When a financial services company discovered suspicious transactions from six months earlier, investigators needed to dig into old logs for answers. The problem? Those logs were sitting in cold storage. Pulling them back took hours — delaying the investigation and prolonging downtime.
This is where log rehydration comes in. It’s the process of restoring archived logs into a searchable, usable format for real-time analysis and audits. By bridging the gap between low-cost storage and rapid access, log rehydration lets teams retrieve exactly what they need — when they need it — without paying to keep every log in hot storage.
In this guide, we’ll break down how log rehydration works, the tools that make it possible, and best practices for implementation. You’ll discover how to cut storage costs, accelerate incident response, and keep your organization audit-ready by making historical data instantly accessible.
Key Takeaways
• Log rehydration restores archived logs to a searchable state, enabling analysis or audits without storing everything in costly hot storage.
• Common use cases include incident investigations, compliance audits, and long-term trend analysis.
• Logs naturally move through storage tiers, shifting to cheaper storage as they age.
• Rehydrating everything is costly. Use filters like time range or service tags to retrieve only relevant logs.
• Choose tools that fit your environment. Enterprise platforms, cloud-native services, and open-source solutions handle rehydration differently.
• Automate where possible. Set triggers and workflows to run rehydration during incidents or audits without manual intervention.
• Watch out for hidden costs — retrieval fees and processing charges can escalate quickly.
Understanding What Log Rehydration Is
As organizations generate massive volumes of log data, storing everything in high-performance systems quickly becomes costly and unsustainable.
Many logs are valuable only for a short time, but others must be revisited weeks or even months later — often during compliance audits, incident investigations, or historical reporting. That’s where log rehydration becomes essential.
Log rehydration is the process of restoring archived or compressed log data into an accessible, searchable format. It enables teams to retrieve and analyze historical logs that were moved to lower-cost, long-term storage — making it possible to investigate past incidents, fulfill audit requests, or analyze trends without the expense of keeping everything in hot storage.
This capability supports security response, forensic analysis, compliance, and long-term observability. Archived data is brought back into hot or warm storage, where it can be queried using standard log management tools. The approach is especially valuable in cloud-native environments and large-scale systems, where storing all log data in active memory is prohibitively expensive.
With log rehydration, organizations no longer have to choose between cost and access — they can minimize storage expenses while keeping older logs actionable whenever they’re needed.
The Log Data Lifecycle
To understand log rehydration, it’s important to grasp the broader log data lifecycle and the concept of storage tiers:
- Hot storage holds recent logs that require real-time access. It offers low-latency querying but at higher storage costs.
- Warm storage is slightly less accessible but more cost-efficient and often used for logs days or weeks old.
- Cold or archive storage is used for infrequently accessed logs that must be retained for legal or operational reasons.
As logs move through these tiers, they become less accessible but cheaper to store. The log rehydration process temporarily reverses this flow, restoring data to active systems as needed.
