


AIOps is often introduced as a way to reduce alert noise or help operations teams work faster. Those benefits are real, but they are not the core reason AIOps exists. The deeper problem AIOps addresses is that modern systems generate more operational signals than humans can reliably interpret, especially during incidents.
In distributed environments, failures rarely appear as a single, obvious error. They surface as patterns across metrics, logs, traces, events, and recent changes. Teams are expected to recognize those patterns quickly, decide what matters most, and act without increasing risk. That expectation no longer scales on human effort alone.
An AIOps strategy provides structure where complexity would otherwise dominate. It defines how operational data becomes reliable decisions. Without a strategy, AIOps produces output. With one, it produces clarity.
Key Takeaways
• AIOps is about faster understanding, not just fewer alerts. Its core job is reducing uncertainty during incidents, not simply cutting noise.
• Strategy turns AI output into trusted action. Without clear outcomes, standards, and ownership, AIOps insights don’t stick.
• Correlation is the foundation. Grouping related signals must come before anomaly detection or automation.
• Consistent data and service identity are required. Without shared semantics and ownership, correlation breaks down.
• AIOps succeeds as an operating model, not a tool. Governance and iteration matter more than feature depth.
What an AIOps Strategy Is and What It Is Not
AIOps is frequently described as “AI for IT operations,” but that framing hides the most important distinction.
AI can generate insights. Strategy determines whether those insights are trusted, acted on, and improved over time as systems face continued growth in production data volume and complexity.
Gartner defines AIOps as the application of machine learning and analytics to IT operations data for event correlation, anomaly detection, and causality determination.
That definition is useful because it focuses on outcomes rather than interfaces or tooling. It also implies that AIOps is a system, not a feature.
A strong AIOps strategy answers four foundational questions early:
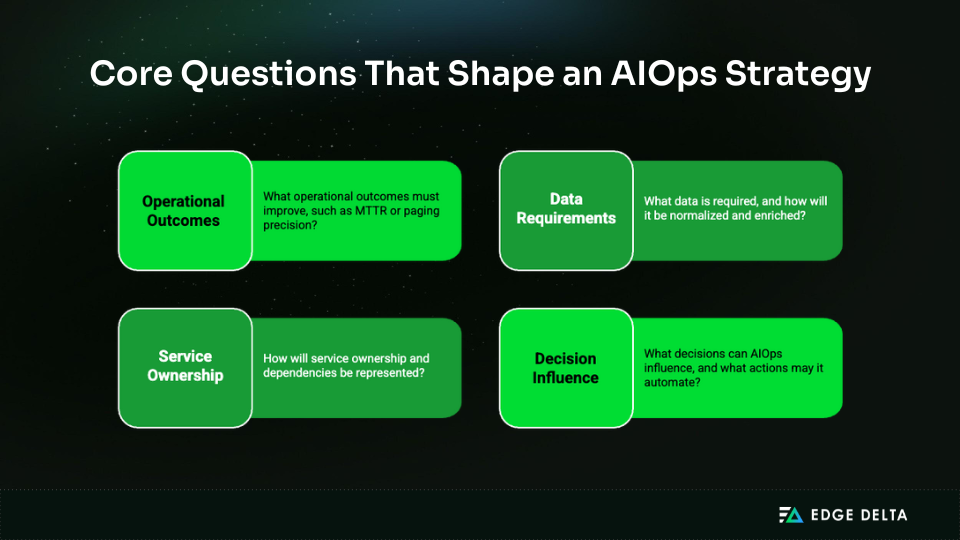
When these questions are unanswered, AIOps efforts drift. Teams deploy AI-powered capabilities, but incident response remains chaotic. Strategy is what turns potential into reliability.
Defining AIOps in Operational Terms
To understand AIOps, it helps to look at how incident response actually unfolds. When an outage occurs, responders rarely lack data. Instead, they face too much of it.
Metrics show symptoms. Logs show fragments of failure. Traces reveal partial execution paths. Alerts fire independently across services.
The first challenge is not fixing the problem. It is understanding what the problem actually is.
AIOps exists to reduce that ambiguity. It does so by grouping related signals into incident candidates, highlighting abnormal behavior within those groups, and narrowing likely causes so responders can focus their investigation.
