

As log data volumes have exploded, observability stacks have become increasingly complex. This post walks you through how Edge Delta can simplify your logging architecture to help you:
- Eliminate vendor lock-in at the monitoring layer
- Maintain performance as data volumes scale
- Increase control over what you index downstream
Before discussing our approach, let’s first go over the current state of logging architectures.
The Current State of Logging Architectures
Enterprise logging architectures are largely built using a “centralize-then-analyze” approach, meaning the data must be centralized in a monitoring platform before users can query or analyze it.
Building your logging architecture in this manner worked well in a previous era when data volumes were comparatively smaller. However, with the rise of cloud and microservices, applications now generate significantly more log data.
As a byproduct of this data growth, monitoring platforms are becoming prohibitively expensive and teams have shrinking visibility. Plus, it’s simply not feasible to collect, compress, and ship terabytes (and in extreme cases, petabytes) of data while supporting real-time analytics.
Moreover, collecting and shipping today’s log volumes is becoming increasingly complex. For example, it’s not uncommon for us to see a single customer moving data across:
- FluentBit log collection agents
- FluentD log aggregator
- Elastic Logstash
- Kafka pipeline
How Edge Delta Approaches Logging Architectures
At Edge Delta, we’ve spent a lot of time talking to customers about these challenges, and we encourage DevOps and SRE teams to approach logging architectures in a different way.
Our architecture replaces log collectors and pipelines. However, in addition to superseding their functionality, it also pushes analytics upstream to the data source. In the sections that follow, I’m going to walk you through this approach by discussing each level of the typical logging architecture and demonstrating how Edge Delta is a better fit for dealing with modern data volumes, starting with the collection level.
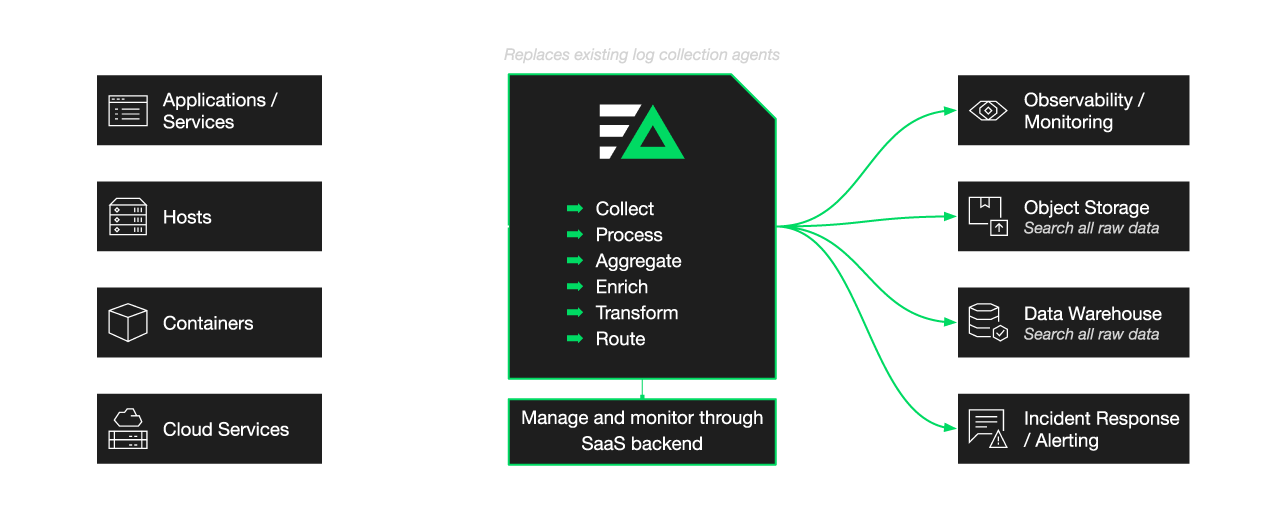
Log Collection and Forwarding
Log collectors typically fall into two categories: open source and vendor specific. Both of these categories have their shortcomings.
The open-source log collectors that are in the market today simply weren’t built for the volume of data that cloud-first teams are generating – they quickly become overwhelmed and fail.
Moreover, these collectors often lack any sort of fleet management:
- It’s difficult to understand agent health – there’s no simple way to understand when your agents stop sending data or if they’re having CPU/memory issues.
- If you’re making lots of configuration changes, there’s no way to test and iterate before deploying into production.
Vendor-specific log collectors deliver better performance and fleet management than their open-source counterparts. However, the nature of these offerings creates vendor lock-in, which is problematic in itself and even more so when you consider that teams are questioning the viability of centralized logging architectures long term. Ultimately, teams need flexibility in both the near and long term when it comes to observability tooling. Vendor-specific collectors detract from that.
Lastly, if you’re leveraging multiple analytics tools to support different teams, it’s likely that you’ve deployed multiple agents, adding complexity to your environment.
How Edge Delta is Different
Edge Delta gives customers better flexibility and performance at the collection level.
Vendor Agnostic
Our agent is vendor-agnostic, meaning that you can collect and route logs from any data source to any destination. This flexibility allows teams to support multiple streaming destinations with a single agent and mitigate vendor lock-in.
Built to Support Any Data Volume
Edge Delta’s agent is both lightweight and highly performant. You can reliably collect and route petabytes worth of data through the agent, while taking up less than 1% in both CPU and memory. This performance gives teams more reliability and a future-proof method for collecting growing datasets.
Superior Fleet Management
From the Edge Delta SaaS backend, customers can manage and roll out agent configurations. They can also easily monitor the health of deployed agents. Overall, Edge Delta’s management layer closes a gap created by open-source collectors.
Data Pipelines
The issue with data pipelines goes hand in hand with scalability. Pipelines are deployed centrally and can become overwhelmed by the volume of data passing through them. In some cases, this simply impacts performance: slower searches and queries or higher latency for alerts. In more extreme cases, the pipeline fails altogether.
Moreover, earlier we discussed how teams have explored mechanisms for limiting the volume of data that they ingest and index. We’ve found the pipelines often help teams push the sampling, filtering, and dropping of data upstream. But, they do very little to help teams understand their datasets and determine what is worth indexing.
How Edge Delta is Different
Data Processing at the Source
Unlike traditional data pipelines, Edge Delta runs analytics on all log data at the source. Specifically, as data is created, Edge Delta (a) deduplicates loglines through pattern analytics and (b) creates metrics off the log data.
Patterns help teams reduce noise and better control what data is indexed in their monitoring platform. For example, let’s say one logline is generated 100,000 times over the course of a five-minute span. It’s unlikely their team needs to see each individual logline – they simply need to know what the message says and how frequently it’s been occurring. With Edge Delta, you can gain that insight and pass along a sample of the data to your observability platform.
Logs to Metrics conversion summarizes high-volume, noisy datasets into lightweight KPIs. Edge Delta baselines the KPIs over time, so you can easily tell when something is abnormal or anomalous – a good sign that you want to index that data. We also generate alerts when any anomalies occur. The benefit here is two-fold:
You can be smarter about what you index downstream
You can generate alerts with greater speed and accuracy
Putting It All Together
Edge Delta serves a few different capacities within your observability stack, superseding the functionality of traditional log collectors and pipelines. Unlike its predecessors, Edge Delta actually processes data as it’s created. As a result, teams can…
- Break free from vendor lock-in
- Analyze larger data volumes in real time
- Better control what data they index downstream
If you’d like to learn more about our approach, start a free trial.



