


Flaky tests produce non-deterministic results. Running the same test multiple times yields different outcomes. There are no actual regressions, broken assertions, or CI failures. The system under test remains stable, but the test itself cannot be trusted.
Flakiness manifests as intermittent passes and failures. While reruns may appear to solve the issue, they merely mask the underlying instability, driving up pipeline costs and eroding confidence in the software delivery process. As systems grow more complex and rely on parallel execution, non-deterministic behavior becomes more common, further weakening trust in automation.
This article defines flaky tests, examines their root causes in modern software development, and explores their impact on testing reliability and overall software quality.
Key Takeaways
• Flaky tests indicate unstable test execution, not faulty code, making test results unreliable indicators for decision-making.
• Parallelism, ephemeral runners, and shared infrastructure are some major contributors to non-determinism in CI systems.
• Retries mask instability by increasing the cost of the pipeline and enabling unstable tests to run undetected.
• Historical execution patterns expose flakiness more reliably than single failures or log inspection.
• Environment standardization and test isolation restore determinism and improve trust in automated signals.
• Unreliable CI signals affect the speed of delivery, causing reruns, manual verifications, and developers having doubts about automation.
What Is a Flaky Test in a CI/CD Pipeline?

A flaky test is defined by its lack of repeatability, not by incorrect assertions. Tests act as automated signals that inform release decisions within CI/CD pipelines.
When those signals produce different results under identical conditions, the pipeline can no longer distinguish real failures from noise. Flakiness points to a reliability problem within the testing system itself, where unpredictable execution steadily erodes trust in automation.
What does determinism mean in automated testing, and why does CI challenge it?
Determinism ensures that an automated test produces the same result when nothing in the system has changed. This repeatability is what makes test outcomes reliable pass/fail signals in CI/CD pipelines.
CI environments, however, introduce variability by design. Tests run on ephemeral workers, execute in parallel, and share infrastructure with other concurrent workloads. Scheduling differences, resource contention, timing variability, and network behavior all fall outside the test’s control — undermining determinism and increasing the risk of flakiness.
Why CI challenges determinism
| CI characteristic | Effect on test behavior |
|---|---|
| Ephemeral runners | State resets and environment drift |
| Parallel execution | Hidden ordering and timing assumptions |
| Shared infrastructure | Resource contention and variable latency |
| Distributed dependencies | Amplified sources of non-determinism |
A flaky test produces inconsistent results without any code change
The system under test may remain stable, yet variability during execution can produce different results across runs. Flaky tests account for an estimated 13% of CI build failures and up to 16% of test failures in large-scale software systems, introducing significant noise into the delivery pipeline.
How are flaky tests different from legitimate test failures?
Legitimate test failures occur when a code change introduces a defect or causes unexpected behavior. These failures are repeatable, have clear root causes, and are directly actionable. If a bug is present, rerunning the test will consistently reproduce the failure.
Flaky tests, by contrast, are non-deterministic — their success or failure depends on external factors such as timing, concurrency, or network variability. When teams fail to treat flakiness as a genuine reliability issue, it creates noise in the pipeline and steadily erodes confidence in CI as a trustworthy signal.
Comparing legitimate vs. flaky test failures
| Feature | Legitimate Failure | Flaky Test Failure |
|---|---|---|
| Cause | Code defect or regression | Execution variability |
| Repeatability | Consistent across runs | Inconsistent across runs |
| Actionability | Directly actionable | Hard to act on |
| Impact on trust | Builds confidence if fixed | Reduces confidence in automation |
Engineering research defines flakiness as non-determinism rather than incorrect assertions
Tests often become flaky due to environmental and system-level factors such as race conditions, hidden dependencies, and shared state. This highlights that flakiness is fundamentally a pipeline reliability issue — not simply a matter of poor test implementation.
According to Atlassian, flaky tests were responsible for 21% of master build failures in the Jira frontend, resulting in an estimated 150,000 lost developer hours annually.
Where Does Test Flakiness Come From in CI/CD Systems?
Flakiness comes from differences between systems, not between tests. Tests that are identical can act differently because of differences in execution settings, parallelism, and external dependencies.
Understanding these layers frames flakiness as a reliability issue in the system, not a test problem.
How do CI execution environments introduce variability into tests?
Ephemeral runners, shared resources, and dynamic workloads contribute to an unpredictable environment. Tests may yield different results even with the same code and input due to resource contention as well as other environment differences.
Factors that influence CI execution environments:
- Ephemeral runners reset the state between jobs
- Shared infrastructure induces resource contention
- Dynamic allocation affects CPU, memory, and I/O availability
CI runners are ephemeral and frequently shared across workloads
CI runners are temporary and reused across jobs, which resets their state and alters performance between executions.
The shared usage presents conditions of contention for resources and hardware reassignment. These conditions make tests behave unpredictably, although the tested system may remain the same.
Why do time, concurrency, and execution order cause flaky behavior?
Tests executed by automation often rely on a predictable sequence of events. However, CI pipelines do not adhere to this because they execute code in parallel.
With the disappearance of these guarantees, new dependencies can reveal themselves, such as:
- The concurrent access of the state
- Background tasks completing within the expected window
- Setup logic running first
They may destabilize the previously stable test, reducing their faithfulness as a signal. In CI environments, several structural factors introduce variability into test execution:
| Source of variability | Effect on test behavior |
|---|---|
| Parallel execution | Race conditions and shared state conflicts |
| Dynamic scheduling | Non-deterministic setup and teardown order |
| Timing assumptions | Operations complete earlier or later than expected |
Tests dependent on timing or execution order are common sources of flakiness
A significant portion of CI test failures stems not from incorrect assertions, but from non-deterministic scheduling and concurrency effects.
Research indicates that flaky tests account for roughly 13% of build failures, with many occurring despite no underlying code changes. These failures reflect unstable signals in distributed execution environments, not genuine correctness defects.
How do external services and networks amplify non-determinism?
Tests that depend on live services, APIs, or databases introduce additional sources of variability. A test may pass or fail without any code changes, influenced by factors such as network latency, service throttling, or partial outages.
Unlike local execution, these external dependencies fall outside the CI environment’s control, reducing determinism and increasing the likelihood of unpredictable outcomes.
Network-dependent systems exhibit variable latency and failure behavior
Tests that rely on external dependencies can fail unpredictably because those environments lie outside the control of CI. Network delays, service throttling, or transient outages may cause a test to pass on one run and fail on another.
Such failures reflect non-deterministic signal generation in distributed execution environments—not actual correctness defects in the system under test.
Why Do Flaky Tests Persist Even in Mature CI/CD Pipelines?
Tests that depend on external services can fail unpredictably because those systems operate beyond the control of the CI environment. Network latency, service throttling, or transient outages may cause a test to pass in one run and fail in the next.
These failures represent non-deterministic signal generation in distributed execution environments—not true defects in the system under test.
Why do retries make flaky tests harder to detect and fix?
CI pipelines often retry failed tests to reduce noise and prevent delivery bottlenecks. While this may give the appearance of stability, it masks intermittent failures and accumulates hidden reliability debt.
Retries conceal non-determinism, making it harder to distinguish real regressions from flaky signals. Over time, this undermines visibility into system reliability and delays the detection of instabilities in distributed environments.
Key effects of retry-based mitigation:
- Masked failures: Flaky tests pass after retries, reducing visibility.
- Hidden non-determinism: Root causes remain unaddressed and persist across pipelines.
- Inflated confidence: Teams over-trust automation, delaying system-level fixes.
Retry-based mitigation masks systemic reliability issues
Retries can mask as many as 1 in 7 failing tests in large CI systems, making reliability debt invisible.
For instance, a network-dependent test that intermittently times out may pass after multiple attempts, hiding the root cause. These hidden failures make it harder for teams to tackle instability, resulting in CI signals that are unreliable and misleading.
How does gradual flakiness erode trust in test automation?
Intermittent failures without clear causes gradually erode engineers’ trust in CI signals. Over time, teams adapt to unreliable behavior, treating flakiness as normal rather than a problem to fix.
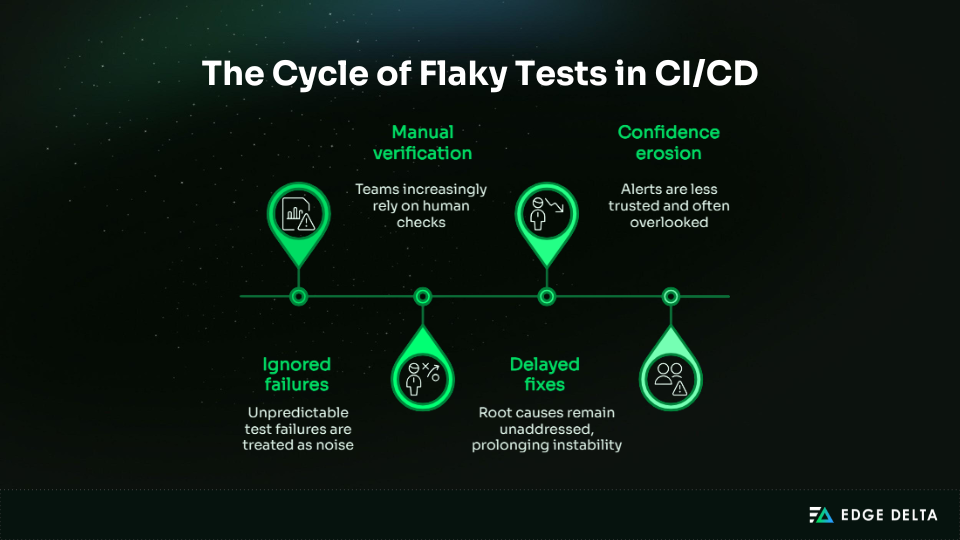
| Effect on automation | Description |
|---|---|
| Ignored failures | Unpredictable test failures are treated as noise |
| Manual verification | Teams increasingly rely on human checks |
| Delayed fixes | Root causes remain unaddressed, prolonging instability |
| Confidence erosion | Alerts are less trusted and often overlooked |
Automation trust declines when failures lack consistent causality
Flaky tests undermine trust in automation because failures aren’t consistent or reflective of real issues.
When the cause of a failure is unclear, teams struggle to distinguish true problems from noise. This not only weakens confidence in CI/CD pipelines but also hides systemic reliability issues, reducing the effectiveness of automated delivery processes.
How Should Flaky Tests Be Detected in CI/CD Pipelines in 2026?
Detecting flaky tests relies on both pattern recognition and signal analysis, since non-deterministic behaviors are often invisible in log files.
The process involves identifying recurring patterns, classifying failures, and correlating environment telemetry to separate true regressions from noise. By doing so, it reinforces trust in automation and ensures CI signals remain reliable and actionable.
How can historical execution patterns reveal flaky tests?
Flaky failures can appear as genuine bugs, even when historical execution data reveals non-deterministic behavior. Pass–fail cycles across multiple runs help identify tests whose failures stem from timing issues, parallelism, or environmental variability.
| Signal | What it indicates |
|---|---|
| Repeated pass–fail cycles | Non-deterministic behavior |
| Alternating outcomes without code changes | Environmental or scheduling variability |
| High volatility tests | Tests needing further investigation |
Repeated pass–fail patterns without code changes indicate non-determinism
Tests that alternate between passing and failing on the same code with identical inputs reveal hidden instability. Industry studies show that roughly 13% of test failures are caused by flakiness rather than actual regressions.
By tracking these patterns, teams can focus on genuine issues and reduce misdiagnoses.
How do teams distinguish flaky behavior from real regressions?
Proper classification can help prevent alert fatigue and the overuse of automatic tools. If you don’t make this distinction, you can miss real problems or waste time on noise.
- Classify failures by type: flaky vs deterministic
- Reduce alert fatigue and focus on actionable failures
- Prevent false confidence in automation
Lack of failure classification increases diagnostic noise
These unclassified failures cause noise in the CI dashboard. Without classification, the contribution of flaky tests is unnecessary noise that comprises around 5.7% of failed builds.
Classification of failures systematically directs the effort towards the relevant failure, maintaining trust in the automated tools.
Why are logs alone insufficient to identify flaky tests?
Logs can record the state of a single run, but the context needed to detect the presence of non-determinism is still lacking. Both the CI runners and the network can cause intermittent effects that cannot be discovered using just the logs.
Correlated telemetry improves root cause identification in distributed systems
Combining logs, metrics, and traces can reduce root-cause identification time by 30%–50% compared with logs alone.
In CI pipelines, correlated telemetry data points to patterns in the environment, the network, and the timing. This is helpful in distinguishing flaky tests from true regressions.
What Does “Fixing” Flaky Tests Mean in 2026?
When tests are flaky, refactoring them requires putting more effort into stabilizing the system than altering or reworking the tests. It involves looking at signals, figuring out what they depend on, and making sure that tests always run in CI.
Fixing flakiness at the system level helps maintain trust that an automated service is reliable and that test failures really indicate problems with the code.
How does shared state between tests create flakiness?
Tests that share state can unexpectedly interfere with one another, even when connections are hidden through global variables, caching, or database interactions. Ensuring proper isolation guarantees repeatable results, independent of execution order or parallelism.
- Shared variables between tests
- Cached resources or temporary files
- Common database entries
Shared mutable state is a leading cause of flaky test behavior
In large CI pipelines, up to 15% of flaky test failures stem from shared state between tests. Eliminating hidden dependencies and enforcing proper test isolation improves determinism and reliability.
Why does stabilizing execution environments reduce flakiness?
Variability in CI runners, container images, or operating systems can cause tests to behave inconsistently, passing or failing unpredictably. Standardizing the execution environment with reproducible containers reduces this indeterminism and ensures that tests only fail when the code changes.
Consistent environments reduce non-deterministic outcomes
Organizations have seen up to a 40% reduction in flaky tests, creating a more predictable testing environment. Standardized environments ensure consistent test behavior across runners, jobs, and parallel executions.
This consistency strengthens trust in automated feedback, reduces the cost of debugging, and ensures that test failures are always due to code issues, not environmental factors.
Why must test infrastructure be treated as production-critical?
Test infrastructure, such as CI runners, orchestration services, and monitoring systems, forms a critical reliability surface.
Failures can cause incorrect test results, conceal underlying issues, and lead to people doubting workflows. Proper infrastructure ensures production readiness to keep pipelines consistent, scalable, and reliable across all teams and projects.
| Infrastructure component | Impact on flakiness |
|---|---|
| CI runners | Downtime or variable performance causes false failures |
| Orchestration services | Mismanaged job execution orders create inconsistencies |
| Monitoring systems | Missing signals delay detection of systemic issues |
SRE guidance recommends production-level reliability for test infrastructure
SRE best practices demonstrate that test infrastructure should meet production standards. When teams set up high availability, monitoring, and reproducible environments, they get 20% fewer false test failures.
This makes automatic signals more consistent and reliable, which lets engineers focus on real problems instead of false positives.
Why Do Flaky Tests Matter for CI/CD Delivery Reliability?
Flaky tests impact delivery outcomes by injecting variability into automated signals. They affect lead time extension and reduction of pipeline throughput, but they also impact how engineers interact with CI systems.
How do flaky tests affect pipeline throughput and lead time?
When tests fail from time to time, pipelines often execute jobs again to make sure the results are correct. Even when the code is right, these reruns make lead time longer and feedback loops slower. Over time, the pipelines will add up the extra time it takes for multiple pipelines.
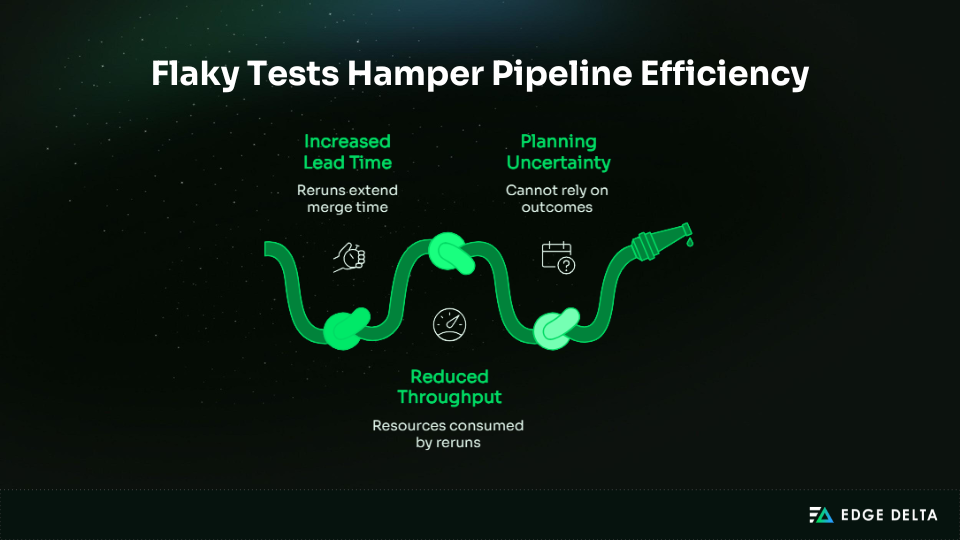
| Impact of flaky tests on pipelines | Description |
|---|---|
| Increased lead time | Reruns extend time to merge and deploy |
| Reduced throughput | Resources consumed by repeated executions |
| Planning uncertainty | Teams cannot rely on pass/fail outcomes |
Alt tag: Flaky test impact on pipeline speed and reliability
CI instability increases lead time and reduces delivery confidence
Also, flaky tests can cause up to 16% of CI failures, resulting in a re-run of the test and a manual test, thus slowing down the merge process. This impacts the trust level because it is difficult to determine the real problem, especially the delivery process.
How do flaky tests change developer behavior and automation trust?
When test results fluctuate unpredictably, engineers adapt to the noise rather than addressing the root causes. This erodes trust in CI pipelines, leading developers to re-run pipelines, ignore intermittent failures, or add extra checks.
As a result, CI shifts from being a decision-making tool to a filtering mechanism, reducing its effectiveness in delivery workflows. Common consequences of this shift include:
- Retrying pipelines without investigation
- Ignoring single failures during code reviews
- Performing manual validation before merges
Low-confidence automation increases manual intervention
Flaky tests force engineers to validate results outside the CI pipeline.
Intermittent failures require re-running tests and manually verifying outcomes, which is time-consuming and reduces developer efficiency.
Why Are Flaky Tests a Systems Reliability Problem Rather Than a Testing Problem?
Flaky tests arise when execution conditions cannot be reliably reproduced. Variability in scheduling, environments, and dependencies creates hidden couplings that make outcomes unstable, even when the code hasn’t changed. In these cases, failing tests reflect flaws in the execution system, not the test logic itself.
Retries can mask this instability, giving a false sense of success. Pipelines may continue to pass, but signal quality suffers due to unresolved non-deterministic behavior. This apparent resilience often masks accumulated uncertainty.
From a reliability perspective, flakiness indicates weakened system guarantees. Addressing it requires focusing on stabilizing execution conditions and maintaining system determinism, not just the test cases themselves.
FAQs About Flaky Tests in CI/CD Pipelines
What makes a test flaky in CI/CD pipelines?
If a test fails all the time without any changes to the code, it is considered to be flaky. There could be a number of reasons why behavior is non-deterministic, such as variables that are connected to time, tests running at the same time, or resources that tests might share.
-
Why do flaky tests pass when rerun?
Retries temporarily disguise non-deterministic behavior by performing the test in a slightly different setting. This might get rid of timing, resource, or occasional program failures from outside sources, making it seem like the system is more stable when the underlying non-deterministic behavior is still there.
-
Are flaky tests caused by test code or infrastructure?
Flakiness primarily stems from system-level factors like ephemeral runners, parallel execution, shared state, and network variability. While test code assumptions can contribute, infrastructure and environment inconsistencies are usually the main drivers of intermittent failures.
-
How should teams detect flaky tests reliably?
Teams ought to study past execution trends, divide failures between flaky and deterministic ones, and correlate logs, metrics, and telemetry. Observations from a single run are not enough, as multiple pass/fail cycles are required to detect non-deterministic tests on the system level.
-
Why do flaky tests reduce trust in CI/CD automation?
Intermittent failures erode confidence in automated signals. Developers rerun pipelines, perform manual checks, or ignore alerts, reducing reliance on CI/CD, masking systemic issues, and undermining the effectiveness of automated testing in delivery pipelines.
Source List:

