


When it comes to data analytics on AWS, Amazon Athena and Amazon Redshift often come up in the same conversation, but they serve very different purposes. Athena is a fully serverless query engine that lets you analyze data directly from Amazon S3 with no need to manage infrastructure. Redshift, on the other hand, is a powerful, managed data warehouse designed for high-performance querying across massive datasets.
For fast, ad-hoc SQL queries on raw data, Amazon Athena is the ideal choice. But if your business depends on complex, structured analytics at scale, Amazon Redshift is built to deliver. The decision goes beyond performance, it’s about cost, scalability, and how your data is organized.
This guide covers the key differences between Athena vs Redshift, helping you choose the right solution for your data strategy.
Key Takeaways:
• Redshift is a high-performance data warehouse optimized for structured analytics, while Athena is a serverless query service that analyzes data directly in S3.
• Complex queries run faster on Redshift, thanks to its MPP architecture, whereas Athena excels at quick, on-demand analysis but struggles with large workloads.
• Athena is more affordable for occasional use with pay-per-query pricing, while Redshift is better for frequent, high-volume queries due to its fixed pricing.
• Businesses looking to analyze logs and get quick insights should use Athena. In contrast, Redshift is best for business intelligence and processing large amounts of data.
• Both platforms have strong security. However, Redshift offers better access controls and works more smoothly with business intelligence (BI) tools.
Comparing Athena vs Redshift: 7 Key Aspects
Before getting into the details, let’s first highlight the key differences between Amazon Athena and Amazon Redshift. Here’s a quick comparison of their performance, cost, scalability, and use cases to help you decide:
| Features | Athena | Redshift |
|---|---|---|
| Architecture | Serverless, queries data directly from S3 | Cluster-based, dedicated data warehouse |
| Query Engine | Presto (SQL-based) | PostgreSQL-based |
| Best for | Ad-hoc queries on raw S3 data | Large-scale structured data analytics |
| Cost Model | Pay-per-Query ($5 per TB scanned) | Hourly/per-node pricing (cheaper for high query volumes) |
| Performance | Slower for complex queries | Optimized for high-speed analytics |
| Scaling | Automatically scales with workload | Manual cluster resizing (with concurrency scaling) |
| Security | IAM & S3-based encryption | VPC-based security, encryption at rest & in transit |
| Use Cases | Data lake analytics, log analysis, on-demand queries | BI reporting, data warehousing, complex analytics |
1. Architectural Differences
Understanding the underlying architecture is crucial when selecting between Athena and Redshift since it affects query speed, data storage, cost, and ease of use. If you use a poor architectural fit for your use case, you can encounter unexpected expenses and performance issues.
Amazon Athena Runs with a Serverless Architecture
Athena operates on a serverless architecture, and takes out the need for users to provision or manage infrastructure. It’s ideal if you want to focus on querying data without worrying about backend maintenance.
- Serverless Query Execution: Athena runs queries directly on data in S3, eliminating the need for data movement or transformation.
- Presto-Based Query Engine: Athena uses Presto, an open-source distributed SQL engine, to handle large-scale data analytics efficiently.
- Schema-on-Read: Instead of requiring predefined schemas, Athena applies schemas during queries, making it flexible for different data formats.
Amazon Redshift Works with a Cluster-Based Architecture.
Redshift is a fully managed, cluster-based data warehouse, whereas Athena operates without clusters. Therefore, its architecture allows the following functions:
- Cluster-Based Data Warehouse: According to recent Redshift’s design, it represents data due sets in a column-oriented system, being a cluster-based solution that stores data in a distributed way on multiple nodes, allowing for greater storage and query efficiency.
- Massively Parallel Processing (MPP): Redshift can execute queries in parallel across multiple nodes using MPP to improve performance for complex analytical workloads.
- Schema-on-Write: Redshift needs an initial schema blueprint. This feature guarantees data integrity and consistency by requiring predefined schemas during data ingestion.
2. Performance
A sluggish system can bottleneck decision-making, increase operational costs, and hinder real-time analytics. When choosing a data analytics tool, checking the performance is crucial. The right choice depends on the workload type, query complexity, indexing strategies, and data optimization techniques.
Amazon Athena Provides On-Demand Query Execution.
How you design your data affects the performance of Athena a lot. Using the right format, structuring it well, and scanning as little data as possible are not trivial things but go a long way. If you use a columnar format, such as Parquet, and segment your data well, you can improve the performance of queries and conserve resources.
Here’s the code before optimization:
sql
SELECT * FROM sales_data WHERE year = '2023';
This query scans the entire dataset, leading to high query costs.
Here’s a code after optimization that uses partitioning:
sql
SELECT * FROM sales_data WHERE year = '2023' AND region = 'US';
By adding partitioning on year and region, Athena scans only relevant partitions, reducing cost and improving performance.
However, since Athena queries data directly from Amazon S3, performance can be affected by network latency, and S3 read throughput. As a result, large and complex queries may experience slower execution times, unlike with dedicated data warehouses.
Amazon Redshift Offers High-Performance Analytics with MPP.
Redshift’s Massively Parallel Processing (MPP) architecture efficiently distributes tasks across multiple nodes, optimizing workload management and accelerating data processing.
Redshift can benefit from sort keys to enhance query speed:
sql
CREATE TABLE sales_data ( id INT, year INT SORTKEY, revenue DECIMAL(10,2) ) ;
With the year column as a SORTKEY, queries filtering by year run significantly faster.
Redshift demands cluster management but outperforms Athena in complex joins, aggregations, and analytical workloads.
3. Scalability
Scalable data platforms can handle growing workloads without sacrificing performance. As such, choosing a system that adapts as your data grows helps keep operations smooth and cost-effective.
Amazon Athena Offers Auto-Scaling Serverless Queries.
Athena’s serverless architecture offers automatic scaling. This function means there’s no need to manage infrastructure. It dynamically allocates resources based on query demand, making it ideal for ad-hoc analytics and unpredictable workloads.
| Scalability Advantages | Scalability Challenges |
|---|---|
| No manual provisioning, scales with demand. | Concurrency limits can slow down performance when multiple users query large datasets. |
| Cost-effective for on-demand queries. | S3 read throughput affects query speed at scale. |
| Ideal for intermittent or event–driven workloads. |
Amazon Redshift Runs with Cluster-Based Scaling.
Redshift scales by adding or removing nodes in a cluster. While this flexibility gives control over resources, it requires manual or elastic resizing for flexibility.
Here are some of the scaling options in Redshift:
- Elastic Resize: Quickly adjusts cluster size with minimal downtime
- Concurrency Scaling: Automatically adding compute capacity
- RA3 Nodes: Enabling independent scaling of compute and storage
Here’s how you can scale a Redshift Cluster:
sql
ALTER CLUSTER my_cluster RESIZE TO NODE TYPE ra3.4xlarge;
This command scales up the cluster to RA3 nodes. As a result, it allows independent storage growth without affecting performance.
Scalability Advantages
- Efficient if you have predictable, high-throughput workloads
- Cluster-based control enables fine-tuning of performance
- Supports large-scale data warehousing with petabyte-scale storage
Scalability Challenges
- Cluster resizing can cause temporary downtime unless elastic resizing is used.
- More expensive at scale compared to Athena’s pay-per-query model.
Athena is best if you need a serverless, on-demand solution that works mostly with semi-structured data. It’s also easy to achieve complete observability with this serverless architecture with the right process. But if you need high-performance analytics with structured data and control over scaling, Redshift is the way to go.
4. Cost Considerations
Since Athena charges per query, it’s budget-friendly for users with less workloads. But if you run complex queries often, Redshift’s fixed pricing could offer better value. Here’s a quick breakdown of their costs:
Athena Works Well With Its Pay-Per-Query Flexibility for Variable Workloads.
- Pay-per-Query model: Charging $5 per terabyte of data scanned
- Cost-effective for: Ad-hoc querying, exploratory analyzing, and fluctuating demand
- Serverless: Eliminating infrastructure management costs
- Cost optimization: Partitioning and optimized data formatting reduce scanned data
Redshift Offers Fixed-Cost Predictability for Consistent and Heavy Use.
- Cluster-based pricing: Charging based on provisioned node size and type
- Ideal for: Consistent, high-volume data warehousing and BI workloads
- Fixed cost: Incurring regardless of active querying
- Redshift Spectrum: Introduces per-Query costs for querying S3 data, similar to Athena
Pro Tip
For better cloud analytics cost management, explore this Guide on Cloud Cost Optimization to reduce expenses and enhance performance.
5. Best Practices and Use Cases
Choosing the right tool comes down to your workload and how you handle data processing. While both Amazon Athena and Redshift are powerful, they shine in different scenarios. Athena is a great choice for quick, serverless queries on structured data, while Redshift excels in complex analytics and large-scale data warehousing.
Best Amazon Athena Use Cases
Athena lets you query data quickly and easily without needing to manage servers. Thus, it’s a great option if you want fast insights with minimal setup.
1. Ad-Hoc and Exploratory Data Analysis
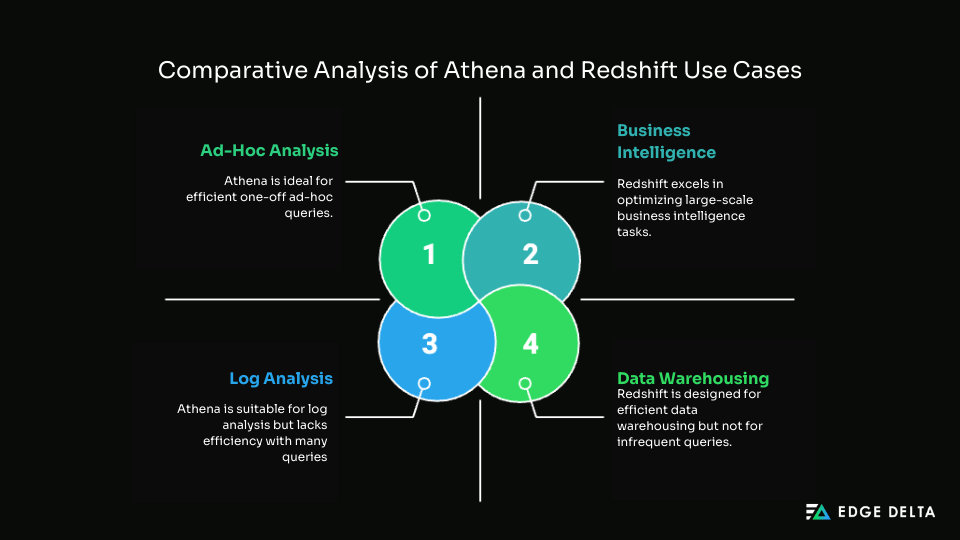
Athena is ideal for analysts who need to run one-off queries on raw data stored in Amazon S3. Since there’s no need for prior ETL (Extract, Transform, Load), users can immediately query structured or semi-structured data.
Example Use Case: A data analyst needs to check customer behavior trends from JSON logs stored in S3. Instead of setting up a database, they can run this code:
sql
SELECT customer_id, COUNT(*) AS total_purchases FROM s3_logs.customer_data WHERE purchase_date > '2024-01-01' GROUP BY customer_id ORDER BY total_purchases DESC LIMIT 10;
With this command, you can allow instant insights without data preprocessing or warehouse setup.
2. Log and Event Data Analysis
Forget the headaches of infrastructure management. Amazon Athena empowers organizations to analyze logs, clickstreams, and event data instantly. Its serverless architecture eliminates setup and maintenance burdens. As a result, it allows teams to focus on extracting meaningful insights.
Whether it’s tracking user behavior or detecting anomalies, Athena keeps your data-driven decisions agile and efficient.
3. Cost-Effective Querying for Lesser Analytics
Amazon Athena’s pay-per-query model removes infrastructure costs, making it ideal for infrequent queries. You pay only for the insights you need, ensuring cost efficiency.
Ideal For:
- Startups & Small Teams: Ideal for infrequent analytics without infrastructure overhead.
- On-Demand Historical Queries: Access past data without continuous processing.
- Analysts & Researchers: Explore large datasets without upfront costs.
Key Limitation: Not appropriate for high-concurrency complex joins or real-time processing. Redshift is the right choice there.
Best Amazon Redshift Use Cases
Redshift excels at high-performance, large-scale data processing, making it ideal for structured analytics, high concurrency, and fast queries. It’s especially useful in scenarios like:
1. Complicated Analytical Queries and Business Intelligence Management
Amazon Redshift is ideal for handling massive, structured datasets, particularly when you want to execute complex joins, aggregations, and analytics in depth. It’s a good starting point for creating BI dashboards, report generation and delving into deep analytics.
Redshift’s MPP design, for example, performs well when doing a customer risk analysis that requires quickly and efficiently processing billions of transactions. This allows you to easily run complicated queries when gathering essential information.
sql
SELECT customer_id, SUM(transaction_amount) AS total_spent FROM transactions WHERE transaction_date >= '2024-01-01' GROUP BY customer_id ORDER BY total_spent DESC LIMIT 10;
Redshift executes queries significantly faster than Athena, especially when DISTKEY and SORTKEY are properly configured.
2. Enterprise-Scale Data Storage
Amazon Redshift consolidates data from multiple sources into a high-performance repository, enabling:
- Fast Query Execution – Optimized for structured data, Redshift accelerates complex queries.
- Scalability – Dynamically adjusts compute capacity to maintain performance.
- BI Tool Integration – Connects with Tableau, Power BI, Looker, and more.
Best Practices:
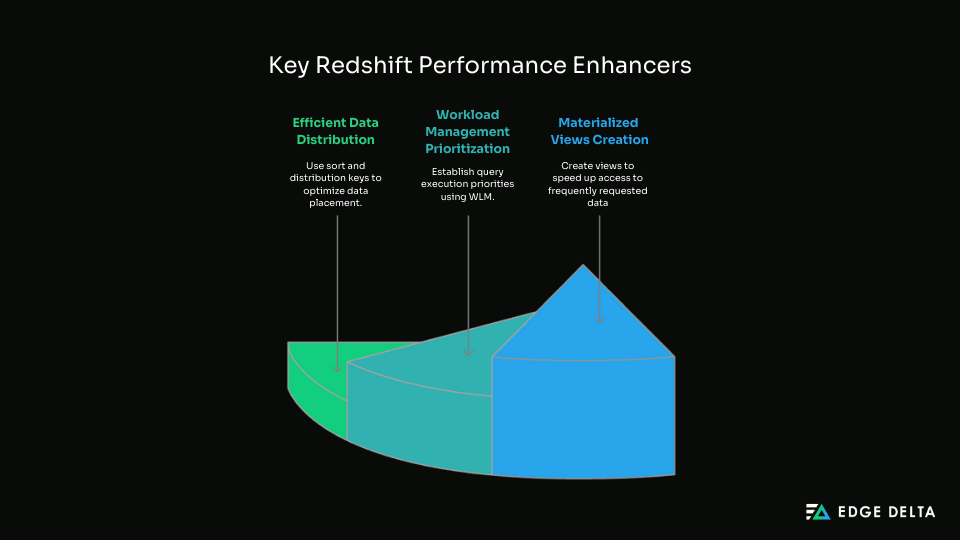
- Use DISTKEY and SORTKEY for efficient data distribution.
