


Load balancing plays a crucial role in optimizing resource utilization and minimizing latency in high-traffic environments, making it essential for building scalable and reliable distributed systems.
Traditional load balancing strategies — like round-robin and least-weighted distribution — are simple and effective mechanisms for distributing traffic across system components. However, these approaches fall short when a more deterministic data-to-destination relationship is necessary.
Edge Delta’s Node-to-Gateway Pipeline architecture, for example, requires that identical node-level metrics are routed to the same Gateway Replica in order to accurately perform cluster-wide aggregations while minimizing data shuffling and coordination overhead.
To solve this challenge, we turned to an affinity-based routing approach that leverages consistent hashing with bounded loads to deterministically route node-level data into our Gateway Pipelines. In this post, we’ll explore what consistent hashing is, why we implemented the “bounded loads” enhancement, and how this algorithm enabled affinity-aware telemetry routing at scale.
Why Traditional Load Balancing Falls Short
Before diving further into load balancing strategies, let’s quickly review how our Gateway architecture works.
Edge Delta’s Gateway Pipeline is a Kubernetes-native pipeline solution that provides cluster-wide aggregation, filtering, and sampling. Gateway Pipelines deploy as a ReplicaSet in a Kubernetes cluster, and work by ingesting node-level data collected by our Node Pipeline agents. This allows teams to generate cluster-level insights at the Gateway before it reaches downstream platforms, which is critical for monitoring and troubleshooting at scale.
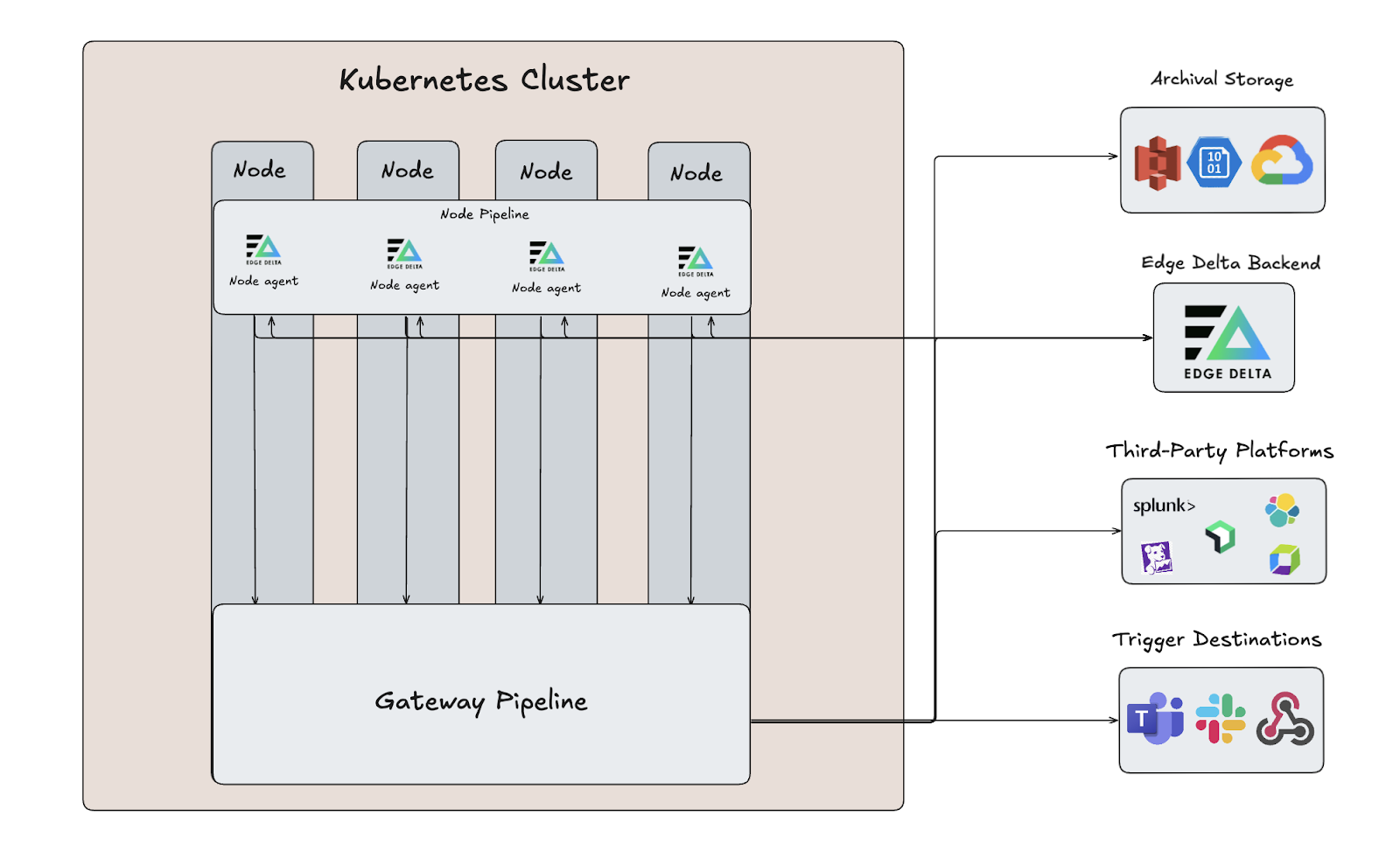
To understand the importance of affinity-aware routing — which is a method of distributing requests to specific destinations based on pre-defined mappings or “affinities” — let’s first consider how a traditional load balancing approach like round robin would fare when routing node-level metrics in our Node-to-Gateway architecture.
Take a key metric like cpu.usage, which provides crucial insight into system behavior. Understanding resource usage at both the node and cluster level is critical for identifying and remediating incidents.
A round robin approach will distribute node-level CPU metric data across available Gateway Replicas in a sequential manner, ensuring a balanced distribution of traffic. But if more than one Gateway Replica exists, the cpu.usage metrics collected by each Node agent will be routed to different ones. In order to aggregate these node-level data into a single, cluster-level cpu.usage metric, the Gateway Pipeline requires all relevant metrics be sent to the same Replica for processing — which this approach doesn’t support.
This issue will affect all cluster-wide operations, including filtering, sampling, deduplication, and patternization. If all the relevant data doesn’t arrive at the same Gateway Replica, the resulting aggregations will be incomplete.
One potential solution is to create a hash based on the relevant data — in this case, the cpu.usage metric — to create the necessary consistent routing relationship. A simple hashing algorithm like Hash(metric.name % # of Gateway Replicas) provides affinity-aware routing, but creates problems with key remappings when nodes are added or removed, leading to load spikes and cache invalidation.
Consistent Hashing: an Affinity-Based Solution
Instead of pursuing a simpler hashing approach, we implemented affinity-based consistent hashing for our Node-to-Gateway communication.
Consistent hashing is a hashing strategy that minimizes the number of required key remappings when the number of nodes changes. Instead of mapping keys directly to nodes, consistent hashing maps both keys and nodes to points on a circle (often referred to as a “hash ring”). When a key arrives, it is assigned to the first node in clockwise order on the ring. This way, adding or removing a node only affects a small subset of keys — a property that’s extremely valuable in distributed systems, where elasticity is common.
By implementing consistent hashing, we were able to ensure all relevant data was mapped to the correct Gateway node, enabling accurate cluster-wide aggregations.
Consistent Hashing with Bounded Loads
While consistent hashing is a powerful, affinity-based solution that reduces key remapping, it also introduces a new challenge — imbalanced load distribution. Under a consistent hashing approach, some nodes may end up responsible for significantly more keys than others, especially in small or unevenly distributed systems. This can create bottlenecks that significantly impact overall Gateway performance.
To address this issue, we adopted the consistent hashing with bounded loads algorithm, as described in this Google Research Report. In short, this algorithm maintains all the benefits of consistent hashing — minimal disruption when the topology changes and deterministic key placement — while also ensuring each Gateway Replica receives close to the average load across all replica instances. It works by augmenting the hash ring with a backpressure-aware routing mechanism. If the ideal node (i.e., the first node clockwise from the key’s hash) is full or above its load threshold, the algorithm searches forward in the ring for the next node under the threshold. This bounded search ensures fairness and predictability, while preserving affinity as much as possible.
By using a consistent hashing with bounded loads approach, we’re able to minimize key movement on Gateway changes, guarantee load balancing within a configurable bound, and preserve deterministic routing for identical node-level metrics to the Gateway Pipeline. This allows our users to benefit from the global context our Gateway Pipelines offer, without worrying about traffic imbalances or inaccurate processing.
Conclusion
Load balancing is critical for ensuring proper Node-to-Gateway communication, and we needed to implement it strategically to meet all functional requirements. By combining consistent hashing with load bounding, we created a telemetry routing mechanism that is affinity-aware, resilient to Gateway churn, and fair in load distribution. This architecture allows us to support horizontal Gateway scaling without sacrificing data consistency or overloading any single node, giving teams a reliable way to intelligently monitor their Kubernetes environments.
As telemetry data continues to grow in both volume and complexity, algorithms like consistent hashing will play a crucial role in ensuring observability systems remain robust and performant. If you’re grappling with similar scalability challenges in your own telemetry or distributed data pipeline, see how our Gateway Pipelines can help — start a free trial, or explore them for free on our playground.