Rehydration supports key business needs like incident response, regulatory compliance, forensic analysis, and historical reporting, bridging the gap between long-term retention and real-time insight.
When Do You Need Log Rehydration?
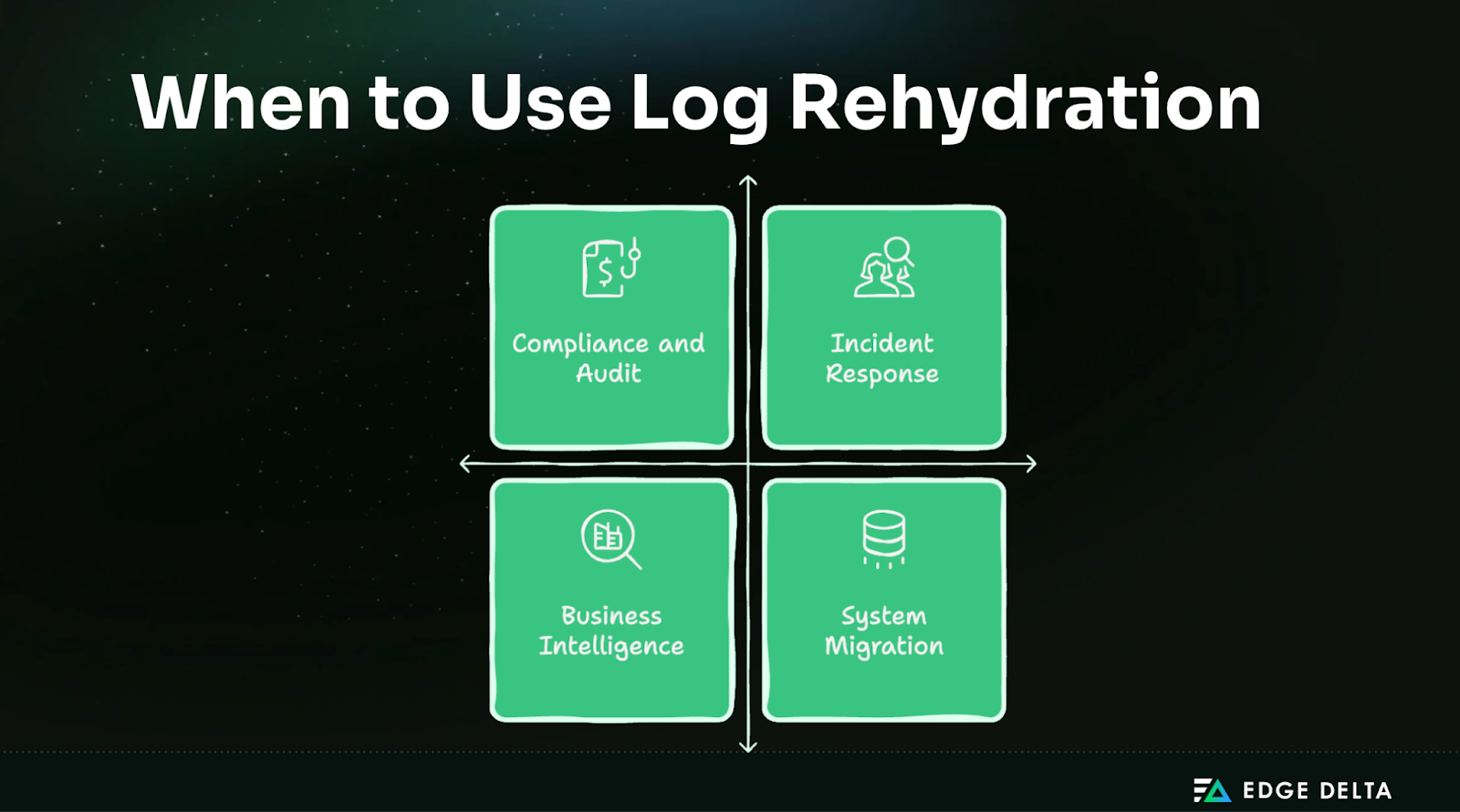
Log rehydration becomes essential when organizations must access older log data that has been stored in compact, long-term formats. Instead of keeping all logs in high-cost hot storage, businesses can archive logs affordably and selectively rehydrate them when detailed access is required. This capability balances cost efficiency with operational and regulatory demands across multiple scenarios.
Incident Response and Forensics
In cybersecurity and operations, fast access to historical logs can make or break an investigation. When responding to advanced persistent threats (APTs), teams often need to analyze months-old logs.
For example, during a data exfiltration investigation, engineers might rehydrate logs from cold storage to examine outbound traffic anomalies over the last six months. Similarly, an exhaustive postmortem following recurring outages may involve rehydrating infrastructure logs that span across multiple deployments.
Log rehydration allows security teams to isolate relevant data without incurring the cost of keeping everything live. It streamlines root cause analysis and supports regulatory responses, such as showing a complete audit trail during a compliance breach investigation.
Compliance and Audit Requirements
Regulated industries, like finance, healthcare, and e-commerce, are required to retain logs for years. However, storing these logs in their original format is prohibitively expensive. Log rehydration offers a more sustainable path.
Consider a financial institution complying with SOX regulations or responding to a GDPR subject access request. Instead of keeping seven years of full logs in hot storage, it can move them to low-cost object storage and rehydrate only the records needed for the request or investigation
Similarly, legal teams may use rehydrated logs to support litigation or reconstruct events for discovery. This selective retrieval model meets both legal and operational obligations while remaining cost-effective.
Business Intelligence and Analytics
Rehydrated logs are also valuable for long-term analytics. Data teams might analyze rehydrated logs to compare year-over-year performance, uncover seasonal user trends, or model customer behavior over time.
For example, a retailer planning peak season capacity could rehydrate transaction logs from prior holiday seasons to forecast infrastructure needs. This approach avoids keeping analytical logs in expensive hot storage while still enabling in-depth historical insights.
System Migration and Consolidation
As organizations modernize infrastructure or adopt cloud-native architectures, they often retire legacy systems or consolidate platforms. In these transitions, historical logs become crucial for verifying system behavior, troubleshooting cutover issues, and preserving audit trails.
For instance, when decommissioning legacy infrastructure, a company may rehydrate logs to verify service history and ensure no critical events are missed. Rehydration during these transitions supports operational continuity and minimizes the risk of data loss, without inflating infrastructure costs.
The Log Rehydration Process
Log rehydration is not just about accessing old logs. It’s a structured, resource-aware workflow that restores archived data to a usable, searchable state. Understanding this process requires knowledge of storage tiering, rehydration mechanics, and optimization techniques that ensure performance and cost-efficiency.
Storage Tier Architecture
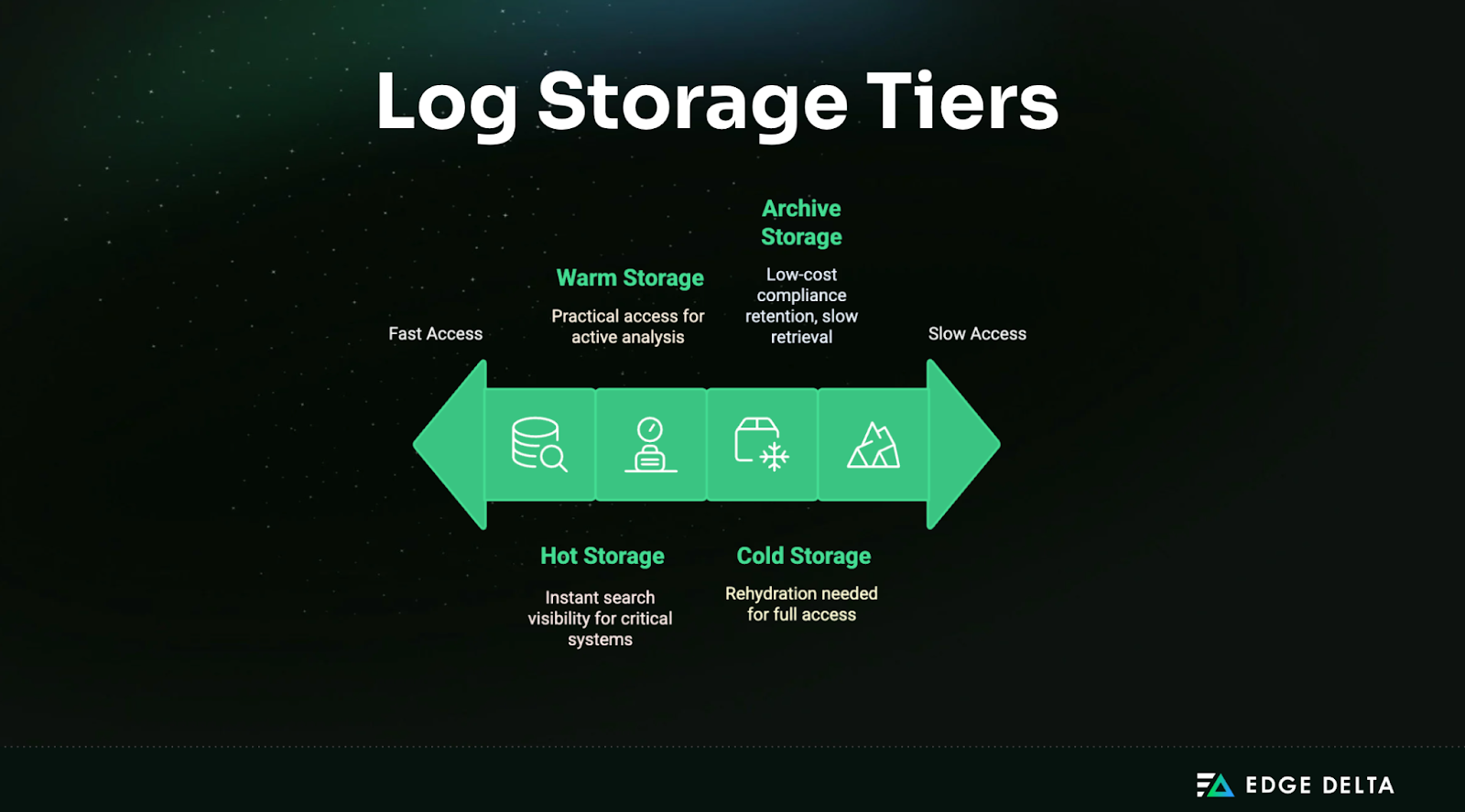
Modern log management systems use a tiered storage model to balance cost and performance:
- Hot Storage: Holds real-time logs that are immediately searchable. This tier supports critical systems needing instant log visibility, such as production services or security operations centers.
- Warm storage: Retains recent but less frequently queried logs. Access is slower than hot storage but still practical for active analysis. This storage is ideal for logs a few days to a few weeks old.
- Cold storage: Contains infrequently accessed logs in compressed formats. These logs are not readily searchable and must be rehydrated for full access.
- Archive or Glacier storage: For example, AWS Glacier is used for long-term, low-cost compliance retention. Retrieval from this tier can take hours and involve additional costs.
Logs typically move between storage tiers based on time-based policies. They can also be transitioned due to size thresholds or custom retention rules set by compliance or business needs.
Rehydration Workflow Steps
The log rehydration process follows a series of technical steps to safely restore archived data for analysis:
Step 1: Request Initiation
Rehydration begins with a request, which can be triggered manually or automatically by a monitoring or audit system. For example, a breach detection tool may auto-trigger rehydration for relevant historical logs.
Step 2: Data Identification
The system locates the required logs using metadata tags, timestamps, or indexing services. Efficient tagging during archiving, as outlined in the guide to log collection, significantly speeds up this step.
Step 3: Retrieval Process
The data is moved from cold or archive storage to a temporary warm or hot tier. Retrieval time varies by provider — for example, AWS Glacier may take minutes (expedited) to hours (bulk).
Step 4: Index Rebuilding
Search indexes and metadata are rebuilt using tools like Elasticsearch or OpenSearch, enabling fast queries. Efficient log data restoration makes even compressed or segmented logs quickly searchable.
Step 5: Validation
Integrity checks using hash comparisons or checksums ensure the data was retrieved completely and accurately.
Step 6: Access Provisioning
The logs are made available through dashboards or query interfaces, with access restricted to authorized users based on security controls.
Step 7: Cleanup Procedures
After use, temporary copies may be deleted or moved to warm storage based on cost considerations or data retention policies.
Technical Considerations
Several factors influence the success and efficiency of rehydration:
- Processing Time: Depends on the data volume, archive tier (e.g., AWS Glacier vs. S3 Infrequent Access), and retrieval method.
- Resource Requirements: Increase with log size and index complexity. Expect high CPU, memory, and I/O usage for large-scale rehydration jobs.
- Data Compression: Must be handled carefully; logs are often stored in formats like GZIP or Parquet, requiring decompression before indexing.
- Index Optimization: Balances speed and storage use — rebuilding only necessary fields or metadata can save time.
- Parallel Processing: With distributed systems (e.g., Apache Spark, Kubernetes pods), helps scale rehydration efficiently, especially for multi-terabyte archives.
Tools and Platforms for Log Rehydration
Successful log rehydration starts with choosing the right tools. Each platform has its strengths — some prioritize speed, while others focus on cost efficiency or flexibility. Enterprise, cloud-native, open-source, and niche solutions all take different approaches. Here’s what to consider when evaluating your options.
Enterprise Log Management Platforms
Enterprise log platforms offer built-in solutions for cold storage and log rehydration, balancing performance, compliance, and cost. Many include automation, granular search, and pricing models tailored to usage patterns.
- Splunk: Provides rehydration via SmartStore and archive integration with S3 or Glacier. Retrieval can be index-based or ad hoc, with costs depending on storage tier and access frequency.
- Elastic Stack (ELK): Uses Index Lifecycle Management (ILM) and searchable snapshots to shift older indices to low-cost storage. Rehydration is customizable, with cost-performance trade-offs based on configuration.
- Datadog: Supports S3 archiving and rehydration via Log Rehydration Pipelines. Restoration is billed as new ingestion. Replay can be filtered by time or tags to optimize cost.
- Sumo Logic: Enables querying of cold logs from S3. Access is seamless but can involve latency and storage-class-related charges.
- Edge Delta: Uses a distributed edge model for smart archival and selective rehydration. Integrates with other tools across the observability stack.
- IBM QRadar: Offers secure, compliance-focused archival and rehydration. Performance depends on archive size. Pricing is based on events per second, with extra fees for long-term retention.
Cloud-Native Solutions
Cloud platforms provide native tools for log archiving and retrieval, tightly integrated with storage, analytics, and automation.
- AWS: Supports rehydration via CloudWatch Logs, S3 Glacier, and Athena. Costs vary by retrieval speed (standard or expedited), Glacier tier, and Athena scan volume. Integrates with Lambda and Step Functions.
- Azure: Uses monitor logs and archive storage for rehydration into Log Analytics workspaces. Billed by data size, access frequency, and processing time. Automation and querying are supported via Azure Automation and Data Explorer.
- Google Cloud: Exports logs to Cloud Storage, BigQuery, or Pub/Sub. Cold logs can be queried or re-imported. Pricing depends on storage tier and BigQuery scan volume.
- Cloud Storage Services: S3, Azure Blob, and Google Cloud Storage support direct rehydration from hot, cool, or cold tiers, balancing latency with lower storage costs.
Open-Source and Custom Solutions
Open-source tools and scripts offer flexibility and cost control for organizations with custom infrastructure.
- ELK Stack uses Curator for index lifecycle management and rehydration via snapshots. Scripts or APIs can automate the restore process.
- Fluentd / Fluent Bit are lightweight agents enable custom rehydration pipelines. Logs can be routed to Elasticsearch, Kafka, or cloud platforms. Performance varies with pipeline design.
- Apache Kafka allows streaming rehydration by replaying archived topics from specific offsets. It integrates with real-time systems like Flink or Spark.
- Custom scripts like Shell, Python, or Ansible automate log retrieval via API. They are suitable for tailored workflows across cloud and on-prem environments.
Specialized Archival Tools
These tools are optimized for long-term, large-scale storage and rehydration in distributed or time-series environments.
- Hadoop ecosystem: HDFS supports the rehydration of log archives using Hive or Spark for high-volume analytics.
- Time-series databases: InfluxDB and Prometheus (with remote write/read) support rehydration from backends like Thanos or Cortex.
- Object storage tools: MinIO and Ceph offer S3-compatible APIs for scalable rehydration from cold tiers.
- Backup solutions: Commvault and Veeam provide log-specific recovery, including application-aware and incremental restoration.
Rehydration Strategies and Best Practices
Efficient log rehydration isn’t just about pulling old data back into your system — it’s about doing it intelligently, with cost, performance, and usability in mind. Without a clear plan, rehydration efforts can quickly spiral into bloated costs, long recovery times, or even incomplete datasets.
By applying thoughtful strategies and proven best practices, teams can streamline rehydration efforts, maintain system stability, and ensure that restored data is meaningful and actionable.
Planning and Strategy
Before initiating any rehydration job, define what data you need. Restoring all historical logs might seem like a good idea, but it’s rarely necessary and can be prohibitively expensive — especially in enterprise-scale environments. Instead, aim for targeted rehydration based on relevance.
Use selective filters — such as service name, timestamp range, or source path — to narrow the scope. For instance, in AWS Athena or ElasticSearch snapshot restore, you can apply queries like WHERE timestamp BETWEEN x AND y AND service = ‘auth’ to pull only what’s needed for an investigation.
- Partial restoration is particularly useful for audits, security incidents, or compliance reviews where only a subset of data is required. For large datasets, apply batch rehydration strategies to break jobs into smaller chunks, reducing memory consumption and avoiding timeouts.
- Schedule rehydration during off-peak hours to minimize impact on production systems. Many cloud platforms support tiered retrieval options to help teams optimize for either speed or cost, depending on business needs.
Technical Best Practices

Technical precision ensures that restored logs are usable and trustworthy. The following practices help maintain log integrity, optimize speed, and reduce operational overhead:
- Preserve metadata and indexes: Avoid having to reparse logs by maintaining original metadata during archiving. This ensures logs remain searchable immediately after rehydration, especially if you’ve used tools to normalize legacy log formats before storage.
- Use efficient compression: Formats like LZ4 and Zstandard offer high-speed decompression and reasonable compression ratios, making them ideal for fast rehydration.
- Enable parallel processing: Distribute workloads across nodes using tools like Edge Delta, Apache NiFi, or Fluent Bit to prevent bottlenecks and accelerate throughput.
- Adopt incremental rehydration: Restore data in time-based chunks (e.g., hourly or daily) to manage memory use and simplify failure handling. This approach also enables parallel recovery efforts.
- Validate data integrity: Automate checks using checksums, record counts, or built-in validation tools. Integrate these tests into your CI/CD pipeline to catch issues early.
Operational Best Practices
Operational discipline ensures your rehydration process is secure, repeatable, and responsive. These practices help teams maintain control, auditability, and readiness:
- Set automation triggers: Use tools like Datadog, Azure Monitor, or custom webhooks to automatically initiate rehydration in response to predefined events like outages or security incidents.
- Enforce access controls: Apply IAM policies, RBAC, or custom ACLs to limit who can initiate and access rehydrated data, especially when sensitive logs are involved.
- Monitor and alert on progress: Use Prometheus, Grafana, or OpenTelemetry to track restore jobs, identify anomalies, and alert on errors or delays.
- Maintain audit documentation: Log all rehydration activities, including data ranges, users involved, and timestamps. This practice helps ensure traceability for audits or postmortems.
- Test regularly: Conduct scheduled dry runs or chaos engineering scenarios to confirm that rehydration pipelines perform as expected when under pressure.
Cost Management and Optimization
Rehydrating archived logs can yield valuable insights, but it comes at a cost. From storage and retrieval fees to processing and time-based pricing, controlling expenses requires smart planning.
Below is a breakdown of key cost drivers, budgeting tips, and optimization strategies to keep rehydration efficient and affordable.
Cost Factors
Log rehydration involves several cost components:
- Storage tiers: Cloud platforms charge differently based on storage class. For example, AWS Glacier storage averages around $0.004/GB/month, while Azure Archive can be as low as $0.002/GB/month.
- Retrieval fees: Retrieval fees for cold storage log retrieval range from $0.01–$0.03/GB, depending on speed. Selecting the right tier is key to managing costs during large-scale restores.
- Processing/operation charges: These include request-based charges, like $0.005 per 1,000 requests.
- Time-based pricing: Faster retrieval comes at a premium, which can significantly affect total cost.
Optimization Strategies
To control costs:
- Selective rehydration: Only restore essential log segments.
- Scheduled operations: Time rehydration during periods of lower demand.
- Bulk processing: Group log restores to reduce request frequency and optimize throughput.
Budget Planning
Example:
- Storing 100 TB in Azure Archive costs around $204/month.
- Rehydrating 1% of this (1 TB/month) may cost about $33 (retrieval + processing).
- Annually, expect ~$2,450 in storage and ~$400 in retrieval expenses.
Cost Comparison
- Cloud: Offers predictable OpEx with pay-as-you-go pricing and scalability.
- On-premises: Higher upfront CapEx (e.g., $90K+ for 100 TB) plus ongoing maintenance, power, and personnel costs.
ROI Analysis
Cloud rehydration provides a strong ROI when log retrievals are infrequent or unpredictable. On-premises solutions may make sense only for high-frequency or regulatory use cases that require constant access to full archives.
Vendor Pricing Models
- AWS, Azure, and GCP use tiered pricing with combinations of storage, request, and retrieval costs.
- Some vendors like Backblaze B2 offer flat rates with fewer hidden charges, making them attractive for predictable usage.
While the strategies above can guide effective cost planning, there are still real-world risks and edge cases worth considering before implementation.
Pro Tip
Even with careful planning, costs can spiral. Teams often exceed budgets due to untracked API calls, frequent restore jobs, or unexpected egress fees. These hidden costs add up quickly. Active cost tracking is critical to keeping rehydration financially viable.
Use AWS Cost Explorer, Azure Cost Management, or GCP’s Pricing Calculator for forecasting and alerting. Third-party tools can offer more granular visibility across hybrid environments.
Performance Optimization
Optimizing log rehydration is critical for minimizing delays, controlling costs, and ensuring seamless access to historical data. The following technical strategies offer practical guidance for enhancing efficiency and reliability across rehydration workflows.
Identify Bottlenecks
Common performance bottlenecks occur at three levels:
- Network latency can slow down large-scale retrievals from cold storage, especially when restoring from remote regions.
- Storage I/O limits on archive tiers like Amazon S3 Glacier (3–5 hours for standard retrieval) or Azure Archive can delay access.
- Processing limitations arise when downstream systems can’t keep up with restored data inflows.
Use tools like AWS CloudWatch, Elastic APM, or Datadog to monitor I/O throughput, network traffic, and pipeline congestion.
Leverage Parallel Processing
Distribute rehydration tasks across multiple nodes or containers to improve throughput. For instance, using Apache Spark or AWS Lambda concurrent executions can significantly reduce restore times for high-volume datasets.
However, parallelism increases resource demand and may incur higher bandwidth charges.
Implement Caching Strategies
Cache recently rehydrated logs in fast-access storage (e.g., SSD-backed EBS volumes or in-memory stores like Redis) to minimize repeated retrievals. This is especially useful for incident investigations involving iterative queries over the same dataset.
Optimize Indexing
Pre-building indexes can speed up access during rehydration, as opposed to on-demand indexing, which increases CPU load. Elasticsearch’s searchable snapshots or Splunk’s tsidx files are good examples of index-optimized storage.
Manage Resource Allocation
Provision adequate CPU, memory, and bandwidth to match workload scale. Under-provisioning causes delays; over-provisioning increases costs. Monitor key metrics such as restore latency, ingestion rate (MB/s), and CPU utilization to calibrate allocations.
Trade-offs and Recommendations
Balancing speed, cost, and resource usage requires scenario-based tuning.
- For urgent analysis, use expedited restore tiers.
- For batch jobs, schedule during off-peak hours with throttled bandwidth.
- Automate rehydration pipelines with workflows in Apache Airflow or Step Functions to scale intelligently.
Regular profiling and KPI tracking can turn log rehydration from a bottleneck into a high-efficiency data access layer.
Common Challenges and Solutions
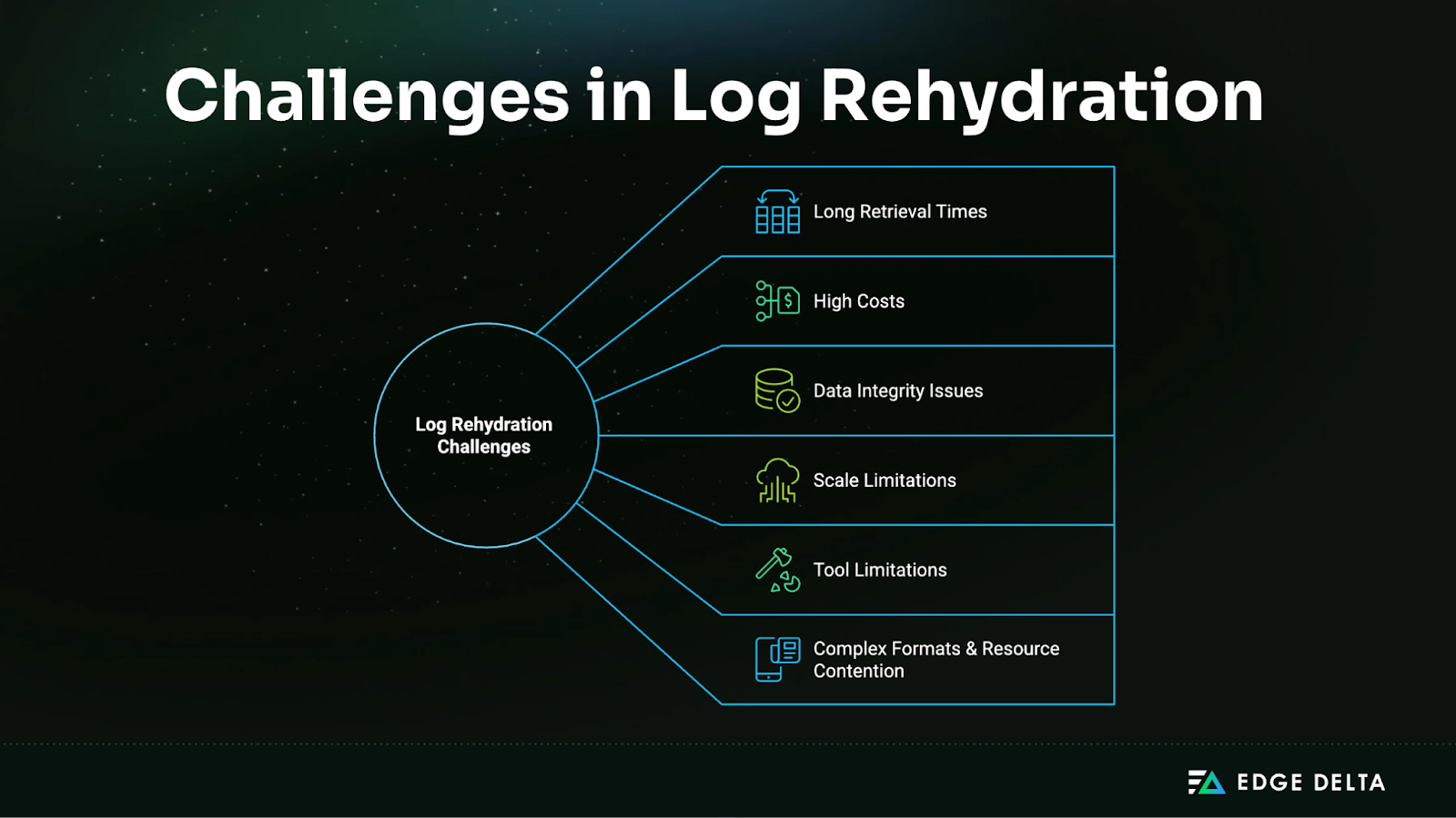
Managing log rehydration involves multiple operational hurdles. Below are key challenge–solution pairs with practical strategies to improve reliability, cost-efficiency, and scalability.
1. Long Retrieval Times → Tiered & Predictive Rehydration
Challenge: Cold storage classes like Glacier Deep Archive may take hours to restore archived logs.
Solution: Use tiered access strategies, store critical logs in faster-access tiers (e.g., Glacier Instant Retrieval), and bulk data in deeper archives. Predictive rehydration based on alert triggers or known access patterns can reduce delays.
2. High Costs → Cost Optimization & Budget Management
Challenge: High retrieval and API request fees can quickly inflate cloud bills.
Solution: Implement scheduled rehydration windows and group requests to use cost-effective retrieval tiers. Use native cost monitoring tools to track usage, set alerts, and automate transitions of older logs into lower-cost storage tiers.
3. Data Integrity Issues → Automated Validation
Challenge: Corrupt or incomplete data may lead to inaccurate incident analysis or audit failure.
Solution: Use automated checksums and sampling to validate rehydrated data, ensuring reliable log data recovery for audits and forensic use.
4. Scale Limitations → Hybrid & Parallel Operations
Challenge: Large-scale rehydration can strain bandwidth, computing, or logging infrastructure.
Solution: Parallelize restore processes and use chunked transfers. In high-scale environments, adopt hybrid cloud storage — keep recent data in hot storage and offload cold logs to archival services.
5. Tool Limitations → Toolchain Augmentation
Challenge: Native tools may lack flexibility for complex or high-volume workflows.
Solution: Extend workflows with services like Lambda, Step Functions, or custom orchestration tools to manage rehydration jobs more effectively and automatically.
6. Complex Formats & Resource Contention → Test & Prioritize
Challenge: Rehydration often competes with production workloads and must process diverse log formats.
Solution: Automate log validation with format-aware testing, and run rehydration tasks during off-peak hours. Use resource throttling or isolate rehydration jobs from critical systems.
Real-World Example
A healthcare tech platform archived over 450 million log files (~40 TB) to AWS Glacier. To avoid high costs from storing many small files, they bundled logs into compressed .tar.gz archives, cutting the object count by over 90%.
By organizing archives by date and device ID, they enabled selective rehydration, retrieving only what was needed during audits or incident reviews.
The result:
• 90%+ cost reduction in lifecycle transitions
• Up to 10× storage savings through compression
• Faster, more efficient rehydration with minimal overhead
Automation and Orchestration
Automating log rehydration reduces latency, operational overhead, and human error. Here are advanced strategies using event-driven triggers, analytics, policy rules, and orchestration tools.
Trigger-based Automation
Use S3 event notifications with AWS Lambda to initiate restores automatically. These triggers can also launch pattern-based monitors for restored logs to surface anomalies during rehydration.
Example:
Events: [ "s3:ObjectCreated:*" ]
LambdaFunction:
Handler: restore_handler.lambda_handlerWhen a new archive object is created, the Lambda function retrieves the metadata and initiates a restore via the restore-object API.
Predictive Rehydration
Analyze access patterns with CloudWatch Logs Insights or Athena to forecast demand.
For example, if certain logs spike monthly, scheduled restores can be timed preemptively. AWS telemetry tools like QuickSight ML Insights can detect anomalies and trigger alerts for advanced rehydration.
Policy-driven Automation
Use S3 lifecycle policies with tagging rules to automate restores based on log age or environment.
Example:
{
"Rules": [
{
"ID": "RehydrateHotLogs",
"Filter": { "Tag": { "Key": "env", "Value": "prod" } },
"Status": "Enabled",
"AbortIncompleteMultipartUpload": { "DaysAfterInitiation": 7 }
}
]
}Orchestration Tools
Use AWS Step Functions to manage multi-step workflows — retrieve, decompress, ingest, validate. Combine with S3 Batch Operations for bulk restores and integrate Lambda/SFN for retries and error handling.
API Integration
Use AWS CLI or SDKs for programmatic control:
aws s3api restore-object \
--bucket my-archive-bucket \
--key logs/2025-06-01.tar.gz \
--restore-request '{"Days":7,"GlacierJobParameters":{"Tier":"Standard"}}'Trigger these via CI/CD pipelines or monitoring systems for scalable rehydration.
Machine Learning
Use ML-based insights from tools like CloudWatch pattern detection or QuickSight anomaly forecasting to predict which logs will be accessed. Schedule rehydration during low-cost time windows to optimize usage.
Benefits and Limitations
Automating log rehydration streamlines operations and reduces manual effort. Key benefits:
- Faster incident response with event-driven restores
- Lower costs through predictive and tiered rehydration
- Less manual work via automated workflows
- Smooth CI/CD integration for DevOps teams
Potential drawbacks:
- Higher system complexity with multiple tools involved
- Unnecessary restores from noisy analytics
- Security risks without proper IAM and error handling
A balanced approach ensures efficiency without adding avoidable risks.
Future Trends and Considerations
As log rehydration continues to evolve, several emerging technologies and shifting landscapes promise to reshape how and when archived data is accessed:
1. AI-Powered Optimization
Current ML research explores using predictive models to intelligently pre-fetch and compress archive contents, optimizing retrieval speed and resource use. Early adopters leverage reinforcement learning in edge/fog environments to dynamically manage archived data workflows.
2. Edge Computing
With rising adoption of IoT and real-time systems, edge-based storage enables on-device or local cache rehydration. Gartner predicts 75% of enterprise data processing will occur at the edge by 2025. This distributed model reduces latency and cloud egress costs.
3. Real-Time Analytics
Platforms are increasingly embedding search and analysis layers that support querying cold or archived logs directly, lessening the need for traditional archive rehydration.
4. Quantum Storage
While still nascent, quantum-safe and DNA-based storage are being researched. These technologies could drastically increase archival density and durability, but practical rehydration tools are likely years away.
5. Regulatory Evolution
Compliance frameworks (e.g., GDPR, CCPA, PCI-DSS) increasingly demand granular auditability and immutable logs, driving rehydration practices toward fine-grained, query-triggered retrieval rather than bulk restores.
6. Cost Trends
Storage and compute pricing continue to evolve: cloud providers are introducing tiered cold storage with lower base costs, while computing costs are dropping. The result is tighter integration between storage economics and rehydration workflows.
Conclusion
Log rehydration plays a vital role in modern data management, enabling teams to retrieve archived logs efficiently for troubleshooting, compliance, and analytics. As organizations scale, a well-planned rehydration strategy ensures that archived data remains accessible without incurring unnecessary costs or latency.
Throughout this guide, we’ve covered key implementation considerations — from choosing the right tools and storage tiers to automating workflows with event-driven triggers, orchestration platforms, and predictive analytics. Whether you’re managing cloud-scale infrastructure or tightening compliance controls, the success of log rehydration depends on careful alignment between performance needs, budget constraints, and operational workflows.
Before deploying any solution, take time to evaluate your current log archival setup: which logs are stored, how often are they accessed, and which latency or cost targets matter most? A clear understanding of your use cases will guide smarter decisions.
Frequently Asked Questions
How long does log rehydration typically take?
Log rehydration can take anywhere from a few minutes to several hours, depending on the data volume, storage class (e.g., Amazon S3 Glacier vs. Standard), and retrieval method. Some platforms offer expedited retrieval for faster access.
What factors affect log rehydration costs?
Log rehydration costs depend on the volume of data retrieved, the storage class used (cold storage is cheaper to store but more expensive to access), retrieval speed (standard vs. expedited), and the duration the rehydrated data remains accessible. Usage fees from cloud providers and tooling overhead also add up.
Can I rehydrate only specific portions of archived logs?
Yes, many platforms let you rehydrate selected log segments based on time range, keywords, or log type. This reduces data transfer and minimizes rehydration costs.
What’s the difference between log rehydration and log backup restoration?
Log rehydration retrieves archived logs for analysis without affecting the system state. Backup restoration restores full systems or logs to recover from failure or data loss.
How do I choose between different rehydration tools and platforms?
Choose based on your storage provider, data volume, retrieval speed needs, supported filters, and integration with your observability stack. Cost, ease of use, and automation support also matter.
What happens to rehydrated data after analysis is complete?
After analysis, rehydrated data is usually deleted or moved back to cold storage to minimize costs, unless you configure it to stay accessible for ongoing monitoring or audits.
How can I automate log rehydration processes?
You can automate log rehydration using scheduled jobs, event-based triggers, or API integrations built into platforms like AWS, Azure, or observability tools.
What are the security considerations for log rehydration?
Security considerations include encrypting data in transit and at rest, controlling access with strict IAM policies, auditing rehydration activity, and ensuring sensitive logs aren’t exposed during retrieval or analysis.
References