AIOps Definition: Correlation, Anomalies, and Causality
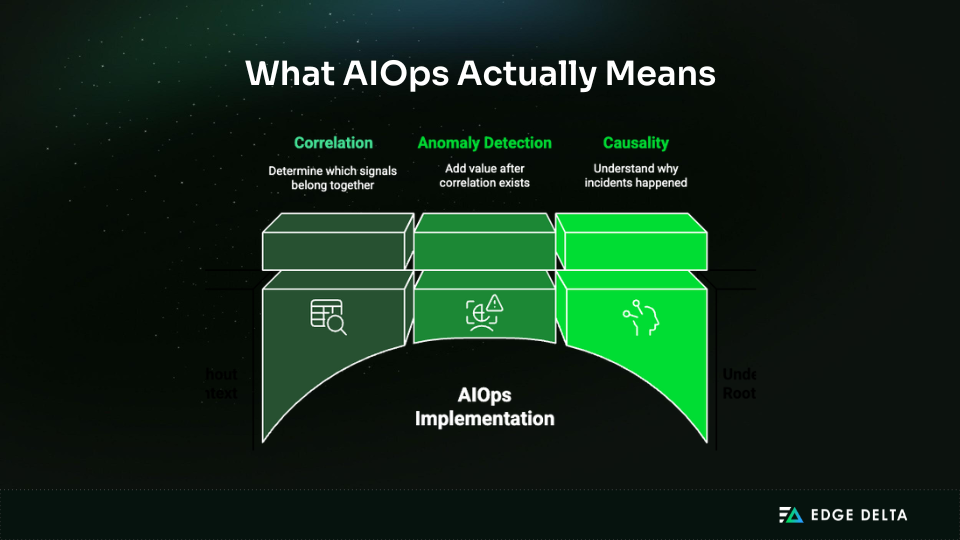
Correlation is the foundation. It determines which signals belong together and which do not. Anomaly detection adds value only after correlation exists, because anomalies without context often increase noise. Causality is the long-term goal, helping teams understand not just what is wrong, but why it happened.
This sequencing matters. Many AIOps initiatives start with anomaly detection because it looks sophisticated. Correlation and causality are what actually shorten incidents, because they support the moment when responders are asking what to do next.
Multi-Signal Correlation Across Metrics, Logs, Traces, Events, and Changes
Real incidents span multiple telemetry data types. Metrics reveal impact. Logs expose failure modes. Traces show where requests stall. Events capture state transitions. Change data often explains why an incident began.
Ignoring any of these creates blind spots. In practice, missing change data is one of the most common reasons incidents take longer than necessary to resolve. AIOps strategies that treat deployments and configuration changes as first-class signals consistently reduce time-to-understanding.
What AIOps Is Not
AIOps does not replace good instrumentation, clear ownership, or incident management discipline. It amplifies those practices when they exist and exposes gaps when they do not. That is why setting boundaries is just as important as defining capabilities.
What AIOps Is Not: Chatbots, Dashboards, and Isolated Tools
Chatbots can summarize information, but they cannot establish truth when telemetry data is inconsistent. Dashboards visualize the state but do not decide what deserves immediate attention. Isolated AI features can optimize within a single tool but cannot explain incidents that span services and teams.
AIOps should be judged by the quality of the incident narratives it produces. If the system cannot reliably answer what is happening, why it matters, and who should act, it is not functioning as AIOps.
Why You Need an AIOps Strategy
Organizations rarely adopt AIOps because they want AI. They adopt it because operational uncertainty becomes expensive. Alert noise increases. Response slows. Mistakes multiply under pressure.
The real cost driver is not delayed detection. It is a delayed understanding.

Downtime Is Expensive, and Uncertainty Is the Multiplier
Uptime Institute research shows that more than half of organizations report outages costing over $100,000, with roughly one in five exceeding $1 million. In many cases, the outage itself was detected quickly. What took time was determining scope, impact, and cause.
An AIOps strategy directly targets this uncertainty window, where costs escalate fastest. Faster understanding reduces duration, escalation, and secondary damage.
Alert Fatigue and Toil Reduce Reliability over Time
Alert fatigue is not just frustrating. It changes human behavior, which is why automated alert analysis should focus on actionability rather than volume. When pages are frequent and often irrelevant, responders delay or ignore them. This raises the risk of missing critical signals.
Operational toil compounds the issue. Google’s SRE research defines toil as repetitive, automatable work that produces no enduring value. When teams spend most of their time reacting, they lose the capacity to fix underlying issues.
An effective AIOps strategy aims to reduce both noise and toil so reliability improvements can compound.
SLO-Based Alerting Improves AIOps Signal Quality
Before using AI on a large scale, it’s important to prepare telemetry data using intelligent pipelines because AIOps systems and specialized AI agents are only as good as their inputs.
