


Every day, organizations are inundated with data — from cloud applications and databases to IoT devices and more. According to recent estimates, over 402 million terabytes of data are generated globally each day, and that number continues to grow rapidly.
To extract value from this data, it must be reliably transferred from its source to a system where it can be stored, analyzed, and acted upon. This critical process is known as data ingestion.
Data ingestion involves collecting data from diverse sources and moving it into a centralized system such as a data warehouse or data lake. It’s the foundational step in any modern data pipeline — enabling everything from real-time dashboards to machine learning models and operational decision-making.
In this guide, we’ll explore what data ingestion is, how it works, the different methods and architectures available, the most widely used tools, and the common challenges teams face in building and maintaining reliable ingestion workflows.
Key Takeaways
• Data ingestion moves information from diverse sources into storage systems, such as data lakes or warehouses, where it can be analyzed and acted upon.
• The type of ingestion — batch, streaming, or micro-batching — determines how quickly data is processed and should align with the use case.
• Tool selection depends on your technical stack and team expertise; open-source tools offer flexibility, cloud-native options reduce operational overhead, and enterprise platforms support compliance requirements.
• Common challenges include scaling to handle large data volumes, managing evolving schemas, preventing duplicates, and working within infrastructure constraints.
• Effective ingestion pipelines are modular, monitored, resilient to failure, and designed with security in mind.
How Data Ingestion Works
Data ingestion is the process of collecting data from various sources and moving it into a system where it can be stored, processed, and analyzed. This can include data from internal databases, SaaS platforms, cloud storage, or connected devices.
While implementation details vary, the goal is always the same: deliver the right data to the right place, and ensure it’s clean, accurate, and on time. Here’s how the ingestion process typically works:
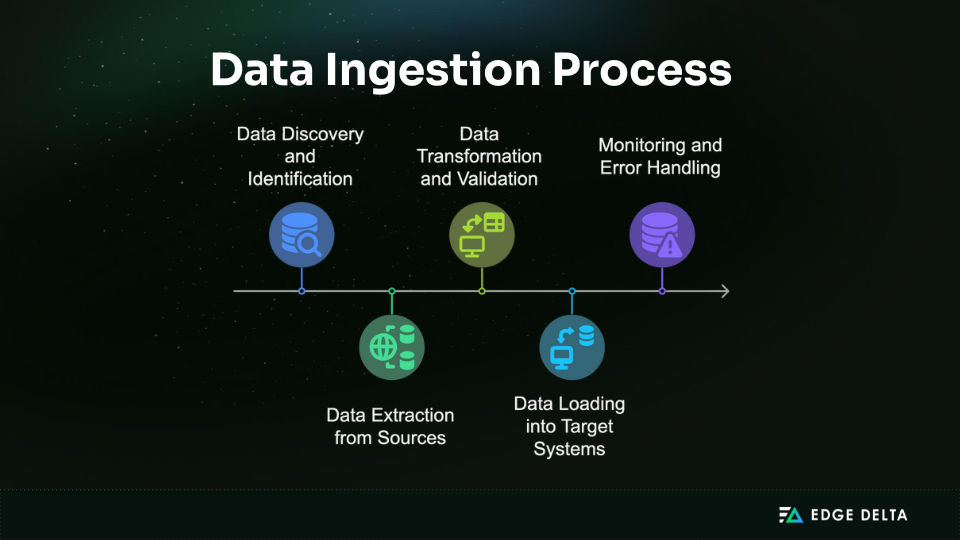
1. Data Discovery and Identification
The ingestion process begins by identifying available data sources and understanding their structure, location, and accessibility. These sources may include structured databases, cloud storage buckets, APIs from SaaS applications, log files, or real-time streams from IoT devices. Tools such as metadata catalogs, data registries, and source-specific APIs are used to discover, inventory, and classify dataset — often capturing information like schema, format, data lineage, and update frequency.
2. Data Extraction
Once sources are identified, data is pulled using appropriate extraction methods based on the source type:
- APIs for web services and cloud platforms
- FTP/SFTP for flat files and legacy systems
- SQL queries for structured data in relational databases
- Event streams (e.g., Kafka, MQTT) for real-time or near-real-time data
Efficient extraction depends on connection stability, throughput, and source-specific constraints like rate limits or access controls.
