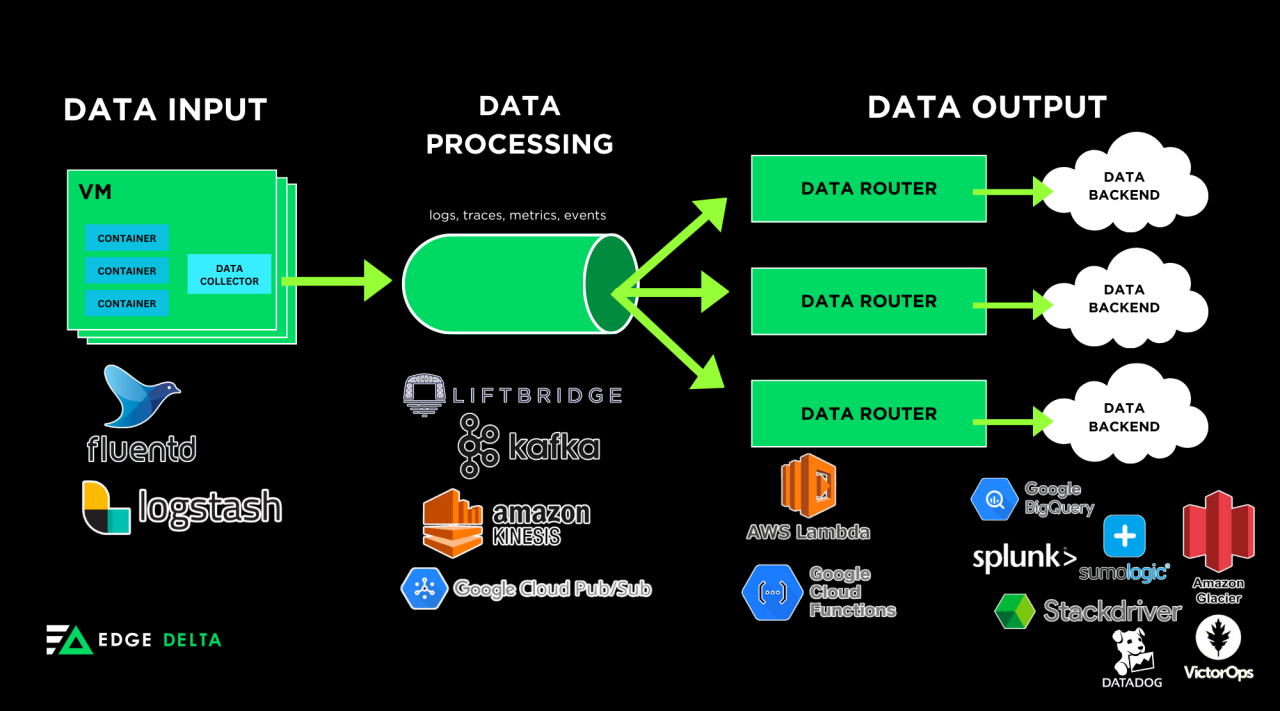
The stages of observability pipelines are the following:
Data Input – Extracting Data from the Source
The beginning of a data pipeline architecture is the source of the data. The data input stage involves extracting data from data sources and then forwarding it to the pipeline for further processing. Sources include:
- Compute resources (servers, Amazon EC2 instances, Kubernetes clusters)
- Content delivery networks (CDNs)
- Data warehouses
- File systems
- APIs
- Data streams
- IoT devices
Data Process – Transforming Data for Analytics or Storage
Data transformation uses computing functions or processors to transform the raw data from sources. These processors include:
- Filters
- Functions for shaping or transforming data
- Log-to-metric converters
- Log-to-pattern nodes
- Enrichment
- Data masking
By applying various processors, organizations can control the data’s size and format, which enhances the efficiency of the organization’s analytics and contributes to cost savings. The strategic use of processors can significantly reduce observability and monitoring costs by 40-60%.
Data Storage – Where Data is Routed
Data storage represents the endpoint of the data pipeline where processed data is stored for future use. Common storage destinations include:
Observability platforms
Storage targets
Alerting tools
Observability platforms support monitoring and troubleshooting, storage targets facilitate compliance or data rehydration, and alerting tools notify teams directly.
Organizations can achieve significant cost savings by routing data to different destinations. For example, the background screening company Fama employed Edge Delta to reduce the volume of data they indexed to Datadog. As a result, Fama cut their Datadog bill by 60%.
Similar to the example above, having a well-designed data pipeline seamlessly integrates data collection, transformation, and storage processes. Engineers need to know what data pipeline to use to design the pipeline that will work for their team.
Note:
Data storage in pipelines is vital in streamlining data processing, so selecting the most appropriate storage tool is crucial. Having proper data storage can also help reduce latency.
Exploring the Different Types of Data Pipelines
Organizations can employ various pipelines to ensure seamless data collection, processing, and analysis. These data pipelines can vary depending on what the team needs. Here are some of the most common types of data pipelines:
Batch Processing Pipelines – Best for Large-Scale Data Handling
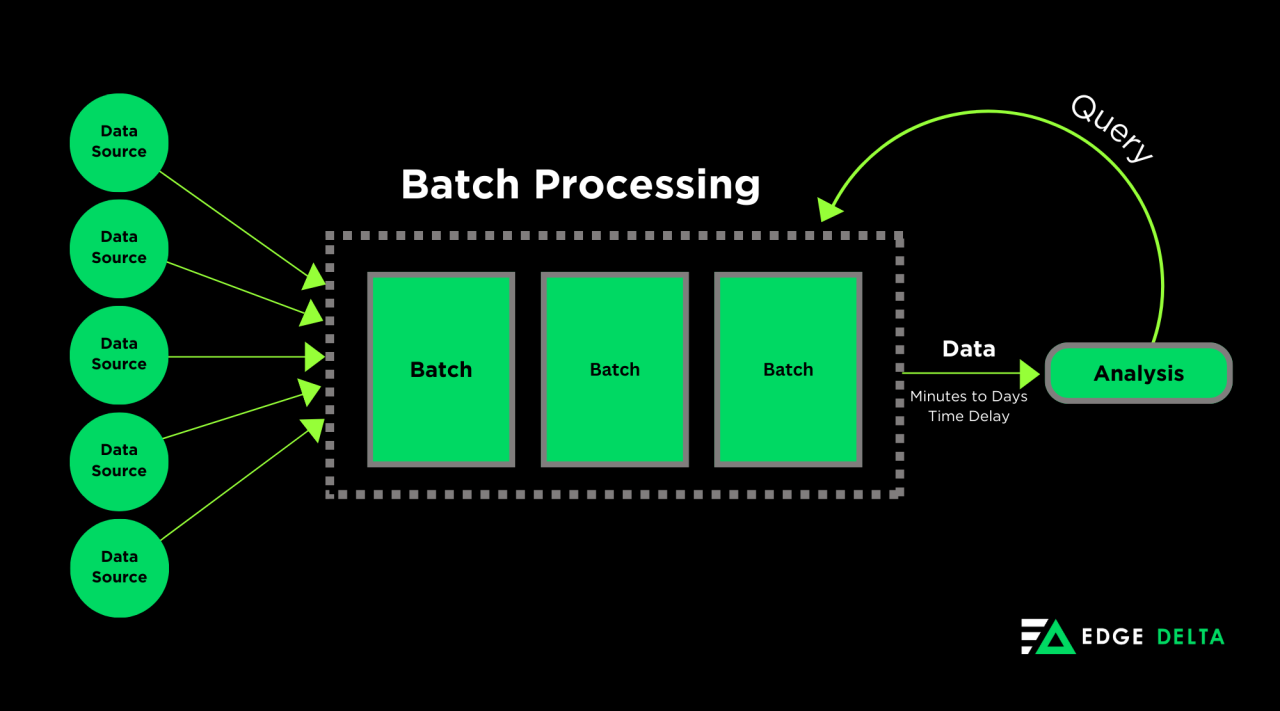
Batch processing pipelines transfer large amounts of data in batches regularly. Organizations use these channels to extract data from sources, apply operations, and transfer it to the destination later.
Unlike real-time pipelines, batch processing operates at scheduled intervals, with execution times ranging from minutes to a few hours or even days. These pipelines are commonly employed for traditional analytics, utilizing historical data to inform decision-making processes.
Note:
Data and ETL pipelines are often used interchangeably, but ETL is a specific type of data pipeline characterized by a sequential process of extracting, transforming, and loading data. It is often associated with Batch Processing Pipelines.
Real-Time Data Pipelines – Best for Instant Insights on Data
Real-time or streaming data pipelines process data constantly in near real-time, often within seconds or even milliseconds. These pipelines are very useful in scenarios that require continuous data ingestion and updating:
- Metrics
- Reports
- Summary statistics
One example of the use of real-time analytics is financial stock markets. In such markets, data must be live-streamed, so streaming data pipelines can help these organizations receive up-to-date operational information, respond swiftly, and make informed decisions.
Cloud-Native Data Pipelines – For those Looking for Flexible Data Processing
Cloud-native data pipelines use cloud technologies to transfer and process ingested data. Compared to on-premise alternatives, they provide:
- Robust infrastructure
- Higher scalability
- Improved cost-efficiency
Cloud-native pipelines became game-changers in helping software developers and data engineers streamline their workflows. They help use the cloud infrastructure to make modern development practices more scalable and flexible.
This type of pipeline integrates with cloud platforms so that developers can automate processes such as software delivery from the code changes to its deployment.
Note:
Organizations must implement robust security measures when implementing cloud-native data pipelines. By doing this, they can protect sensitive information and maintain the integrity of their data flow.
Open-Source Pipelines – Cuts Costs for Businesses
Open-source data pipelines offer a cost-effective alternative solution for commercial organizations regarding data pipelining. Because they use open-source tools, organizations can utilize them at no cost. This gives users more flexibility in editing the source code. That said, customers sacrifice ease of management and performance when they use open-source tooling.
An example of an open-source tool is Apache Kafka, which also offers free pipeline development services. However, one downside of using this type of data pipeline is that it needs an expert to do the job.
Did You Know?
Open-source pipelines are backed by collective knowledge and contributions from different communities. Because of this collaborative approach, resolution to issues is more accessible, updates are regularly made, and the pipelines can be adaptable in diverse cases.
On-Premises Data Pipelines – Great for Finance and Healthcare Services
On-premise data pipelines run on the organization’s local servers. They don’t rely on cloud services, unlike cloud-native pipelines. Some industries, like finance and healthcare, choose on-premises pipelines to ensure data security because of the belief that cloud service provider servers can be risky.
They process data and store those data on local hardware where it can be easily accessed by team members who need it.
Understanding these types of data pipelines can help organizations pick out what tools they need and how they would design their data pipelines. We will look at some actual use cases of data pipelines in the next section.
Real-World Use Cases and Examples for Data Pipelines
Observability pipelines are employed by many businesses worldwide, including big companies such as Netflix and Samsung. They help different teams parse, route, and enrich data efficiently to ensure that only high-quality data reaches their consumers.
The following are some of the most popular uses of Observability Pipelines:
Cost Cutting for Organizations
Because observability can become more expensive as time passes, companies seek solutions to reduce spending. Over the past three years, log data has grown five times on average. This growth can be attributed to different factors such as:
- Cloud migrations
- APIs
- Containerized applications
- Microservices
Observability pipelines such as Edge Delta’s can help organizations become more cost-effective by allowing them to push data upstream. Through this, they have more control over the size of their data footprint.
Performance Monitoring for E-commerce Platforms
Observability pipelines can help monitor several aspects of an e-commerce platform. An organization can identify bottlenecks, optimize its website’s performance, and give its users a better experience.
Data pipelines can help these e-commerce platforms collect:
- Page load times
- Transaction processing
- Server response time metrics
Grafana and Prometheus are the most popular tools for visualizing and analyzing such metrics.
Log Aggregation and Analysis for Media Streaming
Log aggregation and analysis are two benefits of observability pipelines, especially for media streaming organizations. Using data pipelines, organizations can collect and analyze logs from:
- Streaming servers
- Content Delivery Networks (CDNs), and
- User interactions.
Through this, they can offer a more personalized user experience, optimize content delivery, and troubleshoot issues.
For example, Netflix employed Apache Druid to power their real-time analytics. Using logs from user devices, Netflix’s data team can quantify how the users’ devices handle browsing and playback. Once these logs are collected, they feed them to Apache Druid to understand user behaviors.
Organizations are looking for a more unified solution to understand what is happening inside their systems so they:
- Act as quickly as possible
- Reduce downtime
- Cut down costs
There are various tools for data pipelines. Learn more about these tools in the next section.
Tools for Data Pipelines
Choosing the best data pipeline tool for your organization should be taken seriously. Data pipelines facilitate easy access to data analysis and help you automate your data workflows seamlessly.
Here are some of the best data pipeline tools for 2024:
1. Edge Delta’s Observability Pipelines – Best Observability Pipeline Overall

Edge’s Delta’s Observability Pipelines offers an easy-to-use, comprehensive visual tool for organizations to monitor their system. The platform efficiently analyzes and optimizes data routing so that businesses can reduce their spending.
Features:
- Point-and-click interface (Visual Pipelines)
- Reducing costs by summarizing and/or trimming loglines
- AI/ML to detect anomalies and organize logs into patterns
- Easy standardization of data
- 20+ Built-in Processors to control data
Edge Delta makes it easy for organizations to have a better view of what is currently happening in their system and improve data quality and usability. Its point-and-click interface allows users to easily manage their data pipelines without going through many processes.
Overall, they are an excellent solution for building, testing, and monitoring observability visually.
2. Apache Airflow – Best for Logging and Monitoring

Apache Airflow is an open-source orchestration platform that helps monitor and schedule workflows, giving organizations more flexibility in their data pipelines. The platform prioritizes observability and features robust logging mechanisms for comprehensive monitoring of data pipelines.
Features:
- User-friendly interface
- High scalability
- Extensive architecture
- Built-in monitoring and alerting
- Active community
Apache Airflow is one of the market’s most well-known observability pipeline tools. The platform’s community provides open-source workflow orchestration, valuable resources, and collaboration opportunities.
3. Datadog Observability Pipelines – Best for Protecting Sensitive Data

Datadog’s Observability Pipelines help organizations simplify migrations and monitor data delivery from any source to any destination, including on-prem locations. It also lets users adopt new technologies at their own pace, which includes automatically parsing, enriching, and mapping data to the correct schema while protecting sensitive information.
Features:
- Control data volume
- Simplified data routing and migration
- Ability to redact sensitive data
- Single control plane monitoring
Datadog is an excellent observability pipeline platform because it easily integrates with other tools. It allows the organization to route their data where they want it to go. While a few reviews might say that the learning curve for Datadog is steep, it remains a popular choice for observability pipelines in the market.
4. Splunk Data Ingest Actions – Best for Filtering or Masking Data in Splunk

Splunk Observability Cloud helps users extend the functionality of the traditional Splunk Enterprise deployment. Through the Splunk Observability Cloud, users can enable the integration of metrics and traces with logs. This ability to integrate metrics gives organizations better infrastructure visibility and reduces monitoring solutions.
Users of Splunk Observability Cloud can also leverage Splunk ingest actions. This feature helps them reduce costs by masking, filtering, or otherwise processing data before it’s indexed in Splunk.
Features:
- Route data to Amazon S3
- Obfuscate data for data protection
- Create, preview, and deploy pipelines
- Mask or filter data
Splunk observability cloud is an excellent option for businesses to respond to outages promptly. It’s ingest actions feature helps customers do so while controlling costs.
5. Apache Kafka – Best for Real-Time Data Streaming

Apache Kafka is an open-source event streaming platform that helps enable high-performance data pipelines, analytics, integration, and critical applications. Kafka supports various industries with its capabilities, such as scalability, permanent storage, and high availability.
Features:
- High scalability
- Website activity tracking
- Built-in stream processing
- Connect to various tools
- High throughput
A vast user community with abundant online resources backs Apache Kafka’s ecosystem. Kafka’s platform also includes client libraries in various languages and a rich array of open-source tools, which makes it an excellent option for many organizations.
Final Thoughts
Data pipelines, especially observability pipelines, have become a massive part of data infrastructures. They provide businesses insights into potential issues or any errors that might be happening inside the system.
Observability pipelines are also vital to different teams handling telemetry data and giving them a centralized view of their system. By mastering the architecture of data pipelines and how to design them, organizations can have more leverage on their data. Through this, they can make more informed decisions and operate as efficiently as possible.
FAQs About Data Pipelines
What is a simple example of a data pipeline?
One example of an industry that uses data pipelines is the financial industry, especially the stock market. Stock markets often employ real-time or streaming data pipelines to make quick decisions.
Is ETL a data pipeline?
ETL is a type of data pipeline that stands for the extract, transform, and load process. It is associated with the batch data pipeline, which focuses on preparing raw data for storage and later use. Business analytics and other data analysis processes often use ETL.
Why Do We Need Data Pipelines?
Data pipelines are essential for organizations to gain insights into their systems and make informed decisions. A data pipeline is crucial in maintaining the lifeblood of business intelligence.