Alerting based on raw thresholds often floods systems with low-value signals. SLO-based alerting ties pages to user impact and error budget consumption, improving signal quality.
SLOs let AIOps correlation focus on what’s truly crucial by connecting alarms to risk instead of merely internal measurements. This method lowers the number of false positives while still finding real outages.
The Core Pillars of an AIOps Strategy
AIOps succeeds when its foundations are deliberate. The most effective strategies share four reinforcing pillars.
Outcome-Driven Success Metrics
Metrics assess if AIOps will be a long-term capability or simply a temporary pilot. The most important indicators are those that look at results, not actions:
- Mean time to resolution for critical services
- Paging actionability, measured by how often pages lead to action
- Reduction in operational toil over time
These metrics should be baselined before implementation and tracked at the service level.
Data Normalization and Semantic Consistency
Correlation depends on shared meaning. When teams label services, environments, or errors differently, analytics turns into guesswork. OpenTelemetry semantic conventions exist to prevent this problem by standardizing telemetry descriptions across systems.
An AIOps strategy typically defines a minimal telemetry contract that includes service naming rules, environment labels, ownership metadata, and change identifiers. This is often enforced through modular processing patterns in the pipeline rather than one-off rules.
Service Identity and Ownership Context
A solid service identity is necessary for AIOps to work. Signals must always point to the same logical service, no matter what tools or settings they are in. Ownership context helps guarantee that correlation outputs lead to action instead of confusion.
Operating Model and Governance
AIOps influences action, which makes governance essential. Someone must own correlation rules, automation boundaries, and system accuracy over time. Without ownership, trust erodes as systems evolve.
Reference Architecture for Implementing AIOps at Scale
An AIOps architecture does not need to be complex to be effective. It needs to be intentional.
Data Ingestion and Unification
Visibility across metrics, logs, traces, events, and change signals is required to explain incidents. Partial visibility creates false confidence and slows triage.
Normalization and Enrichment
Normalization makes telemetry comparable. Enrichment makes it actionable. Ownership, environment, version, and recent change context reduce triage time even before advanced analytics are applied.
Intelligence and Analytics
Correlation should come first, anomaly detection second, and causality last. This sequencing mirrors how humans investigate incidents and produces outputs that are easier to trust.
Decisioning and Automation
Automation should follow a maturity curve, starting with suggestions and only growing when the risks are clear and the verification process is dependable. This is often made possible by AI systems that operate together and keep humans involved.
How to Implement an AIOps Strategy at Scale
Implementing AIOps at scale is not about deploying a platform everywhere at once. It is about creating a repeatable operating pattern that holds up as services multiply and systems evolve.
The defining trait of successful AIOps programs is consistency of outcomes, not speed of rollout.
Phase 0: Readiness and Baselining
Start by picking a limited number of critical services, and establish baselines for the mean time to resolution, the number of pages per incident, the number of times an issue must be escalated, and the percentage of incidents related to recent modifications. This helps everyone comprehend what’s going on right now.
Phase 1: Data Standards and Semantic Normalization
Define and enforce minimal standards for service identity, environment labeling, ownership, and change tracking. Enforcement matters more than documentation. Instrumentation guidelines and CI/CD checks are more effective than policy pages.
Phase 2: Noise Reduction and Correlation
With consistent data in place, reduce noise safely. Focus on forming credible incident candidates rather than suppressing alerts. Success is measured by whether responders agree that pages represent real issues worth acting on.
Phase 3: Guided Triage and Change Correlation
Make sure to link incidents to deployments, configuration changes, feature flags, and dependency updates. This speeds up the investigation process and shifts conversations about incidents from speculation to proof.
Phase 4: Automation with Guardrails
Introduce automation only for low-risk, reversible actions. Require explicit preconditions, bounded blast radius, verification, and rollback. Expand automation only when evidence shows it reduces resolution time without increasing severity.
Phase 5: Governance and Continuous Improvement
Make ownership, review cycles, and feedback loops official. As the system changes, correlation rules and automation assumptions must also change. Governance makes sure that AIOps gets better slowly instead of failing all at once.