3. Transformation and Validation
Extracted data is often raw and inconsistent. Transformation steps may include field renaming, data type conversion, format normalization, enrichment from reference data, or aggregation. Validation ensures that the data is accurate, complete, and conforms to expected schemas — helping prevent downstream errors.
4. Loading into Target Systems
Validated data is loaded into destination platforms such as data warehouses, lakes, or analytics tools. The loading method depends on latency and scalability requirements:
- Batch loading: Efficient for large volumes but not real-time
- Streaming: Enables real-time insights but adds architectural complexity
- Micro-batching: Balances latency and throughput by sending small batches at regular intervals
5. Monitoring and Error Handling
Robust monitoring tracks data pipeline performance, throughput, latency, and failure rates. Some platforms, such as Edge Delta, provide live data capture and interactive pipeline previews, allowing teams to validate transformations and troubleshoot issues before deployment. Automated error handling, alerting, and retry mechanisms help maintain pipeline reliability and minimize data loss.
Quick Breakdown: Ingestion Architecture Components
A typical data ingestion pipeline consists of several core layers, each responsible for moving, transforming, and managing data from source to destination:
• Source Systems: The origin of the data — such as databases, SaaS applications, APIs, log files, or IoT devices.
• Ingestion Layer: This layer moves data from sources to downstream systems, either in real time or in batches. Tools like Apache Kafka, Fivetran, AWS Kinesis, and Edge Delta’s Telemetry Pipelines operate here — efficiently collecting, streaming, or forwarding telemetry data from a wide range of sources.
• Processing Layer: Responsible for transforming, enriching, and filtering data before or after storage. This can include tools like Apache Spark, Flink, or SQL engines. Edge Delta’s Telemetry Pipelines also play a role here by enabling in-stream transformations, filtering, and log-to-metric conversions — helping reduce downstream volume and improve data quality.
• Storage Layer: Where ingested data is stored. This can include data lakes (e.g., Amazon S3, Azure Data Lake) for raw or semi-structured data, as well as data warehouses (e.g., Snowflake, BigQuery) for structured, query-ready datasets.
• Monitoring Layer: Provides visibility into pipeline performance and system reliability. It includes dashboards, alerting tools, and logging systems that track key metrics and surface anomalies. Legacy observability tools like Splunk and Datadog are commonly used, while modern platforms like the Edge Delta Observability Platform offer real-time pipeline insights, transformation previews, and integrated alerting to support proactive issue detection and resolution.
Each layer is essential for building a scalable, fault-tolerant architecture that can accommodate diverse data types, evolving schemas, and real-time operational needs.
Data Flow Patterns
Data travels through systems in various ways, depending on use cases and infrastructure. The most common data flow patterns include:
- Pull-Based Ingestion: Systems pull data on a schedule, much like going to a store. This approach is common in traditional reporting and batch processing workflows.
- Push-Based Ingestion: Comparable to home delivery, data is sent immediately upon creation via webhooks, event streams, or messaging systems. This pattern suits real-time and near-real-time use cases.
- Hybrid Approaches: Some architectures combine both methods — for example, streaming user events in real time while pulling transactional data on a scheduled basis — leveraging the advantages of each.
- Change Data Capture (CDC): A technique that detects and transfers only new or modified records from databases, enabling efficient synchronization of systems with minimal latency.
Data Formats and Protocols
The format and communication protocols of data influence how it is ingested, processed, and stored:
-
Structured Data:
- CSV: Lightweight and widely supported, but lacks inherent schema enforcement.
- JSON: Flexible, human-readable, and well-suited for APIs.
- XML: Verbose yet common in legacy enterprise applications.
- Parquet/Avro: Columnar, compressed, and schema-aware formats optimized for large-scale data processing.
-
Semi-Structured Data: Formats like JSON, XML, and YAML provide flexibility with hierarchical organization but do not enforce rigid schemas.
-
Unstructured Data: Encompasses images, videos, documents, and logs. Typically requires preprocessing for AI/ML workflows and analytics.
-
Communication Protocols:
- HTTP/REST: Widely used for APIs due to simplicity and compatibility.
- FTP/SFTP: Secure file transfer protocols commonly used for batch data movement.
- Message Queues (Kafka, RabbitMQ): Facilitate reliable, asynchronous, and scalable data exchange in distributed systems.
Types of Data Ingestion
Selecting the right data ingestion method is essential for aligning with business goals, resource capacity, and analytical needs. Below are the three major types of data ingestion, each with unique trade-offs in terms of latency, cost, and complexity.
Batch Data Ingestion
Batch ingestion involves collecting and processing data in discrete, scheduled intervals or chunks. Batch sizes can vary from megabytes to terabytes and are typically executed on an hourly, nightly, or weekly basis, depending on the specific requirements.
Use Cases:
- Historical data analysis
- Financial reconciliation
- Data warehouse loading
- Compliance reporting
Industry Examples:
- Banking: End-of-day transaction processing for reconciliation and fraud monitoring
- Retail: Daily inventory and sales updates sent to central analytics systems
Advantages:
- Cost-effective: Optimizes resource usage by concentrating processing into defined windows
- Predictable performance: Easier to schedule jobs around system capacity
- Simpler error handling: Failures can be retried without affecting real-time systems
Disadvantages:
- Higher latency: Data can be delayed by hours to even days, depending on schedule
- Delayed insights: Not suitable for time-sensitive applications
- Failure impact: Large failures can result in significant data gaps
Common Tools:
| Tool | Strengths | Weaknesses |
|---|---|---|
| Apache Airflow | Workflow automation, Python-native | Not real-time; best for orchestration |
| AWS Batch | Scalable, serverless compute for batch jobs | AWS-specific |
| Azure Data Factory | Integration with Microsoft ecosystem | Learning curve for complex pipelines |
| Google Dataflow | Unified batch/stream support | Requires knowledge of Apache Beam |
Real-Time / Streaming Data Ingestion
Streaming ingestion processes data continuously as it is generated, typically with latencies ranging from a few milliseconds to several seconds. While often called “real-time,” most systems deliver near-real-time performance rather than instantaneous microsecond-level processing.
Use Cases:
- Fraud detection (e.g., flagging transactions within milliseconds)
- IoT telemetry and alerting
- Live dashboards and metrics
- Recommendation engines and personalized experiences
Advantages:
- Low latency: Enables insights within sub-second to second intervals
- Real-time decision-making: Critical for time-sensitive applications such as trading, security, and incident response
- Competitive advantage: Enhances customer experience through immediate feedback and interaction
Disadvantages:
- Operational complexity: Demands resilient infrastructure, continuous monitoring, and sophisticated orchestration
- Higher costs: Continuous processing increases resource consumption and compute expenses
- Scaling challenges: Managing bursts of streaming data requires careful capacity planning and tuning
Common Tools:
| Tool | Best For | Considerations |
|---|---|---|
| Apache Kafka | High-throughput pipelines, fault tolerance | Requires careful cluster management |
| Amazon Kinesis | Native AWS integration, real-time pipelines | Costs can grow rapidly with volume |
| Apache Storm | Complex event processing, low latency | Steeper learning curve |
| Azure Event Hubs | Real-time ingestion for Microsoft ecosystems | Limited built-in processing capabilities |
In addition to these industry-standard tools, Edge Delta’s Telemetry Pipelines offer a powerful platform for streaming data ingestion that combines real-time collection, in-stream transformation, and filtering. This enables teams to reduce downstream data volumes and accelerate actionable insights — all while maintaining pipeline reliability and scalability.
Micro-Batch Ingestion
Micro-batching involves processing small batches of data at short, regular intervals — typically ranging from a few minutes to an hour. This approach strikes a balance between traditional batch processing and real-time streaming and is ideal for scenarios where streaming ingestion is unnecessary but waiting hours for batch updates would be too slow.
