In today’s fast-paced IT and software development landscape, observability has emerged as a crucial practice for maintaining system health and performance. Observability allows teams to identify and resolve issues in modern distributed applications before they escalate into major problems. Observability aggregates, correlates, and analyzes performance data from distributed applications, hardware, and networks using software tools and practices.
As cloud-native environments become more complex, observability is crucial for identifying failures and anomalies. However, despite its significance, several myths and misconceptions about observability persist, leading to confusion about its capabilities and applications. By understanding the reality of observability, teams can leverage their full potential to enhance system performance, increase efficiency, and reduce downtime.
Want Faster, Safer, More Actionable Root Cause Analysis?
With Edge Delta’s out-of-the-box AI agent for SRE, teams get clearer context on the alerts that matter and more confidence in the overall health and performance of their apps.
Learn MoreThis article aims to debunk the most common observability myths and explore their impact on modern IT and software development practices.
|
Key Takeaways |
|
|
Understanding Observability Myths
Observability myths are misconceptions or misunderstandings about the concepts, practices, and tools associated with observability. These myths can lead to misunderstandings about observability and how it works, often resulting in flawed practices and strategies.
Observability myths significantly influence IT practices and strategies, often leading to suboptimal implementation and management. Misconceptions can cause teams to:
- Invest in the wrong tools
- Overlook critical system health insights
- Face unexpected costs and inefficiencies
Understanding and debunking these myths is crucial for ensuring organizations effectively monitor, diagnose, and improve their systems. Below is a table summarizing the impact of observability myths on organizations:
|
Myth |
Potential Consequence |
|
Observability is just monitoring |
Limited insight into system health |
|
More data means better observability |
Overwhelmed with irrelevant information |
|
Observability tools are too expensive |
Missed opportunities for cost-effective solutions |
|
Observability can replace all existing tools |
Overreliance on a single solution, missing specialized insights |
|
Observability is only for large enterprises |
Small and medium businesses may miss out on benefits |
Debunking Common Observability Myths
Observability is an indispensable solution for DevOps, SRE, Platform, ITOps, and Developer teams. It offers deep visibility into modern distributed systems for faster, automated problem identification, and resolution. Yet, as powerful as observability is, several misconceptions and outdated practices cloud its enormous value.
Here are five common myths and facts to help you distinguish between fiction and reality.

Myth 1: Observability Is Just Another Term for Monitoring
One of the most common misconceptions about observability is that it is the same as monitoring. This myth stems from the overlapping goals of both practices, ensuring the health and performance of systems.
However, equating observability with monitoring overlooks the distinct purposes, methodologies, and benefits each offers. This misunderstanding can lead to underutilized capabilities in modern system management and an inability to fully diagnose and address complex issues.
Truth: Monitoring and observability are related but distinct concepts, each serving different purposes in system management.
While monitoring certainly contributes to observability, it is not the entire picture. Monitoring refers to collecting, analyzing, and using data to track a system’s performance and behavior.
Monitoring focuses on specific metrics, such as:
- CPU usage
- Memory consumption
- Error rates
Typically, monitoring involves setting thresholds to trigger alerts when the mentioned metrics deviate from expected values. Monitoring ensures a system meets its objectives and provides the necessary information to guide management decisions.
Observability, on the other hand, goes beyond this. It involves using this data to gain deep insights into the system’s internal workings. Observability involves analyzing logs, metrics, and traces to understand a system’s internal state, through monitoring, log and metric analysis, anomaly detection, and much more.
Providing a comprehensive view of the system, observability allows teams to identify and resolve underlying issues by understanding what is happening and why. Observability is particularly valuable in complex, distributed systems and multi-cloud environments, where it helps teams analyze events in context and identify the root causes of issues.
Here’s a table outlining the key distinctions between monitoring and observability:
|
Aspect |
Monitoring |
Observability |
|
Purpose |
Tracking predefined metrics and logs to ensure system health |
Understanding the system’s internal state through data analysis |
|
Scope |
Reactive, detecting, and alerting on known issues |
Proactive, diagnosing unknown issues |
|
Data Usage |
Uses pre-selected metrics and logs, often viewed in isolation |
Integrates logs, metrics, and traces for holistic insights |
|
Problem Resolution |
Identifies the existence of problems |
Facilitates root cause analysis and resolution |
|
Focus |
Specific metrics and thresholds |
Overall system behavior and context |
|
Complexity Handling |
Basic monitoring setups for known conditions |
Handles complex, distributed environments |
|
Alerting |
Alerts on predefined conditions and thresholds |
Provides contextual information to understand issues |
|
Tools |
Tools like Nagios, Zabbix, and CloudWatch |
Tools like OpenTelemetry, Jaeger, and Honeycomb |
|
Implementation |
Set up specific alerts and dashboards |
Continuous data collection and analysis |
|
Outcome |
Ensures system components are running as expected |
Offers insights for improving system reliability |
|
Approach |
Predetermined checks and balances |
Exploratory and investigative analysis |
Myth 2: More Data Equals Better Observability
It’s a common misconception that collecting more data will automatically enhance observability. However, adding data without a strategy can cause observability mistakes, information overload, and difficulty extracting meaningful insights. Data alone is not a silver bullet, as too much data can become a liability when it needs to be securely stored and managed at scale.
Truth: The key to effective observability is gathering relevant and actionable data.
High-quality observability involves understanding what data is critical for diagnosing issues, monitoring performance, and improving system reliability. This means focusing on data that provides clear insights into system behavior, enables quick identification of anomalies, and supports efficient troubleshooting. Organizations can achieve a more accurate and insightful view of their systems by prioritizing relevant data over sheer volume.
Relevant data helps diagnose issues accurately, understand system behavior, and make informed decisions. Actionable data provides clear insights that can be used to improve system performance and reliability.
Below is a graph demonstrating the relationship between data volume and insight quality:
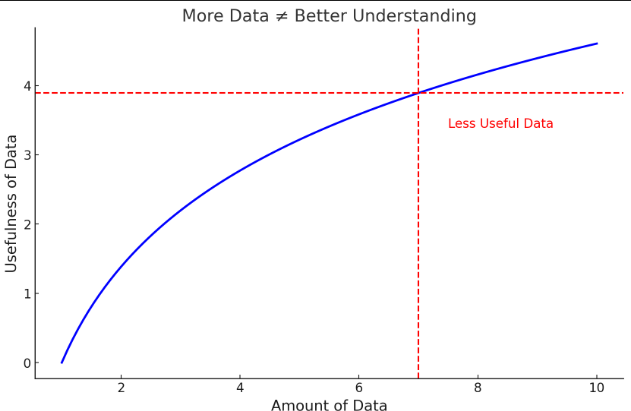
Collecting more data helps improve understanding up to a certain point. Beyond this point, additional data offers diminishing returns, adding more complexity without significantly enhancing insights. Focus on actionable, relevant data to maximize the quality of insights and streamline your observability efforts.
Myth 3: Observability Tools Are Too Expensive
Another common misconception is that observability tools are prohibitively expensive. This belief can deter organizations from implementing essential observability practices, as it assumes high costs are unavoidable.
However, this perspective overlooks the broader range of cost-effective solutions and the long-term benefits of improved system reliability and performance.
Truth: Affordable and even open-source observability tools can fit various budgets and needs.
Observability does not have to cost a fortune because there are various pricing models from which to choose. Observability tool vendors recognize the need to accommodate businesses with varying budgets. Many tools do not adhere strictly to a consumption-based pricing model, instead offering different options for customers.
For example, some tools provide adaptable pricing alternatives, including structured subscription plans. These plans allow enterprises to anticipate costs based on their chosen package, simplifying the budgeting process for observability initiatives and avoiding unexpected charges.
Though some tools might try and complexify cost calculations, tools like Edge Delta are completely price transparent and offer competitive rates for their observability and pipeline solutions. What’s more, many open-source solutions exist, enabling teams to save on retention and ingestion costs and build observability solutions with public tools.
Regardless of the chosen solution, it is crucial to understand the total cost of ownership, which includes storage, quarterly charges, ingestion, and developer involvement (i.e., how much time and resources developers spend).
When designing an observability solution, consider the following:
- Fixed Subscription Plans
Many observability platforms offer fixed subscription plans that enable businesses to predict costs upfront. These plans typically provide various tiers or packages tailored to the organization’s needs. Companies can select the most suitable plan based on data volume, number of users, and required features. For example, IBM Instana’s pricing model is structured this way.
- Democratized Observability
The democratization of observability is vital for modern organizations, allowing employees to gain comprehensive insights into systems and operations. Selecting a vendor that offers free access for additional users can promote collaboration, knowledge sharing, and inclusivity without extra costs.
- Open-Source Solutions
Open-source tools like Prometheus, Grafana, and Elasticsearch offer robust observability capabilities without direct license costs. While they require substantial effort and technical expertise to set up and manage, they can be a highly cost-effective solution.
- Scalable Pricing Models
Cloud-based observability solutions often provide scalable pricing models, enabling businesses to start with a smaller budget and expand their observability infrastructure as needs grow. Paying for resources as used allows organizations to optimize costs while ensuring sufficient coverage.
- Customization and Flexibility
Some observability platforms allow customization based on specific organizational needs. By focusing on critical areas or services, businesses can reduce unnecessary costs.
By exploring these options, businesses can implement effective observability solutions without facing prohibitive expenses. The key is to evaluate the tool’s value, understand total costs, and choose the pricing model that best aligns with the organization’s needs and budget.
Here’s a table summary of popular observability tools, along with their pricing and features:
|
Tool |
Type |
Features |
|
Prometheus |
Open Source |
Monitoring and alerting toolkit |
|
Grafana |
Open Source |
Data visualization and dashboarding |
|
Datadog |
Paid |
Cloud monitoring and security platform |
|
ELK Stack |
Open Source |
Log management and analytics |
|
Edge Delta |
Paid |
Automated observability, anomaly detection, and analytics |
|
New Relic |
Paid |
Full-stack observability, application performance monitoring (APM) |
|
Splunk |
Paid |
Data analysis and monitoring, log management |
|
Zabbix |
Open Source |
Network monitoring, server monitoring |
Myth 4: Observability Is Only for Large Enterprises
Observability is often misunderstood as a practice reserved for large enterprises with vast, complex systems. This myth can deter smaller organizations from adopting observability practices, preventing them from reaping the significant benefits they offer.
Truth: Observability is beneficial for organizations of all sizes.
Whether you run a small business, a medium enterprise, or a large corporation, implementing observability can help you gain insights into your system’s behavior. It can aid in the identification of performance bottlenecks and the effective resolution of issues. Check out this table showing how observability benefits any size company:
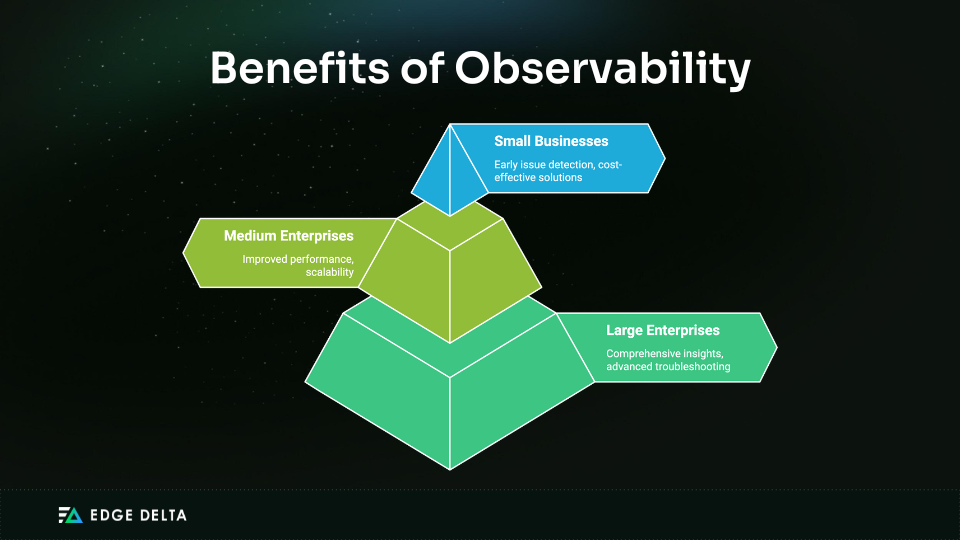
Data quality issues do not always correlate with team size or company headcount. For instance, a small company with a single-person data team might have a more pressing need for observability if data fuels its operations.
Observability helps small teams maximize productivity by providing metadata on data asset usage, enabling effective work prioritization. Larger teams, on the other hand, benefit from end-to-end visibility into their telemetry pipelines, aiding in the onboarding and retention of senior data engineers.
- Observability for Small Businesses
Small businesses frequently run on tight resources, making it crucial to detect and resolve issues early to minimize downtime and avoid costly disruptions. Basic logging and metrics can help small teams monitor user interactions, request and response times, and error rates.
These observability practices improve the user experience and enhance the application’s success. Early issue detection and cost-effective solutions are critical for maintaining application reliability and performance.