- Use Materialized Views for faster access to frequent queries.
- Apply Workload Management (WLM) to prioritize critical queries.
3. High-Concurrency Workloads
Redshift can handle massive concurrent queries with minimal latency, making it more suitable than Athena for large teams under heavy query loads.
- Organizations with multiple analysts running reports simultaneously
- Businesses requiring near real-time data processing for operational insights
- Industries like finance and healthcare that rely on complex, continuous analytics
Example: Scaling with RA3 Nodes for High-Volume Workloads
sql
ALTER CLUSTER my_redshift_cluster RESIZE TO NODE TYPE ra3.16xlarge;
Besides improving speed, this command helps reduce expenses by enabling computation and storage to scale independently.
Here’s a quick comparison between Athena and Redshift in use cases:
6. Security and Compliance
Security is essential for sensitive data. Both Amazon Athena and Redshift offer robust AWS security features but differ in implementation, impacting compliance and data protection strategies.
Amazon Athena: Serverless Security
- IAM-Based Access Control – Athena integrates with AWS Identity and Access Management (IAM), enabling precise, query-level permissions.
- End-to-End Encryption – Encrypts data at rest with AWS Key Management Service (KMS) and secured in transit via SSL.
- Enhanced Governance with AWS Lake Formation – Additional access control policies ensure strict data security when working within a data lake environment.
Amazon Redshift: Enterprise-Grade Protection
- Private Network Isolation – Deployed within an Amazon Virtual Private Cloud (VPC) and compatible with AWS PrivateLink for secure data transfer.
- Granular Access Controls – Restrict data visibility with column- and row-level security.
- Comprehensive Audit Logging – Monitor user activity and query history for compliance.
- Advanced Encryption – Encrypts data in transit and at rest, including automatic backup encryption.
AWS provides security solutions tailored to your needs, whether it’s Athena’s flexible, serverless model or Redshift’s enterprise-grade compliance controls.
7. Compatibility with Other AWS Services
Most businesses manage their data pipelines using various AWS services. Thus, it’s best to choose a service that integrates well with existing AWS tools.
| AWS Service | Amazon Athena | Amazon Redshift |
|---|---|---|
| S3 | Direct queries | Uses Redshift Spectrum |
| AWS Glue | Schema discovery | ETL and cataloging |
| QuickSight | Direct visualization | Native BI integration |
Final Thoughts
The type of data workload you have will determine which of Amazon Redshift and Amazon Athena is best for you. Athena is the optimal choice if your primary need is cost-efficient, ad-hoc analysis on S3-stored data. However, if you require high-performance, complex queries on structured datasets, Redshift is the better option.
- Choose Athena if you need a serverless, pay-per-query model for analyzing data stored in Amazon S3 with minimal setup.
- Choose Redshift if you need a high-performance data warehouse for complex, large-scale queries with predictable workloads.
If your data includes both structured and semi-structured formats, Redshift Spectrum provides added flexibility. The right choice depends on your budget, data growth, and analytical priorities. For teams managing large-scale analytics workloads, AI Teammates can help monitor query performance, detect pipeline anomalies, and reduce operational overhead.
FAQs on Athena and Redshift
Can Amazon Athena and Amazon Redshift be used together?
Yes, integrating Athena and Redshift allows combining Redshift’s structured data warehousing with Athena’s capability to query semi-structured data in S3, enabling flexible analytics across diverse datasets.
How do Amazon Athena and Amazon Redshift handle data partitioning?
Athena improves query performance with flexible partitioning by any key, while Redshift relies on distribution and sort keys for optimized parallel processing.
What are the limitations of Amazon Athena compared to Amazon Redshift?
Athena may have slower performance with complex queries and large datasets, has concurrency limits affecting simultaneous queries, and doesn’t manage data storage, querying directly from S3.