Use Cases:
- Social media analytics
- Operational log processing
- IoT device data aggregation
- User behavior tracking
Advantages:
- Lower latency than batch: Provides near-real-time insights without the complexity of continuous streaming
- Simpler than full streaming: Requires fewer components and is easier to manage compared to full streaming systems
- Fault tolerance: Supports straightforward retry mechanisms and monitoring
Disadvantages:
- Inherent latency: Does not offer the immediacy of true streaming ingestion
- Batch sizing complexity: Improper batch sizes can cause delays or inefficient resource use
- Risk of backlog: High-velocity data sources may lead to micro-batch queues accumulating if processing lags
Common Tools:
| Tool | Strengths | Limitations |
|---|---|---|
| Apache Spark Streaming | Scalable, integrates well with Spark ecosystem | Micro-batch model, not true stream |
| Azure Stream Analytics | Serverless, easy integration | Mostly used within Azure platform |
| AWS Kinesis Analytics | Built-in SQL processing on streams | Limited support for complex event correlation |
Data Ingestion Tools and Technologies
Selecting the right data ingestion tool depends on multiple factors — scale, latency requirements, team expertise, infrastructure, and budget. Below is an overview of popular tools grouped into open-source platforms, cloud-native services, enterprise-grade solutions, and modern observability-focused pipelines.
Open Source Tools
Open-source tools provide flexibility, extensibility, and strong community support. While license-free, they often require significant investment in setup, maintenance, and skilled resources.
- Apache Kafka is a distributed streaming platform designed for high-throughput, real-time event pipelines. It excels at scalable stream processing but demands operational expertise to deploy and manage.
- Apache Airflow is a Python-based workflow orchestrator optimized for batch jobs and complex dependencies. It offers flexibility but is not suited for real-time ingestion.
- Apache NiFi provides a visual interface for data routing and transformation with strong governance capabilities. It is user-friendly but can be resource-intensive at scale.
Cloud-Native Solutions
Cloud-native platforms provide managed infrastructure, seamless integration within their ecosystems, and elastic scalability.
- AWS offers Kinesis for streaming, Glue for ETL, and MSK as a managed Kafka service. These tools scale effectively and integrate tightly with other AWS services, though costs can increase at scale.
- Azure provides Data Factory for pipeline orchestration and Event Hubs for streaming ingestion. It is well-suited for Microsoft-centric environments but may be less flexible outside the Azure ecosystem.
- Google Cloud includes Pub/Sub for messaging, Dataflow for unified stream and batch processing, and Data Fusion for low-code pipeline development. These tools work best when paired with BigQuery and other GCP services.
Enterprise Commercial Tools
Designed for compliance-heavy industries and complex legacy integrations, these tools come with robust support and governance features.
- Informatica PowerCenter is a metadata-driven ETL platform with strong compliance and governance capabilities, though it can be costly and complex to deploy.
- Talend blends open-source flexibility with enterprise-grade support, offering a wide range of connectors and deployment options, often requiring Java expertise.
- IBM DataStage focuses on high-throughput ingestion and legacy system integration, delivering powerful performance at the cost of a steep learning curve.
Here’s a quick breakdown of the tools by key criteria:
| Criteria | Open Source | Cloud-Native | Enterprise Tools |
|---|---|---|---|
| Budget Constraints | ✅ Free | ⚠️ Usage-based | ❌ High license cost |
| Technical Resources | ✅ Requires in-house | ✅ Low ops overhead | ✅ Vendor support |
| Real-Time Needs | Kafka, Spark | Kinesis, Pub/Sub | Event Hubs |
| Compliance/Governance | Airflow, NiFi (manual) | Varies | PowerCenter, DataStage |
Modern Telemetry Pipelines
In addition to traditional tools, solutions like Edge Delta’s intelligent Telemetry Pipelines offer a flexible approach to data ingestion that’s specifically tailored for observability and security use cases. By enabling efficient routing between any source and any destination, as well as in-pipeline processing and AI-powered insights, Edge Delta reduces downstream data volumes while maintaining scalability, visibility, and operational simplicity.
Data Ingestion Challenges
Data ingestion is the backbone of modern analytics, machine learning, and real-time decision-making. However, it presents a variety of technical, operational, and business challenges that can impact system reliability, scalability, and overall return on investment.
The good news is that these challenges are engineering problems that can be addressed. Below, we highlight key obstacles and practical strategies to overcome them.
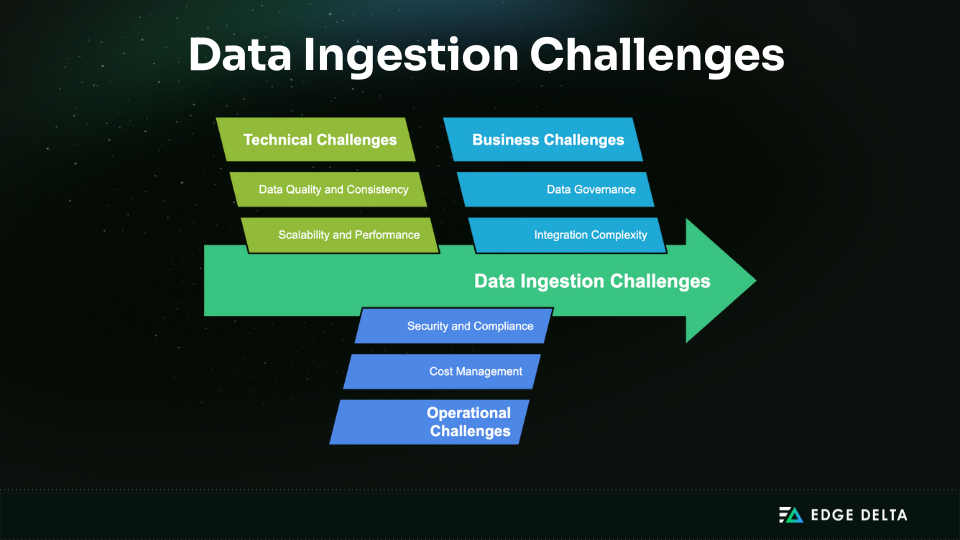
Technical Challenges
Modern ingestion systems must be designed to handle scale, inconsistency, and unpredictability. Successfully addressing these factors ensures data pipelines remain fast and reliable.
1. Scalability and Performance
The three Vs of big data — volume, velocity, and variety — each present distinct performance challenges:
- Volume: Organizations like Netflix ingest over 15 petabytes of data daily. Managing data at this scale requires horizontally scalable architectures, including distributed data lakes, elastic compute clusters, and stateless ingestion layers built for sustained high throughput.
- Velocity: High-speed environments such as stock trading platforms or IoT networks process millions of events per second. Achieving this demands real-time stream processing engines combined with efficient event buffering.
- Variety: Ingested data spans structured databases, semi-structured APIs, and unstructured logs. Supporting this diversity requires schema-flexible pipelines and modular, pluggable source connectors.
How to address it: Leverage cloud-native, distributed systems that enable horizontal scaling, and incorporate intelligent caching or load shedding mechanisms to sustain throughput during peak loads.
2. Data Quality and Consistency
Poor data quality can undermine downstream analytics and drive up costs significantly. According to Gartner, organizations lose an average of $12.9 million annually due to data quality issues.
- Schema evolution: Changes in APIs or database schemas can silently break data pipelines. Dynamic schema detection and backward-compatible design patterns help preserve ingestion resilience.
- Validation: Ensuring data completeness, proper formatting, and adherence to business rules prevents bad data from propagating through your systems.
- Duplicates and missing data: Retries and system glitches can lead to redundant or incomplete records. Addressing this requires strategies like hash-based deduplication, data imputation, and flagging anomalies for manual review.
How to address it: Implement validation layers using tools like Great Expectations or dbt, introduce schema versioning, and configure ingestion systems with built-in quality checks. Edge Delta’s Telemetry Pipelines also support in-pipeline standardization and normalization — ensuring data is clean, consistent, and ready for downstream use before it ever reaches your storage or analytics layers.
3. Error Handling and Recovery
Failures are inevitable. What matters is how your system responds.
- Fault tolerance: Transient network issues or service crashes shouldn’t bring down your pipeline. Implement retry logic, message buffering, and auto-failover mechanisms to maintain continuity.
- Replayability: When failures occur, systems should reprocess data from a safe checkpoint without risking duplication or loss.
- Monitoring: Real-time alerts surface issues early, while detailed logs enable effective root cause analysis.
- Recovery: Regular backups and version-controlled pipelines make it easier to restore operations to a known-good state.
How to address it: Adopt ingestion platforms that support idempotent processing, checkpointing, and resilient data handling. Leverage observability tools like Prometheus, Grafana, and OpenTelemetry for proactive monitoring, alerting, and recovery.