- Observability for Medium Enterprises
As medium enterprises grow, their systems become more complex, requiring scalable solutions to maintain performance and manage increasing loads. Observability improves performance and scalability by providing insights into system behavior.
These insights enable teams to identify and address bottlenecks proactively. Ensuring applications can grow without compromising the user experience or reliability is crucial for these organizations.
- Observability for Large Enterprises
Large enterprises benefit from comprehensive insights and advanced troubleshooting capabilities offered by observability tools. These organizations often deal with complex, distributed systems where the interactions and dependencies between services can be intricate.
Observability allows tracing requests across services, measuring latency, and pinpointing performance issues, ensuring smooth operation and minimal downtime. Advanced troubleshooting capabilities are essential for maintaining high performance and reliability standards.
Myth 5: Observability Solves All Problems Instantly
Implementing observability will instantly resolve all system issues. This myth stems from the misconception that observability tools are a magic bullet, offering immediate solutions to all operational challenges.
Truth: Achieving effective observability requires continuous improvement and fine-tuning.
While observability provides critical insights into your systems, it is the starting point. It allows you to monitor, diagnose, and understand your applications’ inner workings but does not automatically fix problems.
Continuous improvement is essential to maintaining and enhancing observability. This improvement involves regular updates, refining monitoring strategies, adjusting alerting mechanisms, and analyzing new metrics. Simply implementing observability practices does not guarantee immediate problem resolution.
For example, integrating observability and data pipelines into your DevOps cycle with shift-left principles allows for early detection and resolution of issues. This proactive approach helps mitigate risks before they escalate, leading to more stable and reliable applications.
Here’s a graph showing observability maturity over time:
Best Practices for Overcoming Observability Myths
Effective observability is key to maintaining the health and performance of modern systems. You can gain deeper insights and quickly resolve issues by following best practices. Below are some essential strategies for overcoming observability myths:
1. Education and Training
Educating and training your teams is essential for overcoming observability myths. This process involves demystifying complex concepts and tools, enabling team members to understand the value and importance of observability in their daily work.
Proper education and training foster a proactive culture, allowing teams to identify potential issues before they become serious problems. It’s crucial to ensure that everyone in your organization comprehends the significance of observability. To effectively educate your teams, consider the following practices:
- Schedule Regular Training
Plan monthly or quarterly training focusing on different aspects of observability. Topics can range from the fundamentals to specific tools and advanced techniques.
- Hands-on Training
Provide hands-on training sessions where team members can experiment with observability tools in a controlled environment. This practice helps bridge the gap between theoretical knowledge and real-world application.
- Guest Speakers and Experts
Invite experts in the field of observability to share their insights and experiences. Experts can provide new perspectives and reinforce the importance of observability.
- Ongoing Education Programs
Develop a series of continuous engagements and ongoing product education. As your team’s demands grow, ensuring that everyone stays updated with the latest practices and tools becomes crucial.
2. Collaboration and Communication
Promoting collaboration and communication among development, operations, and business teams is another best practice for dispelling observability myths. Observability efforts can become siloed without collaboration, leading to incomplete insights and suboptimal system performance.
Collaboration is essential for observability to ensure that all relevant perspectives and expertise are considered when monitoring and improving system performance. Development teams focus on creating and maintaining code, while operations teams manage the infrastructure and deployment processes. The business teams identify opportunities for growth and value creation.
When teams work together, they can align their goals, strategies, and actions to ensure that observability practices meet the needs of the entire organization. This collaboration ensures that observability insights drive business value, improve customer experiences, and optimize operational efficiency.
Best practices to enhance observability through collaboration and communication include the following:
|
Best Practice |
Description |
|
Establish Cross-Functional Teams |
By forming cross-functional teams, organizations can break down silos and ensure that observability practices are holistic and comprehensive. Team members’ diverse skills and perspectives enhance system behavior and performance understanding. |
|
Communication is Key |
Effective communication enables collaboration by sharing information, providing feedback, and solving problems. Teams should communicate frequently and transparently using appropriate channels, tools, and formats to keep everyone updated, informed, and engaged. Frequent, transparent updates prevent silos and ensure observability aligns with organizational goals. |
|
Foster Collaboration and Knowledge Sharing |
Cross-functional collaboration helps stakeholders understand systems better and make informed decisions. When development, operations, and business teams work together, they can spot patterns, detect issues early, and resolve them. Collaboration between these teams builds shared responsibility for better reliability and customer satisfaction. |
3. Focus on Actionable Insights
Emphasize the importance of focusing on actionable insights rather than data volume. It’s a common misconception that more data automatically leads to better observability. In reality, the quality and relevance of the data are far more important than the sheer quantity.
Here are some key points to consider:
- Quality Over Quantity: Prioritize data that provides meaningful context over large volumes of raw data.
- Noise Reduction: Implement tools that intelligently filter and reduce noise in your data streams.
- Anomaly Detection: Utilize machine learning and advanced analytics to detect anomalies and surface critical issues.
- Contextual Relevance: Ensure the data collected is relevant to your specific observability goals and use cases.
- Real-Time Processing: Adopt solutions that offer real-time processing and insights to address issues promptly.
Here are some best practices for focusing on actionable insights.
- Use Data Analysis Tools
Use data analysis tools to filter out noise and highlight important information. For instance, machine learning algorithms can identify data patterns and anomalies, letting you focus on urgent issues.
Edge Delta and other tools make real-time analysis and intelligent alerting possible, ensuring you don’t become overwhelmed by data but rather receive informed, valuable insights.
- Set Clear Objectives
Define specific goals for what you need to monitor and why. Setting clear objectives ensures that the data you collect is aligned with your business and operational objectives.
- Centralized Logging and Monitoring
Consolidate data from various sources using centralized platforms for logging and monitoring. Centralized logging and monitoring help create a cohesive view and reduce the chances of missing critical information.
- Automated Alerting
Configure automated alerts for predefined thresholds and anomalies. Ensure that alerts are actionable and provide context to avoid alert fatigue.
- Dashboards and Visualization
Utilize dashboards to visualize key metrics and trends. Interactive dashboards help quickly identify issues and understand the impact of changes.
- Regular Audits and Reviews
Conduct regular audits of your observability setup to ensure it meets your needs. Adjust data collection and monitoring strategies based on evolving requirements.
- Collaboration and Communication
Create a culture of collaboration among development, operations, and business teams. Sharing insights and fostering open communication can help identify actionable insights more effectively.
- Root Cause Analysis
Implement root cause analysis (RCA) processes to investigate and understand the underlying causes of incidents. This process helps prevent recurrence and improve overall system reliability.
- Prioritize Critical Metrics
Focus on key performance indicators (KPIs) and service-level objectives (SLOs) critical to your business. This approach will help you maintain a targeted approach to observability.
- Leverage AIOps
Integrate Artificial Intelligence for IT Operations (AIOps) to enhance data analysis, anomaly detection, and predictive insights. AIOps can help proactively manage issues before they impact users.
- Document Insights and Actions
Document insights gained and actions taken. The knowledge base can be used for future incidents and continuous improvement.
4. Adopting a Gradual Approach
A gradual approach to adopting observability practices can significantly enhance the effectiveness and acceptance of new organizational tools and methodologies. Implementing observability incrementally allows teams to manage new systems’ complexity and learning curve, ensuring a smoother transition and greater long-term success.
Gradually adopting observability practices allows for a smoother transition, enabling teams to manage complexity and improve system reliability without overwhelming resources. This approach provides several benefits:
- Reduced Disruption: Introducing observability gradually minimizes disruptions to existing workflows and systems, allowing teams to maintain productivity while adapting to new practices.
- Easier Learning Curve: A phased approach allows team members to gradually build their expertise, reducing the overwhelming nature of adopting a comprehensive observability strategy.
- Improved Buy-in: Incremental changes are more likely to gain acceptance from stakeholders, as they can see the immediate benefits without the perceived risk of a significant overhaul.
- Scalability: Starting small and expanding observability practices over time ensures the system can scale according to the organization’s growing needs without strain.
- Early Feedback: Gradual implementation provides opportunities to gather feedback at each stage, allowing for adjustments and improvements before full-scale adoption.
Here are some steps you can take to gradually adopt observability, ensuring a well-structured and efficient integration process:
- Identify Core Metrics
Begin by identifying the most critical metrics that impact your system’s performance and reliability. These include CPU usage, memory consumption, disk I/O, and network latency.
Here are some ways to help you identify core metrics:
|
- Set Up Basic Monitoring
Start by determining which metrics are crucial for monitoring your system’s health and performance. To set up essential monitoring, consider the following:
- Assess System Components: Conduct an evaluation to pinpoint mission-critical components and services.
- Select Key Performance Indicators (KPIs): Identify essential metrics like CPU usage, memory consumption, disk I/O, and network latency. Also include application-specific metrics such as request rates, error rates, and response times.
- Prioritize Metrics: Rank metrics based on their impact on user experience and system stability, focusing on the highest-priority metrics first.
- Establish Baselines and Thresholds
Establish baselines for your core metrics to define average performance. Set up thresholds and alerts for deviations that could indicate potential issues. Consider the following to establish baselines and thresholds:
- Collect Historical Data: Gather historical data on your identified metrics over sufficient time to understand normal behavior and performance trends.
- Define Baselines: Analyze data to establish typical performance levels under normal operating conditions.
- Set Thresholds: Determine acceptable performance limits and configure alerts for deviations. For example, set a CPU usage threshold of 80% to trigger alerts when usage exceeds this value.
- Regularly Review and Adjust: Periodically review and update baselines and thresholds based on evolving system behavior and performance trends to ensure your observability setup remains effective.
- Gradual Expansion
Once the essential observability metrics are under control, start expanding to more advanced observability practices, such as:
- Logs: Implement structured logging to capture detailed events and errors within your applications.
- Traces: Introduce distributed tracing to understand the flow and performance of requests through your system.
- Advanced Metrics: Track higher-level metrics such as request rates, error rates, and service response times.
- Integrate Tools
Choose observability tools that can integrate, providing a cohesive view of your system. Tools like Grafana for visualization, Prometheus for metrics, and Jaeger for tracing can be integrated to offer a comprehensive observability solution.
- Automate and Optimize
Automating data collection and alerting processes is essential as your observability practices mature. Utilizing AI and machine learning can help identify patterns and predict issues before they escalate.
Here’s how to approach automation and optimization:
- Automated Data Collection: Use tools like Prometheus to automate log, metric, and trace collection, integrating seamlessly with your infrastructure to reduce manual intervention.
- Automated Alerting: Configure real-time alerts with services like PagerDuty or Opsgenie based on predefined thresholds. Use AI and machine learning to analyze historical data, identify patterns, and predict future issues for dynamic alerting.
- Optimization: Implement data retention policies to manage data volume efficiently. Use time-series databases for observability data storage and AI-driven tools to optimize real-time resource allocation.
- Continuous Feedback Loop
Establish a feedback loop where insights gained from observability practices are used to continually refine and improve system performance and reliability. Here’s a list of ways to practice the continuous feedback loop:
- Data Analysis: Use real-time dashboards and post-mortem analyses to gain insights.
- Feedback Integration: Incorporate insights into development and operational processes using tools like Jira.
- Automation: Implement feedback-driven changes using Infrastructure as Code (IaC) tools like Terraform and Ansible.
- Iteration: Regularly review and update observability practices to adapt to evolving system needs.
- Document and Train
To ensure team familiarity with the tools and practices, document your observability setup and train them regularly. To attain complete documentation and proper training, consider the following:
- Setup Guides: Provide detailed guides with step-by-step instructions and troubleshooting tips.
- Best Practices: Document best practices for data collection, alerting, and incident response.
- Workshops: Conduct regular workshops on new tools and best practices.
- Cross-Training: Encourage cross-training to gain a broad understanding across roles.
- Knowledge Base: Maintain a centralized repository for all documentation and training materials.
Conclusion
Understanding and dispelling common myths about observability is crucial for harnessing its full potential. Observability goes beyond simple monitoring. It involves more than just logs and requires a strategic approach tailored to your specific system. Understanding these aspects can significantly enhance your system’s reliability and performance.
Remember, observability is an ongoing journey of improvement and adaptation. Embrace its complexities, invest in the right tools and practices, and you’ll be well-equipped to effectively navigate and optimize your system’s operations.
FAQ for Most Common Myths About Observability
What is the objective of observability?
Observability aims to gain insight into what is happening across various environments and technologies based on their outputs. This understanding helps identify and address issues promptly, ensuring systems remain efficient and reliable, thereby maintaining customer satisfaction.
What problem does observability solve?
Software engineering teams use observability to understand software systems’ health, performance, and status, including when and why errors occur. By looking at a system’s outputs, such as events, metrics, logs, and traces, engineers can determine how well that system is performing.
What can observability achieve that monitoring cannot accomplish alone?
Monitoring systems can discover anomalies or unusual behavior in system state and performance. Observability lets you investigate anomalies caused by hundreds of service components.
Sources: