


Monitoring and alerting are both crucial processes for organizations to adopt to help ensure system maintenance. All industries, in particular IT, healthcare, and industrial process organizations, rely on these two methods to ensure operational performance and quickly troubleshoot production issues. As organizations continue to adopt these processes and refine them for their particular use-cases, it is imperative for developer to understand how monitoring and alerting work on a fundamental level.
This article will explore these processes in depth, enabling you to better integrate them into your current workflows.
Key Takeaways
- Monitoring and alerting are interconnected processes used to identify and mitigate problems. Many industries use them within their systems, servers, and infrastructures, including IT, healthcare, industrial processes, and more.
- With monitoring, teams can collect and analyze data to detect issues. It can also be used to create trends to predict upcoming problems. Some of the monitoring features include data collection, aggregation, and visualization.
- Alerting uses the monitored data to notify responsible parties of errors that need attention. With it, teams can configure customized instances as triggers and use tools to automatically send notifications when system violations, thresholds, or changes occur.
- Both processes involve the use of tools for automated workflows. Thus, the challenge is to find reliable monitoring and alerting to integrate into your tech stack.
- Using reliable tools like Edge Delta is the key to effective monitoring and alerting. Edge Delta ingests all log data upon creation and automatically creates intelligent analysis, enabling you to create monitors and send customizable alerts for immediate issue resolution.
Monitoring vs Alerting
Monitoring is the process of watching over a component or multiple components in your system, to verify everything is running smoothly. This is done by collecting relevant telemetry data and checking key statistics – such as the mean, median, max, and min – and waiting for one or multiple of them changes unexpectedly. With this process, organizations can report on different metrics and use them to ensure system health and performance are as expected. Monitoring generally includes the following parts:
- Storage
- Aggregation
- Visualization
- Automated Response
Note
Many people get Observability and Monitoring mixed up, as the two share several similarities. However, they are fundamentally different. Observability is the process of evaluating external information to reason about the internal state of a system, while monitoring is a subset of observability which focuses on watching over specific data sources waiting for them to stray from what’s expected of them.
Alerting expands on that last bullet – when a monitor witnesses an abnormality, it dishes out an automated response in the form of an alert to the appropriate parties. Monitoring works side-by-side with alerting, as the latter allows teams to define significant situations to manage while relying on software monitoring in changing conditions. In general, alerting does the following tasks:
- Notifies responsible parties
- Triggers programmatic responses
- Messages other concerned personnel when violations, thresholds, or system changes occur
Generally speaking, With monitoring, teams can collect data from their systems’ components and use it to detect issues. It allows triggers for alerting, which notifies DevOps teams, enabling immediate resolution. They work together to prevent downtime, improve system performance, and enhance security and operational efficiency.
Here is a table summarizing the difference between monitoring and alerting for better understanding.
| Aspect | Monitoring | Alerting |
|---|---|---|
| Function | Able to track system performance and health | Allows notification of anomalies and critical events |
| Purpose | Continuous data collection and observation | Efficient notification of specific events |
| Data Handling | Gather and analyze data from various sources | Trigger alerts based on constructed conditions |
| Objective | Prevent issues and optimize performance | Minimize downtime and ensure rapid problem response |
| Frequency | Continuous | Event-driven |
| Tools Used | Dashboards, Log Files, Reports | Email, SMS, Push notification |
Discover how each of these two process work in greater detail in the following section.
How Does Monitoring Work?
Conducting comprehensive monitoring involves several steps. The process mainly includes data collection, analysis, and visualization. Read on and learn the detailed steps of the monitoring process.
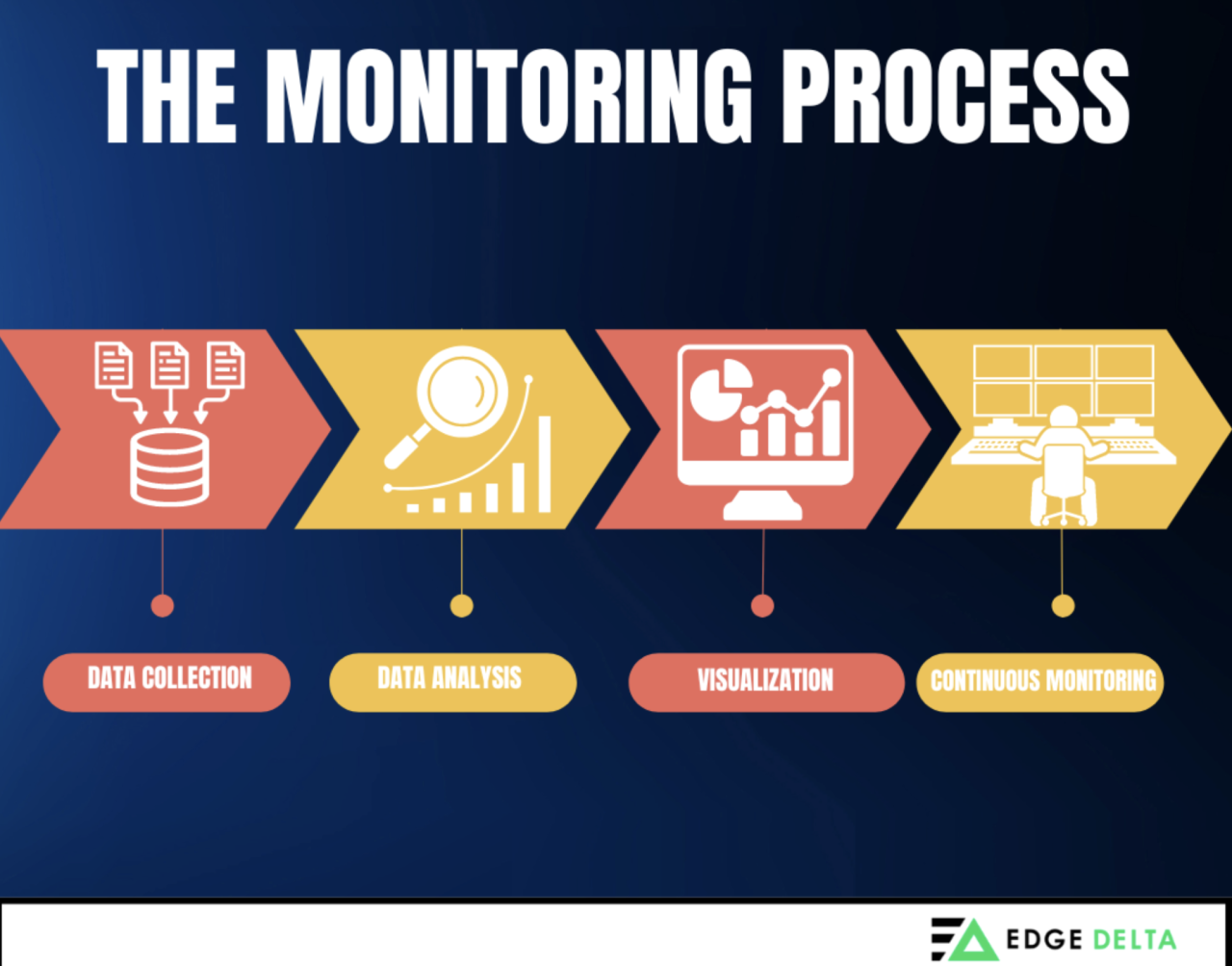
1. Data Collection
Monitoring begins by collecting data from multiple system components such as servers, network devices, and databases. This process is done with tools like agents, APIs, and log files, gathering data automatically and continuously to provide insights into the system’s performance and health. Agents later segment the data into metrics and submit them to the monitoring system.
2. Data Analysis
Analyze the collected data to create patterns, visualize trends, and detect anomalies. This step prevents future errors and fosters an accurate and effective system. Machine learning algorithms, correlation analysis, and statistical methods are typically used in this step, depending on organizational needs.
Note
Analysis can be challenging to implement within systems containing several components and large databases. In such cases, using reliable tools like Edge Delta for anomaly detection is most definitely ideal. Edge Delta uses AI to spot anomalies, troubleshoot quicker, and correlate logs for automated alerting.
3. Visualization
Data is visualized through dashboards that provide real-time insights into system performance. This step is crucial to understanding a system’s real-time performance. Periodic reports summarize the system’s health and performance over time.
4. Continuous Monitoring
Monitoring is a continuous, real-time process that ensures systems are constantly observed. It is crucial to ensure that the system works to improve its purpose. Automated observability platforms facilitate continuous monitoring and quick issue detection, which is why many operators use them in their systems.
However, monitoring can only be effective with proper alerting. Keep reading to understand the entire alerting process.
How Does Alerting Work?
Alerting is a crucial process for ensuring timely responses to system anomalies. Here’s a comprehensive guide on how alerting works:
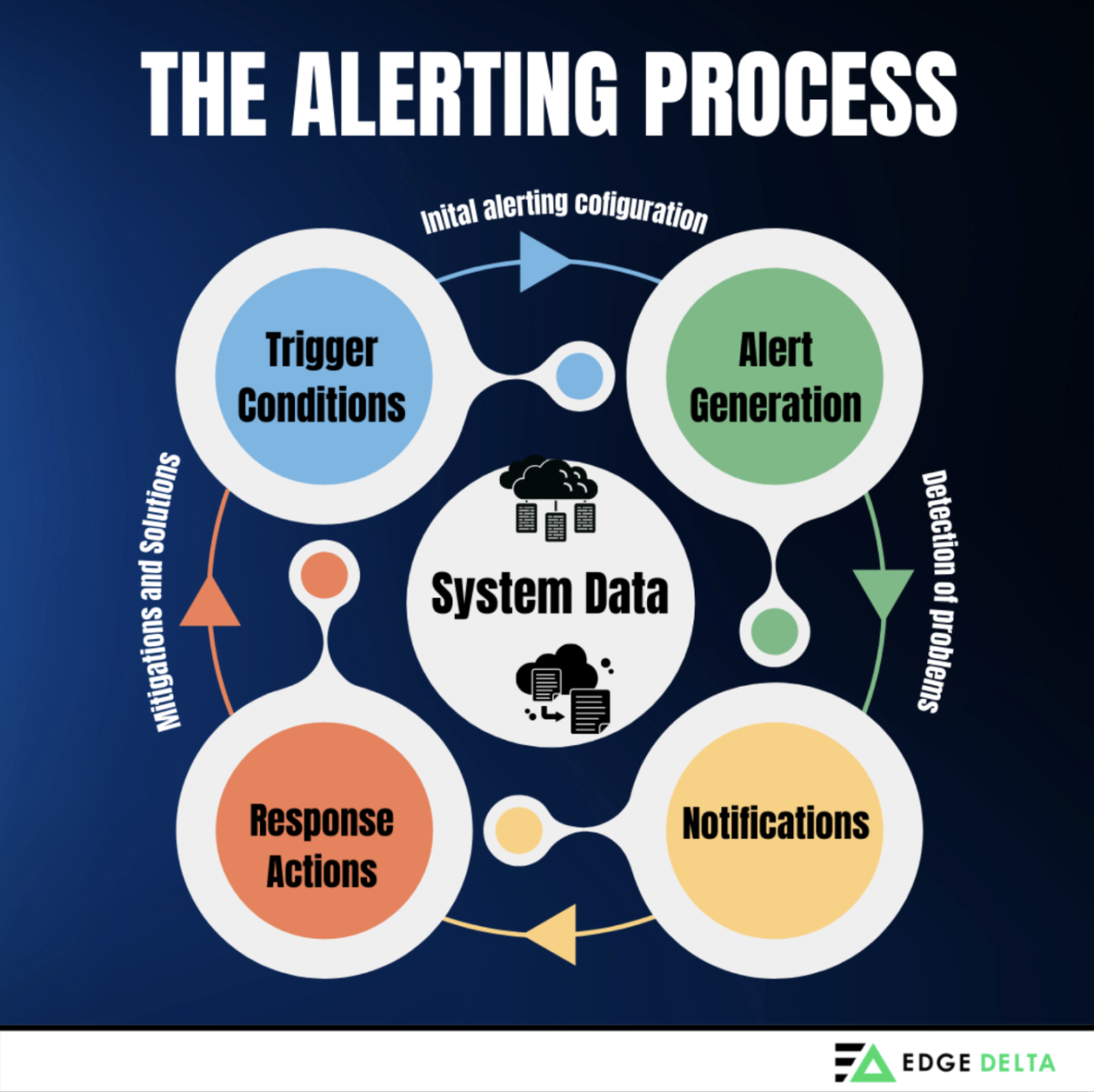
1. Trigger Conditions
Operators are solely responsible for establishing system baselines and finding triggers or relevant events that cause system behavior change. This serves as a starting point for creating an initial alerting configuration. The initial setup defines abnormal conditions by creating thresholds with exceptional metric values configured in the monitoring definition.
2. Alert Generation
The monitoring solution detects the problem or anomaly when the trigger conditions are met. It then generates alerts based on the predefined conditions. These alerts will help the team get notified and mitigate the existing problem.
Pro Tip
You can improve your alerting systems with real-time monitoring, to detect and even predict issues and trigger alerts in real time. These features will simplify your troubleshooting as it provides alerts quicker than other tools.
One example of an alert condition might be when a system detects a sudden drop in database performance, and the team has utilized 90% of its disk space.
3. Notifications
Alerts are communicated to team members via SMS, email, and push notifications. The notification methods and recipients can be customized depending on the severity and type of alert needed. One example of customizing notifications is email configuration alerts for high-severity incidents and Slack notifications for low-severity warnings.
4. Response actions
Upon receiving an alert, immediate actions are taken to investigate and resolve the issue. These actions include restarting, debugging, or troubleshooting the server after receiving an alert. Additionally, all actions and responses are documented for future reference and analysis.
The following section discusses monitoring and alerting best practices you can implement to ensure the best results.
Best Practices for Monitoring and Alerting
Effective monitoring and alerting requires implementation with best practices in mind, to generate accurate alerts, minimize organizational risk, and prevent alert fatigue.
Implementing best practices ensures that the details from logs and metrics are used properly to maintain your web application’s security, stability, and performance. Additionally, tuning and optimizing network monitoring and alerts is essential for:
- Improved system reliability
- Faster incident response
- Proactive issue resolution
The following section will show proven best practices that provide a robust monitoring and alerting framework for maximizing the value of network monitoring alerts:

Define Clear Objectives
Setting clear objectives is the foundation for an organization’s effective monitoring and alerting strategy. These objectives should align and coordinate with the company’s goals and enable the definition of success in measurable terms.
One practical objective might be achieving 99.9% uptime for critical applications. Organizations should ensure that critical applications are always operational and available to accomplish this. Another example of a defined objective is maintaining a response time of under five minutes for high-priority incidents, ensuring swift action when issues arise.
Use Appropriate Monitoring and Alerting Tools
Different environments and system requirements call for specific solutions that best meet the organization’s needs. Therefore, choosing the right tool is crucial for effective alerting and monitoring. Select tools that do not only solve your organization’s anomalies but are also easy to use and compatible with your existing system.
Here are some recommended tools you can use for your organization:
- Edge Delta: Excellent for real-time monitoring and alerting using AI and visual pipelines.
- Nagios: Suitable for traditional IT infrastructure monitoring.
- Splunk and ELK Stack: Effective for logging and alert management, providing robust data analysis and visualization capabilities.
- Prometheus and Grafana: Ideal for monitoring and visualizing metrics in cloud-native environments.
Regularly Update and Test Systems
Regularly updating and testing the system ensures that the monitoring and alerting systems function and remain effective. These updates help tools function at their full potential and effectively identify issues before they become critical. They also ensure that the organizational system can handle new challenges.
You can implement the following tasks in your infrastructures and systems:
- Perform Monitoring and Alerting Software Updates: Patch vulnerabilities and improve functionality regularly.
- Conduct Routine Tests: Ensures and validates the accuracy of alerts and responsiveness of monitoring tools. Simulate failures or high-load scenarios to evaluate system and team responses.
Integrate Monitoring and Alerting
Incorporating monitoring and alerting processes provides a coherent and efficient system management experience. Additionally, integrating these two approaches improves event correlation and provides more effective incident management.
One strategy for integrating monitoring and alerting is using incident management platforms. These platforms include tools like PagerDuty or Opsgenie with the following features:
- Guaranteeing alerts that trigger predefined workflows
- Automatically notifying the right personnel
- Logging incidents for further analysis
An SRE Teammate can handle the next step automatically — taking an incident from alert to investigation without waiting for on-call engineers to begin triage.
Train Your Staff for Effective Monitoring and Alerting
Systems within organizations regularly update and change, which can hinder productivity. Because of this, employees need to adapt, learn new information, and navigate changes, which is why training is highly recommended.
Well-trained employees can interpret data accurately, respond to alerts quickly, and take the necessary actions. These behaviors are critical components of effective alerting and monitoring. Here are some tips for an effective training program:
- Regular Workshops: Provide hands-on exercises and up-to-date documentation.
- Continuous Learning: Encourage staff to pursue online courses and certifications for monitoring and alerting tools and practices.
Wrap Up
Monitoring and alerting are crucial components of software development, enabling teams to ensure optimal performance, reliability, and user experience. Visualizing what is happening within your organization’s system and what immediate resources are needed is valuable for minimizing errors.
While integrating and designing monitoring and alerting setups within your organization can be challenging, it is an investment that will help your organization simplify the troubleshooting process and ensure success. Edge Delta’s SRE Teammate automates much of this work — correlating alerts, analyzing logs, and surfacing root-cause context so engineers spend less time on investigation and more time on fixes.
Monitoring and Alerting FAQs
What is monitoring and alerting?
Monitoring is an approach interconnected with an alerting system. This approach notifies team members if any critical events occur or if specific thresholds are reached within the system.
What are the benefits of monitoring and alerting?
One of the benefits of monitoring and alerting is that it can notify users of issues or problems before they become serious. It also prompts organizations to adjust when monitoring shows that current approaches are not working.
What monitoring and alerting strategies do you follow to ensure system health and performance?
Organizations use white box monitoring to instrument the application with semantic logs and metrics.
Sources:

