


Unless logs in your services are CAPTCHAs, they are voluminous, lengthy, repetitive, and constantly streaming. Logs inherently offer far too much information than could be fully processed by a person or even a team of “eyes on glass.”
This characteristic makes them an extremely good fit for more advanced analysis techniques. Machine learning is getting faster, more accurate, and more capable each day, and the arguments against utilizing it in monitoring and observability are dwindling. Having real-time stream processing coupled with sophisticated anomaly detection can be a powerful resource for any DevOps, Security, and SRE team – far exceeding the capabilities of people.
Those capabilities have been engineered into Edge Delta’s Automated Observability to be out-of-the-box, allowing teams to analyze 100% of their data at the source while abstracting manual configurations away from engineers. Removing these barriers makes it reasonably attainable for machine learning to work for you in your infrastructure.
Here are three recent cases that show the benefits of the Edge Delta users embracing their inner cyborg.
1. Log4Shell
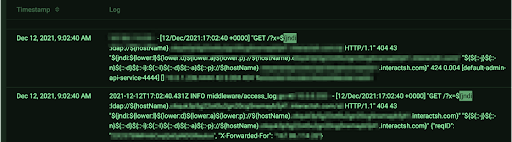
The log4j zero-day RCE vulnerability with the highest possible severity score (10/10) is currently top of mind for many in our community. The Edge Delta engineering team confirmed our platform is not vulnerable and was unaffected. However, there certainly were attempts from bad actors to utilize the exploit.
Edge Delta uses an algorithm developed and optimized in-house to identify various clusters and patterns with log data in real-time. No specific engineer has to define schemas, parse statements, or regexes initially – that part is entirely automated. The value of this capability compounds as code changes, new versions of services get deployed, or external data feeds deviate.
In this case, the algorithms detected the never-before-seen attempts being made to our infrastructure and alerted our team within 79 seconds. The powerful part here is that our engineering team did not have to try to predict this vulnerability and then come up with the alert logic for certain conditions. Being prophetic just isn’t possible for the wide range of potential security or operational production issues. The alternative – a human trying to manually look through 100,000 events per second – is not feasible. By utilizing real-time anomaly detection, our engineers don’t need to see the future or read at a rate of a trillion words per minute.
2. Credential Stuffing
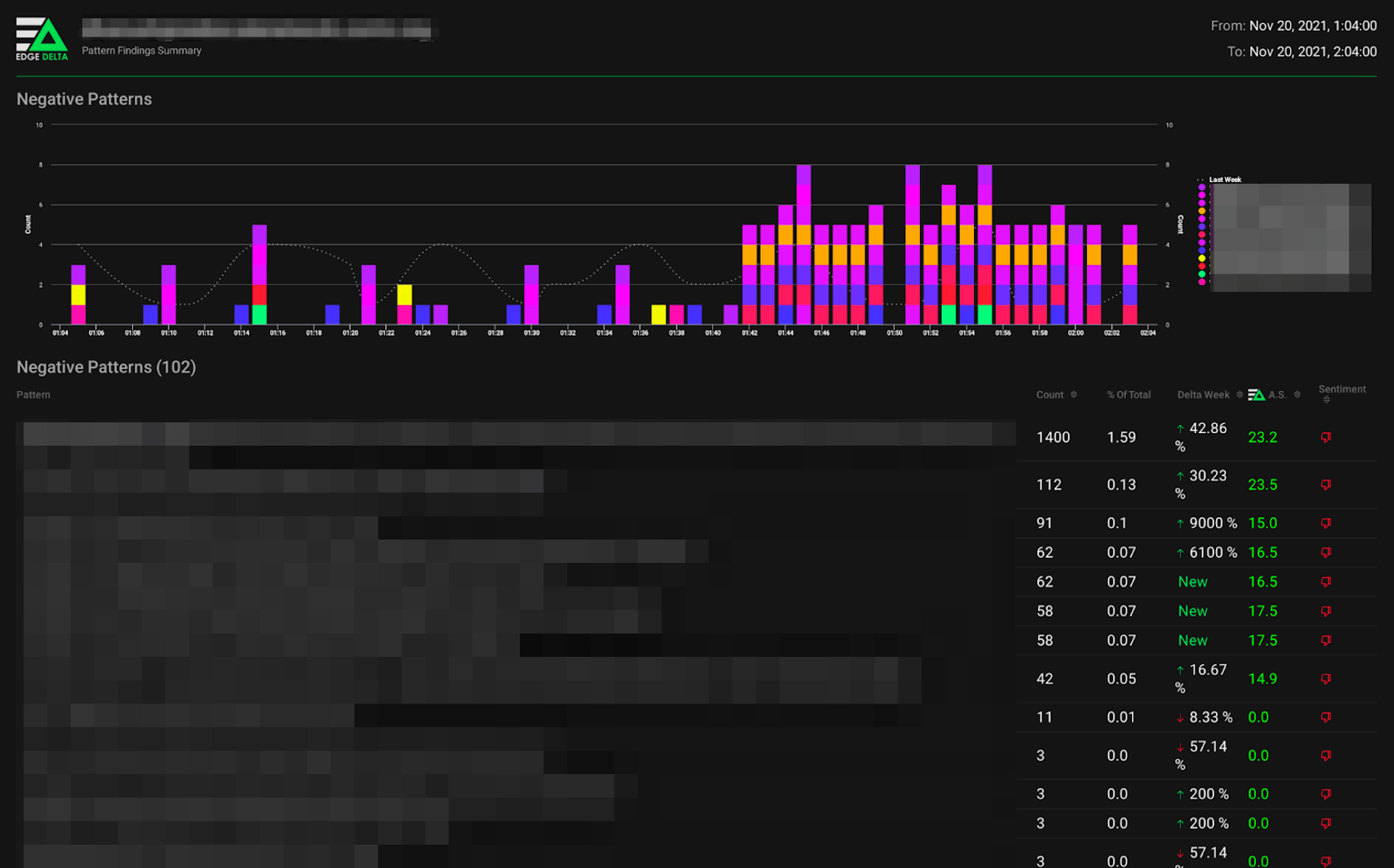
Credential stuffing is the method of capturing a pair of credentials (username/password) through a leak, phishing, or man in the middle attack, and using the combination in an attempt to log in to other systems. Though not completely perfect, multi-factor authentication (MFA) is an effective tool to protect against credential stuffing. All users should use MFA across their mission-critical services.
Traditional Security Incident and Event Management (SIEM) tools likely have a rule that catches accounts with multiple consecutive failed login attempts followed by success. Although these rules can be extensive, they’re still quite rigid, and the conditions and logic are again required to be defined ahead of time. This rigidness leaves traditional SIEMs well suited to solve yesterday’s tactics and techniques, but inadequate for new ones.
This was the case with a services provider that recently prevented a credential stuffing attack using Edge Delta. Here, Edge Delta caught a drastic increase in login attempts within one of the provider’s customer environments. The increase deviated significantly from historical user behaviors. Though a SIEM rule might have caught this specific instance, the most interesting part was that the incident was not detected with a manual rule set by simple logic. Instead, Edge Delta’s machine learning saw drastically different data resulting from suspicious user behavior and correctly identified the anomaly.
This example shows that even for new tactics and techniques, Edge Delta’s machine learning can identify indicators of compromise in real-time, then package up the correlated events into an easily digestible finding report for our organic brains.
3. Auto-remediation of Internal Tools
Auto-remediation is the concept of infrastructure, technology, or services being able to self-heal or fix other critical systems when they are not functioning or performing correctly. This concept is useful when prioritization issues or use of third-party technologies make it unfeasible to fundamentally fix the root cause of the problem within the source.
When should you implement auto-remediation? Instances where an alert is fired and a person is summoned to perform a fairly repetitive, mundane, manual task are excellent candidates. The resulting benefits are increased operational efficiency and availability, less burnout and toil for the engineers, and more robust and performant services.
Using machine learning to understand that something needs to be auto-remediated can be far more proactive and dynamic than setting manual thresholds that must be tuned and updated constantly.
Our engineering team used a tool with third-party components internally that was wildly valuable when functioning correctly. However, it seemed to require one or two manual interventions every week. Since it had third-party components, we couldn’t access the source to fix the root cause. As the intervention was quite mundane and repetitive, the team easily implemented auto-remediation by combining Edge Delta’s machine learning with AWS Lambda. Edge Delta detects whenever the tool isn’t functioning correctly and triggers a simple AWS Lambda function to auto-remediate the issue. Setting up this function resulted in significantly less manual work and toil for our engineering team.
In the end, the golden rule is that if machine learning and automation solve more problems than they create, it’s a net benefit. As these capabilities become more advanced, that net benefit is too significant for DevOps, Security, and SRE teams to ignore. It’s fast, it’s sophisticated, and it never sleeps.