Implementation Roadmap at a Glance
| Phase | Primary Goal | What You Deliver | What You Measure | Common Failure |
|---|---|---|---|---|
| Phase 0 | Define success | Baselines and service scope | MTTR, actionability | Vanity metrics |
| Phase 1 | Trustworthy data | Identity and semantics | Compliance rate | Optional standards |
| Phase 2 | Clear incidents | Correlation and deduplication | Page quality | Hidden failures |
| Phase 3 | Faster understanding | Change correlation | Time to likely cause | Missing change data |
| Phase 4 | Safe leverage | Guarded automation | Severity shifts | Premature automation |
| Phase 5 | Durability | Governance and reviews | Drift and accuracy | No ownership |
Common Failure Modes and How Strategy Prevents Them
Most AIOps failures follow predictable patterns. They are rarely caused by weak analytics; instead, they are caused by misalignment between data, context, and decision-making.
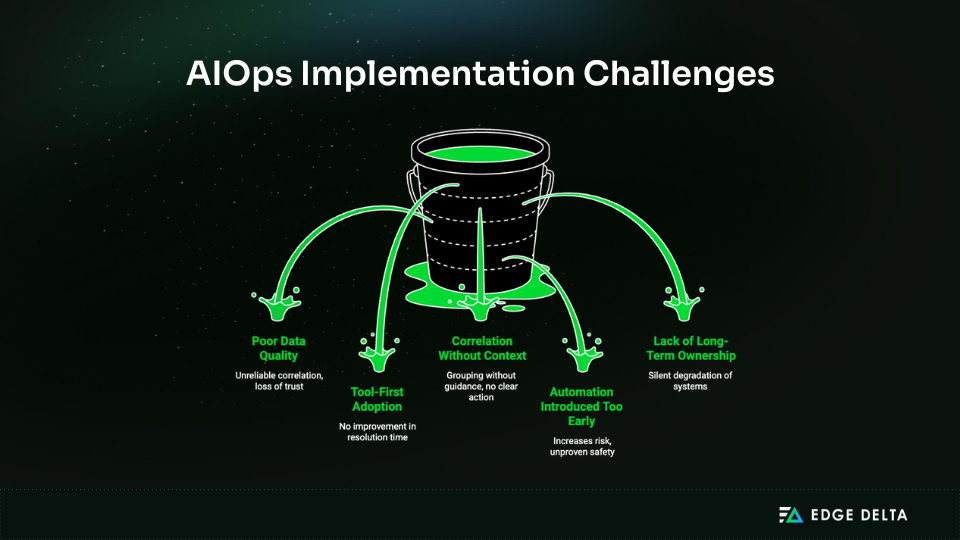
- Poor Data Quality and Inconsistent Service Identity – When services are labeled inconsistently, correlation becomes unreliable. Responders lose trust and revert to manual workflows. An effective strategy prevents this by treating identity and semantics as non-negotiable foundations.
- Tool-First Adoption Without Outcome Alignment – Adopting tools first makes dashboards and anomaly charts, but it doesn’t speed up resolution time or make a difference for customers. A good strategy ties every choice to measurable results, which stops people from feeling falsely confident.
- Correlation Without Context – Correlation without ownership or dependency context produces grouping without guidance. Context modeling is essential so responders know where to act, not just what is happening.
- Automation Introduced Too Early – Putting automation in place before correlation raises the risk. An effective strategy establishes a maturity curve, only allowing closed-loop activities in situations when safety and verification have been proved.
- Lack of Long-Term Ownership – Without ownership, AIOps systems degrade silently as environments change. A winning strategy treats AIOps as a production system with accountability, reviews, and continuous improvement.
Conclusion
An effective AIOps strategy isn’t about making operations “smarter.” It’s about making them more certain. By clearly defining outcomes, standardizing meaning across telemetry data, adding operational context, and governing automation, teams can turn overwhelming data volume into reliable, repeatable decisions.
When AIOps is treated as an operating model — not just a collection of tools — incident response becomes faster, calmer, and more predictable. That consistency is what makes AIOps scalable, and ultimately, what makes it worth investing in.
FAQs
What Is an AIOps Strategy?
An AIOps strategy defines how operational data is transformed into trusted decisions during incidents, including outcomes, data standards, context, and governance.
Why Do Many AIOps Initiatives Fail?
They start with tools instead of foundations. Without consistent identity, semantics, and ownership, correlation outputs are unreliable and adoption stalls.
Is AIOps Only for Large Enterprises?
No. Smaller teams often benefit earlier, but should focus on a narrow set of critical services rather than broad rollout.
When Is Automation Safe in an AIOps Program?
Automation is safest when actions are reversible, blast radius is bounded, verification confirms success, and governance enforces accountability.
Do You Need OpenTelemetry for AIOps?
You do not need OpenTelemetry specifically, but you do need consistent service identity and semantic conventions to make correlation reliable at scale.
Sources:

