


Modern applications generate such large amounts of log data that storing and analyzing every log entry is too expensive and impractical. By reducing the volume of logs, organizations can reduce storage costs and avoid overloading their log management systems. But how does one figure out which logs to drop, and which to keep?
Log sampling addresses this challenge by selecting a portion of log entries to record and analyze. This streamlined approach retains and analyzes critical log data, speeding query times and data processing. There are a number of sampling methods teams can implement to reduce their log volumes that can be static or dynamic and potentially intelligent in nature. Log sampling improves system performance, enabling faster issue detection and resolution without losing critical insights.
This guide will explore log sampling, covering its definition, benefits, usage scenarios, challenges, and best practices for effective implementation.
Key Takeaways- Reducing the overall volume of logs can help organizations save money on storage and avoid overburdening their log management systems.
- Log sampling is a technique for managing and optimizing log data that selectively retains a subset of log entries from a larger volume of logs.
- Log sampling can reduce the workload on log management and analysis systems, leading to substantial improvements in system performance.
- With fewer logs to process, a system can run more efficiently, resulting in faster query times and quicker access to critical information.
- Log sampling is valuable for ensuring system responsiveness in real-time monitoring scenarios.
- One of the most significant challenges of log sampling is the loss of detailed log data.
- Clear sampling criteria are essential to capture relevant log data for monitoring, troubleshooting, and analysis.
What is Log Sampling?
Log sampling is a technique for managing and optimizing log data. With this process, teams can selectively retain a subset of log entries from a larger volume of logs. Rather than aggregating every log entry, sampling chooses certain logs based on rules like time or events. This approach saves storage space, making log management easier while retaining crucial information.
With log sampling, organizations can:
- Reduce storage costs by reducing the amount of log data retained
- Improve system performance by reducing computational load to speed up log analysis
- Enhance data management by retaining only relevant data for monitoring, debugging, and compliance
Here’s an example of log sampling:
A web service with an endpoint interacts with a third-party service. If the service experiences an outage, the endpoint receives a thousand requests. Each of these requests fails and generates an error log.
This issue can happen in a conventional logging setup, which is excessive and redundant for analysis. With log sampling, teams only keep a subset of these logs instead of storing everything.
For instance, the web service team sets the system to collect only every tenth identical error log. This setup reduces the total number of stored logs to just 100. As a result, the team significantly reduces storage load and processing resources while providing a comprehensive view of the incident.
Here’s how log sampling typically works:
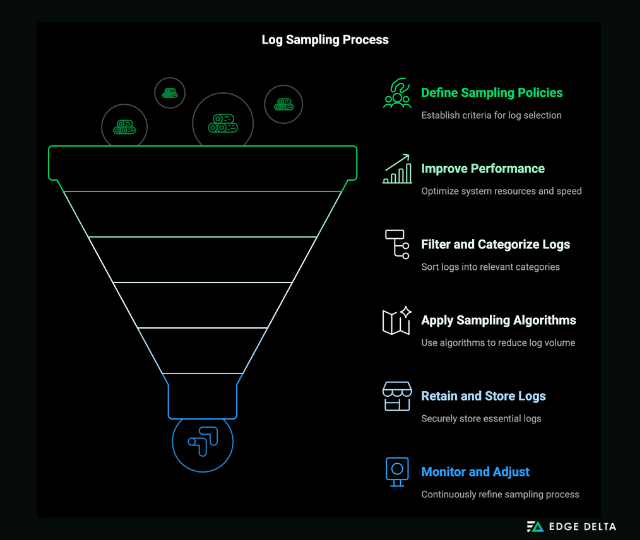
Step 1: Defining Sampling Policies
The first step is to set rules and determine which logs to keep. In rate-based sampling, you keep logs at a fixed rate, such as 1 out of every 100 logs.
Probabilistic sampling assigns a probability to each log entry, with each log having, for instance, a 1% chance of being kept. In rule-based sampling, you specify which logs to keep, such as errors or warnings, while sampling informational logs.
Step 2: Collecting Logs
Logs are collected from several sources, including application servers, databases, and network devices. This process can be facilitated using agents, log shippers, or custom scripts, ensuring comprehensive log data collection.
Step 3: Filtering and Categorizing Logs
Logs are filtered and categorized to prioritize critical information before sampling. Critical logs, such as those related to errors or security incidents, are often flagged to ensure retention. Logs may also be categorized by type, source, or severity level to streamline the sampling process.
Step 4: Applying Sampling Algorithms
Apply sampling algorithms to the incoming stream of logs. For rate-based sampling, select logs at regular intervals. In probabilistic sampling, a random process decides which logs to keep. Rule-based sampling evaluates each log against predefined criteria to decide whether to keep or discard it.
Step 5: Retaining and Storing Logs
Selected logs are retained and stored in a log management system or database, ensuring that essential data is available for analysis. Discarded logs are not stored, which helps reduce storage costs and processing requirements.
Step 6: Monitoring and Adjusting
The effectiveness of the sampling strategy is continuously monitored to ensure it meets system needs. Adjustments are made based on system performance, changes in log volume, and the need for specific log types, ensuring that the sampling strategy remains adequate and efficient.
Implementing these steps ensures effective log sampling, which has several benefits for organizations. The following section discusses these benefits.
Benefits of Log Sampling
An adequate log sampling allows organizations to selectively capture a subset of log data without sacrificing critical insights. As a result, this process offers the following benefits:
1. Reduced Storage Costs
Log sampling helps by keeping only some essential logs, saving money and space. With less data to store, organizations can save on storage infrastructure and associated costs, such as data retrieval and management.
To illustrate the cost benefits of log sampling, consider the following table showing a cost savings analysis with and without log sampling:
| Scenario | Total Log Data (TB) | Storage Cost per TB ($) | Total Storage Cost ($) |
|---|---|---|---|
| Without Log Sampling | 100 | 50 | 5,000 |
| With Log Sampling (10% sampled) | 10 | 50 | 500 |
2. Improved Performance
Log sampling can improve systems by reducing the load on log management and analysis tools. With fewer logs to process and analyze, monitoring and analysis functionalities work faster and better.
With fewer logs to process, these systems can operate more efficiently, leading to faster query times and quicker access to critical insights.
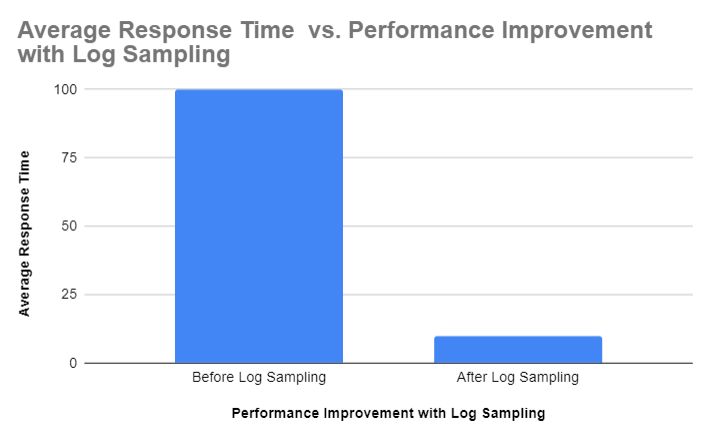
The following graph illustrates the performance improvements achieved through log sampling. It shows the average query response time before and after implementing log sampling.
3. Enhanced Data Analysis
Sampling allows you to focus on the most important or relevant logs for more efficient and effective data analysis. This process allows analysts to concentrate on essential logs by filtering out less critical entries. It also helps them understand the data better and make smarter decisions.
Teams can tailor sampling strategies to capture more error logs and fewer information logs, focusing attention on potential problems.
For instance, take a large e-commerce company that has faced issues analyzing its extensive log data. By implementing log sampling, and selecting only 10% of their logs to send downstream into their observability backends, they can significantly reduce data noise and ingestion costs while maintaining insight quality.
Solution:
The organization implemented a log sampling strategy, selecting only 10% of their log data for analysis.
Outcome:
Log sampling reduced storage costs by 70% and significantly improved system performance. Analysts could now focus on the most relevant data, resulting in more actionable insights and quicker issue resolution.
| Example Metrics | Average Query Time | Storage Costs |
|---|---|---|
| Before Sampling | 5 minutes | $10,000/month |
| After Sampling | 1 minute | $3,000/month |
By using log sampling, the organization improved its system for managing logs. This change made the system cheaper to run and work better.
When To Use Log Sampling?
Sampling is an effective log parsing practice to implement. While it isn’t practical, it’s crucial in some cases. The following cases show when it is beneficial and necessary for efficient and effective log management.
1. High Volume Log Environments
Log sampling is a strategic approach to managing many logs created in different environments. It reduces the number of logs by selecting specific ones based on set rules or randomly over time.
For instance, log sampling helps monitor user activity and system performance for high-traffic websites like social media and e-commerce. It allows them to understand essential events without overloading their log systems.
Telecommunications networks also use log sampling to track network performance. This method helps them focus on key performance indicators without storing too much data.
Financial institutions use log sampling to find important transaction patterns and security events. This practice helps them meet regulatory requirements and improve security without storing unnecessary data.
2. Resource-Constrained Environments
Since log sampling lowers the cost and size of storing data, it’s crucial for environments like the ones small businesses run, or edge computing run on lightweight hardware with limited resources. This approach also speeds up log management for faster insights and better performance.
Log sampling also accelerates log management tool insights and queries. It helps organizations with limited resources manage and analyze their log data effectively by balancing the need for close monitoring and the limits of what can be stored and processed.
For example, a busy e-commerce site with a tight budget uses log sampling to manage large data volumes. The site saves on storage and processing costs by focusing on a smaller set of logs. Log sampling also helps the site check key areas in real-time, spot issues quickly, and maintain a secure experience.
3. Real-Time Monitoring Needs
Log sampling is valuable for maintaining system responsiveness in real-time monitoring scenarios. By reducing data volume, log sampling also lessens the burden on processing resources, enabling faster and more efficient data analysis. This practice maintains real-time or near-real-time monitoring without system overload.
Here are the primary reasons to use log sampling for real-time monitoring:
- Managing High Log Volumes: Real-time systems often generate vast amounts of log data, which can overwhelm monitoring tools if processed in full. Log sampling helps by processing only a subset of the logs, thus preventing system overload and ensuring continued responsiveness.
- Optimizing Performance: Sampling conserves resources by reducing the number of logs processed, allowing the monitoring system to operate efficiently. This process ensures that critical alerts and insights are delivered immediately, which is essential for real-time operations.
- Improving Cost Efficiency: Storing and analyzing large volumes of log data can be expensive. Log sampling reduces these costs by limiting the amount of data handled, making real-time monitoring more economically viable without significantly sacrificing insight quality.
- Managing Dynamic Environments: In environments with frequent updates and changes, log sampling enables the system to adjust the sampling rate based on current load and performance requirements. This flexibility helps maintain optimal performance even during peak log generation periods.
- Detecting Anomalies: Focusing sampling on logs that are more likely to contain crucial information can improve the effectiveness of anomaly detection in real-time systems. This targeted approach helps promptly identify and respond to issues.
Here are the benefits of log sampling in real-time monitoring:
- Improved Responsiveness: Ensures that monitoring systems remain fast and responsive by reducing the data processing load
- Better Scalability: Enables the monitoring infrastructure to scale efficiently by managing resources better
- Significant Cost Reduction: Lowers storage and processing costs, making it feasible to maintain real-time monitoring
- Enhanced Focus on Critical Data: Allows prioritization of logs likely to contain significant events or anomalies
By thoughtfully implementing log sampling, real-time monitoring systems can achieve a balance between maintaining high performance, managing costs, and noticing critical insights.
Scenario: Financial Trading Platform Using Log Sampling for Real-Time Monitoring
Financial trading platforms generate millions of log entries per minute, especially during market opening. These logs provide insights into customer interactions. Thus, analyzing these logs in real time is crucial for the platform to detect potential upsell opportunities and service issues.
The issue is that processing this massive amount of logs can overwhelm a system. As a result, these platforms can encounter delays in issue detection and a spike in operational costs.
Sampling Strategy
- Targeting Deviations: Focus on logs that show deviations from normal behavior, such as repeated login failures or unusually high transaction volumes.
- Selective Capturing: Apply sampling to capture only the most relevant logs likely to indicate potential issues or opportunities.
Result
- Real-Time Alerts: Log sampling enables immediate alerts to customer service teams for action on service issues or upsell opportunities, enhancing overall customer satisfaction.
- Improved Security: Focusing on suspicious activities enhances detection and response times to security threats, maintaining a secure trading environment.
- System Responsiveness: Sampling ensures that the monitoring system remains responsive by reducing the volume of data processed, maintaining system performance, and reducing operational costs.
By implementing log sampling, the platform can efficiently monitor critical customer interactions, promptly addressing issues and opportunities without compromising performance or incurring high costs. This approach ensures high customer satisfaction and security in a high-stakes trading environment.
Challenges of Log Sampling
Organizations use log sampling to cut storage costs and improve data processing efficiency by selectively recording a subset of logs. However, this approach involves several challenges that can significantly impact data quality and analysis outcomes, such as the following:
1. Loss of Granular Data
When only a subset of logs is retained, critical information that could be vital for troubleshooting, security analysis, or performance optimization may be missed. The absence of granular data can hinder comprehensive analysis and lead to incomplete insights.
Here’s a table comparing full logs and sampled logs in terms of data granularity:
| Aspect | Full Logs | Sampled Logs |
|---|---|---|
| Data Completeness | High | Medium to Low |
| Troubleshooting Accuracy | Detailed insights available | Potential gaps in data |
| Performance Analysis | In-depth | Limited scope |
| Storage Requirements | High | Reduced |
| Processing Time | Longer | Shorter |
2. Bias in Sampled Data
If log sampling isn’t done correctly, specific events or patterns may be underrepresented, leading to incorrect conclusions. This bias can be particularly detrimental in security monitoring, where detecting anomalies is crucial.
Here’s a list of how bias-sampled data can affect analysis results:
Misleading Metrics
Distorted averages and rates from underrepresented error logs can give a false sense of reliability, leading to overlooked vulnerabilities. Skewed data also results in inaccurate KPIs, causing resource misallocation and ineffective performance improvements.
Faulty Trend Analysis
Incorrect trends from biased samples lead to flawed predictions and missed critical shifts. Misguided optimizations focus on less critical areas, neglecting significant issues due to skewed data.
Incomplete Diagnostic Information
Missed anomalies from incomplete sampling delay issue identification and resolution, increasing failure risk. Lost contextual information complicates root cause analysis and problem-solving.
Security Risks
Undetected security incidents from unsampled logs lead to prolonged threat exposure, compromising system integrity. Incomplete logs hinder forensic analysis, leaving vulnerabilities unaddressed and increasing future incident risk.
Compliance and Audit Issues
Regulatory non-compliance leads to incomplete logging due to biased sampling, risking fines and penalties. Failed audits caused by incomplete data damage reputations and lead to financial and legal repercussions.
Consider this scenario where bias in sampled data impacts security monitoring:
Teams that monitor network traffic samples every 10th log entry to save storage space. However, the sampling method skips over logs from specific IP addresses because they appear less frequently. This accident might lead the teams to miss critical signs of malicious activity from those addresses. As a result, some cyberattacks could go undetected, posing a significant network security risk.
3. Complexity in Implementation
Implementing an effective log sampling strategy requires a careful balance between reducing data volume and maintaining sufficient detail for analysis. Further, sampling rates, selection criteria, and ensuring representative samples complicate the implementation process.
Here’s an example of how complex an implementation is:
A corporation faced significant challenges while implementing a log sampling strategy. Initially, the company adopted a random sampling method to reduce log volume. However, this approach led to the missed detection of critical security events.
The team then moved to a stratified sampling technique, which required extensive configuration and tuning to capture all relevant data patterns. The implementation process took several months, involving continuous adjustments and monitoring to achieve the desired balance between data reduction and analysis accuracy.
By comprehending and tackling these obstacles, businesses may develop more effective log sampling strategies that minimize data loss, reduce bias, and handle the complexities of implementation. Tools like Edge Delta’s Visual Pipeline Builder are crucial for helping teams implement intelligent sampling strategies on their log data, allowing them to test their changes before deploying to production in an easy to use interface.
Best Practices for Log Sampling
As systems generate vast amounts of log data, sifting through every entry can be impractical and resource-intensive. By adopting best practices in log sampling, organizations can focus on a representative subset of logs that reflect critical events and patterns.
Consider the following practices to ensure an effective log sampling implementation:
1. Defining Sampling Criteria
Clearly defining sampling criteria is just as essential to ensure that relevant log data is captured for monitoring, troubleshooting, and analysis. Effective log sampling criteria can help:
- Improve Performance: Reducing the volume of logs to be processed and stored
- Ensure Relevance: Capturing the most relevant logs to provide meaningful insights
- Reduce Costs: Lowering storage and processing costs by focusing on essential logs
- Detect Issues: Focusing on high-priority logs to ensure timely detection of critical issues
Below is a table listing possible sampling criteria for log data and their purposes:
| Criterion | Purpose |
|---|---|
| Severity Level | Focuses on capturing logs with specific severity levels (e.g., errors, warnings) to monitor critical issues |
| Source Type | Captures logs from specific sources (e.g., application servers, databases) to target areas of interest |
| Time Interval | Samples logs generated within specific time frames to analyze time-based patterns or issues |
| Event Frequency | Takes log samples based on the frequency of events, ensuring high-frequency or rare events are captured as needed |
| Random Sampling | Captures a random subset of logs to get a general overview without bias |
| Stratified Sampling | Ensures logs from different sources or severity levels are proportionately represented |
| Threshold-Based | Samples logs that meet specific thresholds (e.g., response time, error rate) to focus on performance issues |
| User Activity | Captures logs related to specific user activities to analyze behavior and usage patterns |
| Geographical Region | Focuses on logs generated from specific geographical locations to monitor region-specific issues |
| Transaction Type | Captures logs related to specific transaction types (e.g., financial transactions, API calls) to monitor critical operations |
Defining and applying clear log sampling criteria is crucial for maintaining an efficient, cost-effective, and insightful log management system.
2. Balancing Sample Size and Accuracy
Balancing sample size with the need for accurate data is crucial for effective monitoring and diagnostics. Larger samples improve log sampling’s ability to spot significant patterns. They also improve sample representation and reduce error, resulting in more accurate results.
However, balancing sample size and accuracy in log sampling involves several trade-offs:
- Precision vs. Feasibility: While a larger sample size offers more precise estimates, it can be impractical due to increased time, costs, and resource requirements.
- Risk Tolerance: Smaller sample sizes might be acceptable if your risk tolerance is higher. This practice would allow for larger margins of error and lower confidence levels.
Effectively balancing sample size and accuracy involves employing various log sampling techniques such as:
- Fixed-Rate Sampling: Logs are sampled at a fixed rate, such as 1 out of every 10 logs. This method is simple but may adapt poorly to varying log volumes.
- Adaptive Sampling: The sampling rate adjusts dynamically based on the current volume of logs or system load. This method optimizes resource usage and captures critical logs during peak times.
- Random Sampling: Logs are randomly selected based on a predetermined probability. This method ensures unbiased sampling but might miss infrequent but significant events.
- Rule-Based Sampling: Logs are sampled based on specific criteria or rules, such as always collecting error logs while sampling informational logs. This method ensures necessary logs are always collected.
- Time-Based Sampling: Logs are sampled based on time intervals, like collecting logs for 1 minute out of every 10 minutes. This method can reduce data volume while still capturing trends over time.
Here is a graph illustrating the trade-off between sample size and data accuracy.
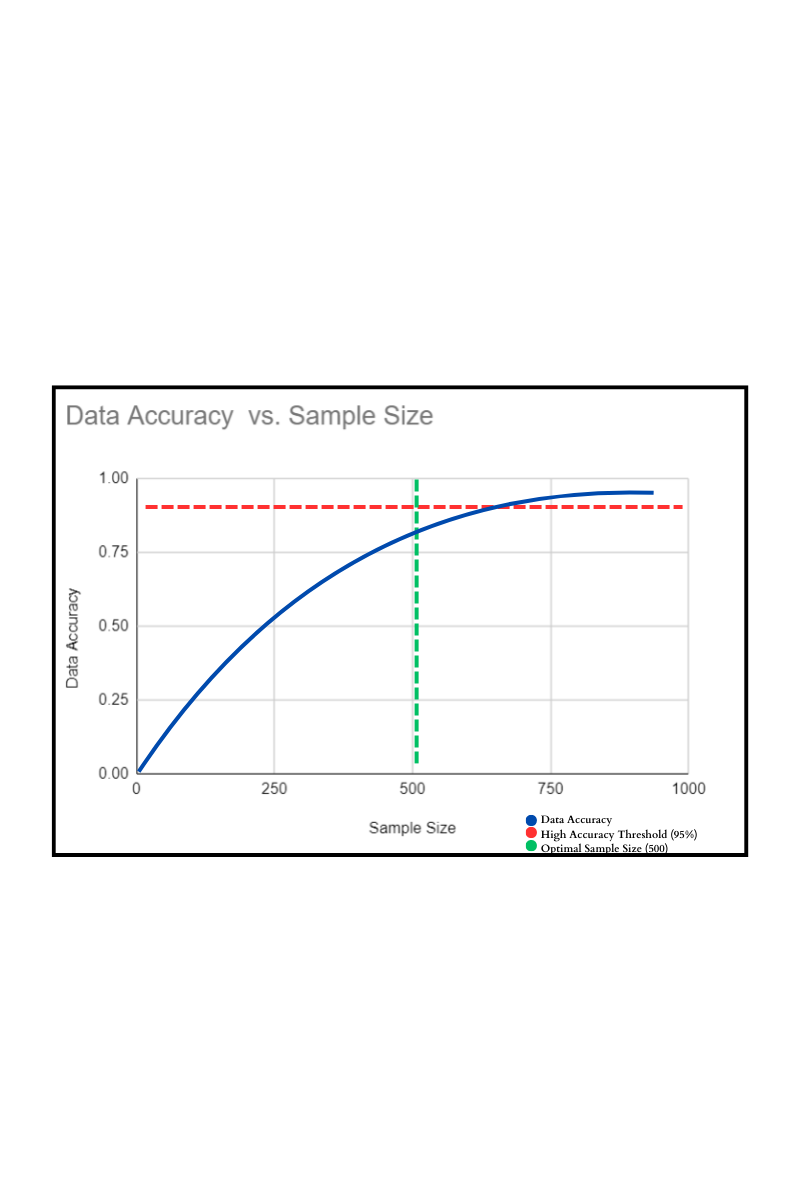
As the graph indicates, as sample size increases, the accuracy of the data improves. After a certain point, the rate of improvement slows down. This illustration shows how important it is to balance sample size and the ease of gathering data. The graph shows the best sample size to get a good result without spending too much on unnecessary resources.
3. Automated Sampling Techniques
Automated log sampling techniques offer numerous advantages that help maintain consistency and efficiency in log management. Here are some key benefits:
- Consistency: Automated sampling ensures that logs are collected uniformly across all systems and environments, reducing the likelihood of human error and bias. This consistency is essential for precise analysis and dependable results.
- Scalability: Manually managing logs becomes impractical as systems grow in complexity and volume. Automated techniques can effortlessly scale to handle large volumes of data, ensuring comprehensive coverage without overwhelming resources.
- Efficiency: Automation reduces the time and effort required to manage log sampling, allowing IT teams to focus on more critical tasks. It also speeds up identifying and addressing issues, leading to quicker resolutions.
- Real-Time Analysis: Automated log sampling enables real-time data collection and analysis, providing immediate insights into system performance and potential issues. This approach helps in early detection and mitigation of problems.
- Cost-Effectiveness: Automated sampling can significantly reduce storage and computational costs by reducing the volume of logs stored and processed. This efficient resource utilization translates into financial savings.
- Adaptability: Automated systems can be configured to adjust sampling rates based on predefined criteria, such as peak traffic times or specific events. This adaptability ensures that critical logs are captured when they are most needed.
4. Regular Review and Adjustment
Log sampling strategies must be reviewed and adjusted regularly to stay current and meet system and organizational needs. This continuous refinement helps maintain an optimal balance between data volume, resource utilization, and monitoring efficacy.
Here’s a checklist to guide you through this process:
| Step | Action |
|---|---|
| 1. Define Objectives | Identifying crucial metrics and setting performance baselines |
| 2. Analyze Log Volume | Measuring current log ingestion rates and checking storage utilization |
| 3. Review Sampling Policies | Verifying sampling criteria (e.g., rate, type) and ensuring sampling frequency to meet monitoring needs |
| 4. Optimize Log Collection | Removing unnecessary log entries and combining similar log entries |
| 5. Adjust Sampling Strategies | Modifying sampling rates based on importance and volume and using dynamic sampling to adjust rates in real-time |
| 6. Validate Effectiveness | Ensuring sampled logs are representative and verifying the effectiveness of alerts |
| 7. Regular Review | Scheduling periodic reviews and incorporating stakeholder feedback |
Conclusion
Log sampling is a practical approach to managing extensive log data. When implemented effectively, it optimizes resources, improves performance, and reduces storage costs. However, sampling can also lead to losing detail, biases, and setup complications. Thus, it is crucial to employ proper log sampling techniques and address the typical challenges to find the proper balance between sample size and data accuracy.
A better alternative approach is to leverage observability tools architected to analyze massive log volumes. For instance, you can use Edge Delta to optimize log data without compromise. Rather than selecting specific logs to drop, you can leverage Edge Delta’s intelligent compression functionalities to extract metrics or patterns from log data as it’s created, optimizing data volumes without sacrificing any visibility.
With this approach, you won’t miss any crucial data, even if it’s only temporarily significant. These patterns and insights will only take up little space, saving you from expensive storage and other related costs.
FAQs on What is Log Sampling
What is log sampling?
Log sampling is the process of selecting a subset of log data collected from a system or application and extracted from a larger dataset.
What are some different methods of log sampling?
Methods of sampling include random sampling, time-based sampling, event-based sampling, error-based sampling, and rate-limited sampling.
What is the sample rate?
The sample rate is the frequency or proportion at which log entries are selected and recorded from the total log data generated by a system.
What do you mean by data logging?
Data logging enables recording activity on one or more data/file objects or sets. It also facilitates the storage and collection of computer or device information.
Sources:
- BetterStack
- Observiq
- New Relic
- Dynatrace
- Whylabs
- Queue
- Splunk
- Tech Target
- Aporia
- Relevant insights
- Biotage
- Sematext
- Crowdstrike
- BetterStack
- Techopedia