Operational Challenges
Operational inefficiencies can drive up costs, increase security risk, and strain team resources. Each challenge has a direct and measurable business impact.
1. Cost Management
Without proper controls, data ingestion and observability costs can grow uncontrollably.
- Infrastructure costs: Real-time data pipelines can incur substantial compute, storage, and networking expenses — especially at scale and across distributed systems.
- Licensing: Proprietary ingestion and observability tools often require expensive, volume-based licensing models.
- Maintenance: DevOps and platform teams must continuously manage system upgrades, handle incidents, and ensure auto-scaling works efficiently under load.
How to address it: Reduce infrastructure spend by implementing cloud cost-optimization techniques such as compute right-sizing, reserved or spot instances, tiered storage strategies (e.g., hot vs. cold), and automated data lifecycle policies to archive or delete stale data.
To further optimize costs and reduce data volume, Edge Delta’s Telemetry Pipelines allow you to filter out low-value or redundant telemetry data in-flight. They also support dynamic data tiering — enabling you to route high-priority data to analytics platforms and send lower-value data to more cost-effective destinations.
2. Security and Compliance
With sensitive data constantly in motion, telemetry data ingestion must be secure by design to prevent exposure, ensure accountability, and meet regulatory requirements.
- Encryption: Secure data in transit using TLS 1.2 or higher, and encrypt data at rest using AES-256 or comparable standards.
- Access control: Enforce least-privilege principles with role-based access control (RBAC) to mitigate insider threats and unauthorized access.
- Auditability: Maintain comprehensive logs of data access, transformations, and processing errors to support compliance reporting and forensic analysis.
How to address it: Use managed identity providers (e.g., Azure AD, Okta) to centralize access control, integrate with SIEM tools to maintain audit trails, and enforce compliance with standards like GDPR, HIPAA, and PCI-DSS through automated policy enforcement.
To further strengthen data protection and compliance, Edge Delta’s Telemetry Pipelines automatically mask sensitive fields at the point of ingestion — ensuring sensitive data never leaves the local environment. They also support routing all telemetry data to low-cost object storage (e.g., S3, GCS) for long-term retention, enabling compliance with data residency and auditability requirements.
3. Resource Management
Even the most advanced tooling is only as effective as the teams operating it.
- Skills gap: Specialized data engineering expertise is scarce, making it difficult to manage and scale complex ingestion pipelines.
- Tool proliferation: Many organizations rely on a patchwork of ingestion tools, each with unique configuration models, APIs, and maintenance overhead.
- Vendor lock-in: Relying heavily on a single vendor or cloud platform can limit agility, inflate costs, and complicate future migrations.
How to address it: Prioritize open standards and vendor-neutral tooling to reduce complexity and increase long-term flexibility. Solutions like Edge Delta’s Telemetry Pipelines natively support frameworks such as OpenTelemetry and OCSF, helping teams standardize data without reinventing the wheel. Their modular, source-agnostic architecture allows you to route telemetry data from any source to any destination — avoiding lock-in and significantly reducing tool sprawl. Combined with cross-training initiatives and loosely coupled system design, this approach empowers teams to operate more efficiently with fewer specialized resources.
Business Challenges
Business-facing challenges center on alignment, traceability, and adaptability — all of which are essential for a sustainable data strategy and long-term success.
1. Data Governance
Effective governance doesn’t slow teams down — it accelerates access to reliable insights.
- Ownership: Clear data ownership drives accountability and speeds up issue resolution.
- Metadata: Robust tagging and cataloging enhance discoverability and cross-team collaboration.
- Lineage: Visibility into data sources and transformation history is critical for compliance, auditing, and debugging.
- Quality standards: Enforce service-level agreements (SLAs) around freshness, completeness, and accuracy to ensure data reliability.
How to address it: Implement data catalogs and lineage tracking tools to promote transparency, improve trust, and make data assets easier to manage and govern across teams.
2. Integration Complexity
Integrating diverse systems is often the most technically challenging aspect of data ingestion.
- Legacy systems: Older applications may only support limited formats like flat files or batch exports.
- API constraints: Rate limits, availability issues, and evolving schemas can disrupt ingestion pipelines.
- Latency and time zones: Cross-region ingestion introduces challenges around clock drift, consistent timestamping, and performance.
How to address it: Use change data capture (CDC) to streamline ingestion from legacy systems, introduce integration platforms like Apache NiFi or Fivetran to simplify connectivity, and normalize time zones and data formats at the point of ingestion to minimize downstream friction.
Best Practices and Solutions
Addressing data ingestion challenges requires more than just tooling — it demands thoughtful design, scalable architecture, performance optimization, and built-in security. The following best practices help organizations tackle the technical, operational, and business pain points outlined earlier.
Design Principles
Effective data ingestion starts with sound architectural principles that align with business goals, scale gracefully, and remain resilient under real-world conditions. These foundations are essential for managing increasing data volumes without sacrificing performance or reliability.
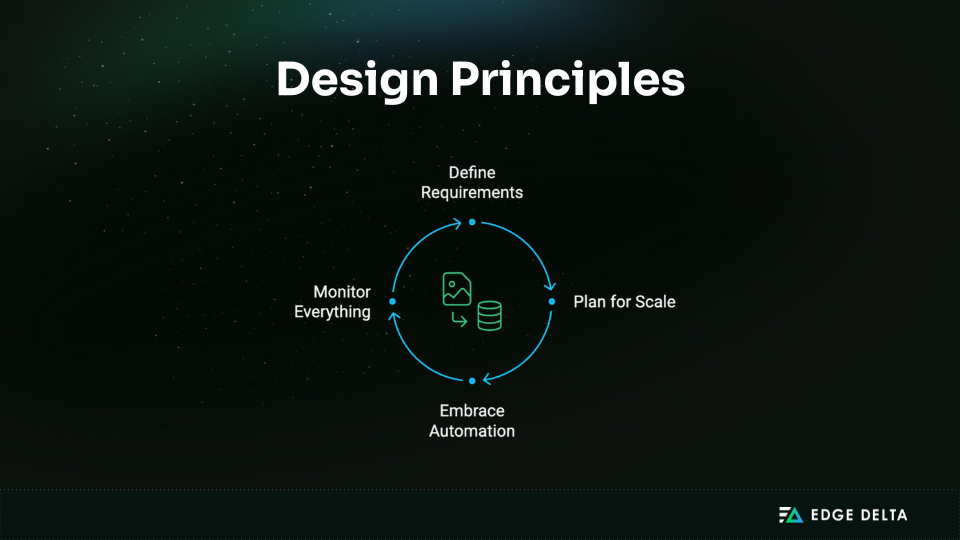
- Start with requirements: Let business needs define the architecture. Identify key use cases, capture SLAs, and engage stakeholders early to ensure that design choices support downstream analytics, compliance, and operational goals.
- Design for scale: Build pipelines that can handle 10x current volume. Prioritize distributed, horizontally scalable systems that accommodate growth without costly overhauls.
- Embrace automation: Automate deployment, validation, and failure recovery to reduce manual effort and operational risk. Adopt infrastructure as code (IaC), CI/CD pipelines, and self-healing patterns to improve stability and velocity.
- Monitor everything: Instrument every layer of the ingestion pipeline — from infrastructure to data quality. Use metrics, logs, and alerts to track system health and ensure adherence to business-level SLAs. This enables proactive troubleshooting and ongoing performance tuning.
Architecture Best Practices
A well-architected data ingestion pipeline is the backbone of scalable, resilient, and future-proof data systems. Thoughtful design enables fault tolerance, operational flexibility, and long-term maintainability.
Modular Design
Adopt a microservices-style architecture with loosely coupled components to maximize agility and fault isolation. Modular pipelines allow teams to evolve independently, swap out technologies, and scale specific components as needed. Tools like Kubernetes can streamline orchestration and scaling, though increased modularity also demands tight coordination to avoid operational complexity.
Fault Tolerance
Design for failure as a first principle. Incorporate circuit breakers, exponential backoff with retries, fallback logic, and dead letter queues to gracefully handle disruptions without losing data. Health checks and robust monitoring pipelines improve reliability, but require careful configuration to avoid false positives and alert fatigue.
Data Validation
Prevent downstream data corruption by validating early and often. Apply schema enforcement, business rule validation, and anomaly detection close to the source. Adopting a “fail fast” philosophy helps maintain data integrity, even at the cost of slight latency increases.
Version Control
Use infrastructure-as-code and Git-based workflows to manage change safely. Integrate automated testing, staging environments, and rollback procedures to ensure traceability and reduce deployment risk — especially in multi-team or complex environments.
Performance Optimization
Ingestion performance isn’t just about speed — it’s about efficiently meeting SLAs under scale. Optimize pipelines for throughput, latency, and cost-effectiveness.
- Parallel Processing: Scale horizontally by partitioning data and distributing workloads across nodes. Load balancing and resource pooling help avoid bottlenecks. Monitor key metrics such as throughput (MB/s) and end-to-end job completion time.
- Incremental Loading: Avoid unnecessary work by ingesting only what has changed. Techniques like Change Data Capture (CDC), timestamp-based filtering, and checksums reduce compute overhead and improve data freshness.
- Compression: Reduce storage and bandwidth usage by compressing data appropriately for your use case. Use formats like Parquet for analytics and Avro for streaming, with codecs like Snappy or Zstandard based on performance needs.
- Caching Strategies: Improve responsiveness by caching frequently accessed data. Use in-memory caches like Redis, edge caching via CDNs, or result caching in analytics layers. Monitor cache hit ratios and query response times for effectiveness.
Security Implementation
Security must be embedded at the architectural level — not bolted on later. A layered, proactive approach helps safeguard sensitive data and maintain compliance.
- Encryption Everywhere: Encrypt data in transit using TLS 1.3 and at rest using AES-256 or stronger. Centralize key management with solutions like AWS KMS or HashiCorp Vault to maintain control and auditability.
- Least Privilege Access: Enforce role-based access control (RBAC), use narrowly scoped service accounts, and regularly audit privileges to reduce attack surface and mitigate insider threats.
- Regular Audits and Testing: Maintain strong security posture through continuous assessments. Perform automated vulnerability scans, penetration testing, and secure code reviews to detect risks early.
- Incident Response Readiness: Develop and rehearse a formal incident response plan. Clearly define team roles, technical procedures, and communication protocols. Conduct simulation exercises to stay prepared for real-world events.
Conclusion
Data ingestion is more than a pipeline step — it’s the foundation for every downstream system, from real-time monitoring to historical analytics. Whether you’re working with batch processing, event streams, or hybrid workloads, how data enters your environment determines its utility, quality, and impact.
The right tools and methods will vary by use case, infrastructure, and team maturity. But the principles remain the same: start with clear goals, design for scalability and resilience, build in observability and security, and embrace change as a constant.
Get ingestion right, and your data becomes a strategic asset. Get it wrong, and everything downstream — from dashboards to decisions — suffers.
FAQs About Data Ingestion
How do I choose between batch and real-time ingestion?
Batch ingestion processes data at scheduled intervals and is ideal for reports and non-urgent analytics. Real-time ingestion delivers data continuously for immediate insights, making it well-suited for use cases like fraud detection or live tracking. Choose based on how quickly your data needs to be actionable. Micro-batching can offer a balanced compromise between latency and resource efficiency.
What matters most when choosing ingestion tools?
Prioritize compatibility with your data sources and destinations. Look for support of common formats (e.g., JSON, CSV), built-in connectors, encryption capabilities, and scalability. Consider usability, total cost of ownership, and alignment with your team’s expertise.
What’s the difference between data ingestion and ETL?
Data ingestion focuses on reliably moving raw data into storage without altering it. ETL (Extract, Transform, Load) involves cleaning, transforming, and preparing data specifically for analysis. Ingestion emphasizes data transfer, while ETL emphasizes data preparation.
How can I monitor ingestion pipelines effectively?
Monitor key metrics such as throughput, latency, and error rates. Use observability platforms like Prometheus or Datadog to enable real-time alerting. Incorporate comprehensive logging, distributed tracing, and automated retry mechanisms to ensure stability and SLA adherence.
Why do ingestion pipelines fail?
Common causes include schema changes, API disruptions, and inadequate planning. Organizational issues such as unclear responsibilities also contribute. Mitigate failures by enforcing data contracts, implementing robust error handling, and clearly assigning ownership.
Sources

